 播面
播面 浏览器是如何解析 HTML 的?(DOM 树构建过程)
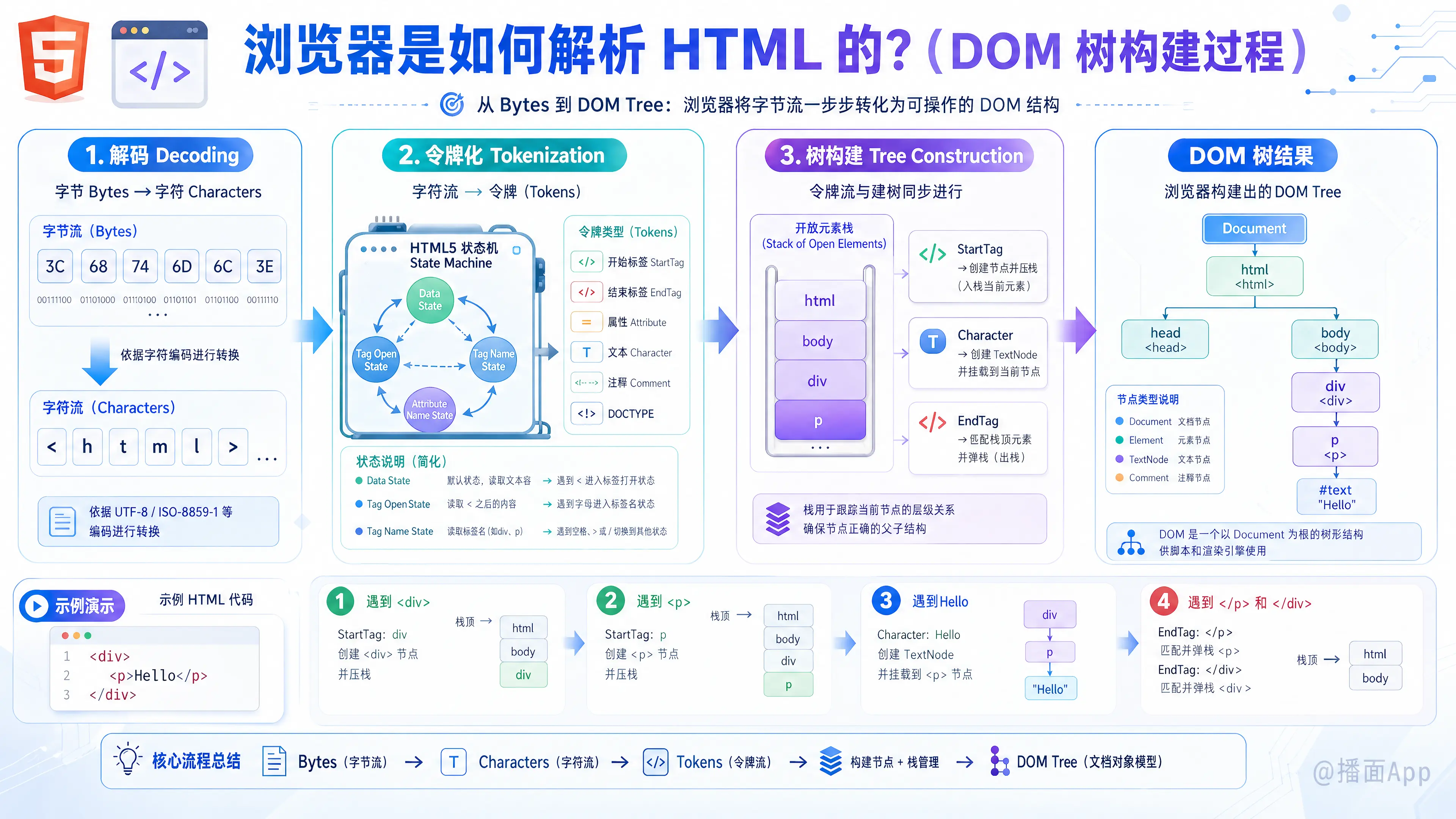
浏览器的 HTML 解析和 DOM 树构建是一个非常复杂但高度优化的过程。简单来说,这是将网络传输的字节流(Bytes)转换为浏览器可以理解的对象树(DOM Tree)的过程。
这个过程主要遵循 HTML 5 标准,可以分为四个主要步骤:
- 解码 (Decoding):字节 字符
- 令牌化 (Tokenization):字符 令牌 (Tokens)
- 树构建 (Tree Construction):令牌 节点 (Nodes) DOM 树
以下是详细的深度解析:
1. 解码 (Decoding)
浏览器从网络或磁盘读取 HTML 文件的原始字节(Bytes)(例如 3C 68 74 6D 6C 3E)。
浏览器根据文件的指定编码(如 UTF-8、ISO-8859-1 等)将这些字节转换成字符(Characters)(例如 <html>)。
2. 令牌化 (Tokenization) —— 词法分析
这是解析的核心步骤之一。浏览器的 HTML 解析器会将字符流转换为不同的令牌(Tokens)。HTML 标准定义了一个复杂的状态机(State Machine)来处理这个过程。
什么是令牌? 令牌是 HTML 的最小语义单元,例如:
- 开始标签令牌(StartTag:
<div>) - 结束标签令牌(EndTag:
</div>) - 属性令牌(Attribute:
class="container") - 文本令牌(Character:
Hello World) - 注释令牌(Comment)
- DOCTYPE 令牌
- 开始标签令牌(StartTag:
状态机的工作方式:
解析器每次读取一个字符,根据当前状态决定下一步操作。- 数据状态 (Data State):这是初始状态。如果遇到
<,状态变为“标签打开状态”。 - 标签打开状态 (Tag Open State):如果下一个字符是
a-z,状态变为“标签名称状态”;如果是/,变为“结束标签打开状态”。 - 标签名称状态 (Tag Name State):持续读取字符直到遇到空格(准备读取属性)或
>(标签结束)。
- 数据状态 (Data State):这是初始状态。如果遇到
产出: 一系列的令牌流。
3. 树构建 (Tree Construction) —— 语法分析
在令牌化进行的同时,树构建过程也在同步进行。解析器并不是等所有令牌都生成了才开始建树,而是一边生成令牌,一边构建 DOM 树。
这一步主要依赖一个核心数据结构:开放元素栈 (Stack of Open Elements)。
流程详解:
- 创建根节点:解析器首先创建
Document对象。 - 处理令牌:
- 遇到开始标签 (StartTag):
- 创建一个对应的 DOM 节点(例如
HTMLDivElement)。 - 将该节点添加到当前栈顶元素(父节点)的子节点列表中。
- 将该节点压入开放元素栈。
- 创建一个对应的 DOM 节点(例如
- 遇到文本 (Character):
- 创建一个文本节点(TextNode)。
- 将其挂载到当前栈顶元素的下面。
- 遇到结束标签 (EndTag):
- 检查栈顶元素是否与该结束标签匹配。
- 如果匹配,将该元素从栈中弹出 (Pop)。此时该元素解析完成。
- 遇到开始标签 (StartTag):
示例演示:
假设 HTML 为:
<div>
<p>Hello</p>
</div>- 遇到
<div>令牌 创建div节点 挂载到 Documentdiv入栈。 - 遇到
<p>令牌 创建p节点 挂载到div(栈顶)p入栈。 - 遇到
Hello文本 创建文本节点 挂载到p(栈顶)。 - 遇到
</p>令牌p出栈。 - 遇到
</div>令牌div出栈。
4. 特殊情况与挑战
虽然上述流程看起来很线性,但实际情况要复杂得多:
A. JavaScript 的阻塞 (Blocking)
这是 HTML 解析中最大的“路障”。
- 当解析器遇到
<script>标签时,HTML 解析会暂停。 - 控制权移交给 JavaScript 引擎(如 V8)。
- 原因:JS 可能会通过
document.write()修改 HTML 结构。如果在 JS 执行前继续解析 HTML,生成的 DOM 树可能是错的。 - 优化:使用
async或defer属性可以让 JS 异步加载/执行,不阻塞 DOM 构建。
B. 预加载扫描器 (Preload Scanner)
为了缓解 JS 阻塞带来的性能问题,现代浏览器有一个预加载扫描器。
- 当主解析器被 JS 阻塞时,这个轻量级的扫描器会继续快速向后“偷看”HTML。
- 它不会构建 DOM,只会寻找需要下载的资源(CSS, JS, 图片),并提前发起网络请求。
C. 容错机制 (Error Tolerance)
HTML 是一种非常宽容的语言。即使你写了错误的 HTML,浏览器也不会报错崩溃,而是尝试“纠错”。
- 缺少闭合标签:如果写了
<p>1 <p>2,浏览器会自动补全闭合标签,解析为<p>1</p><p>2</p>。 - 错误的嵌套:如果在
p标签里放了div(p只能包含行内元素),浏览器会将div移出p标签,或者自动闭合p标签。
D. CSS 的影响
虽然 CSS 不直接参与 DOM 树的构建,但它会阻塞 渲染树 (Render Tree) 的生成。
- 更重要的是,如果
<script>标签在 CSS 后面,浏览器通常会等待 CSSOM 构建完成才执行 JS(因为 JS 可能会查询样式信息)。这间接地导致了 DOM 解析的延迟。
总结:DOM 生成流程图
网络字节流 (Bytes)
↓
[解码器] -> 字符流 (Characters)
↓
[令牌化器 (Tokenizer)] -> 令牌流 (Tokens) <StartTag, EndTag...>
↓
[树构建器 (Tree Builder)] <-> [开放元素栈]
↓
├── 遇到 <script>: 暂停构建,执行 JS (除非 defer/async)
├── 遇到 CSS: 继续构建 DOM,但阻塞渲染
└── 自动纠错 (处理未闭合标签等)
↓
DOM 树 (DOM Tree)最终,当解析器处理完所有标记后,文档状态变为 interactive,随后触发 DOMContentLoaded 事件,标志着 DOM 树构建完成。