 播面
播面 Znode 存储数据的大小有限制吗?为什么不建议在 ZK 中存储大量数据?
这是一个非常经典且重要的 ZooKeeper(以下简称 ZK)架构设计问题。
简单直接的回答是:有,默认限制是 1MB。
虽然可以通过配置修改这个限制,但极度不建议这样做。下面我将详细解释具体的限制参数,以及为什么 ZK 不适合存储大量数据。
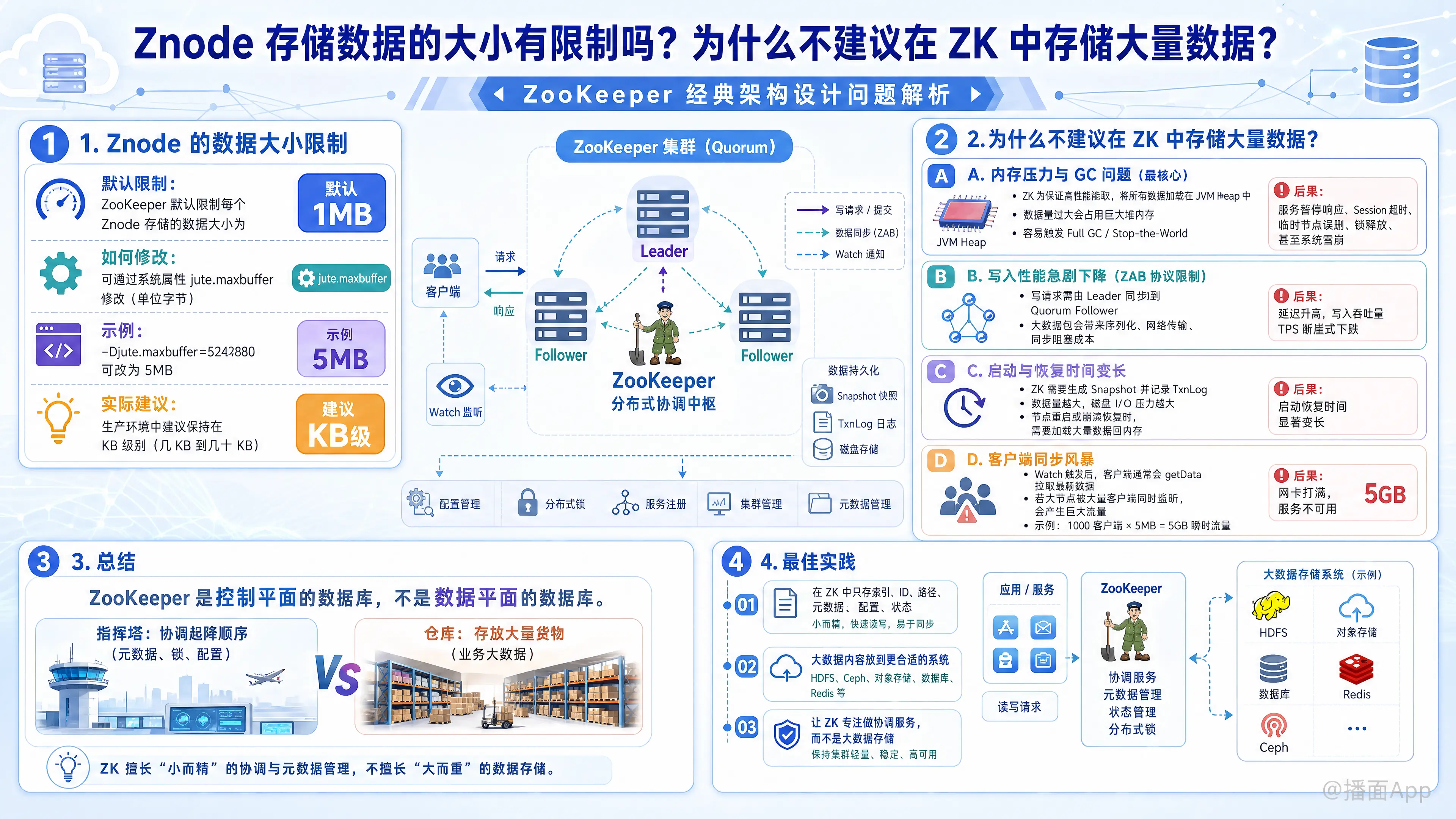
1. Znode 的数据大小限制
- 默认限制: ZooKeeper 默认限制每个 Znode 存储的数据大小为 1MB。
- 如何修改: 可以通过系统属性
jute.maxbuffer来修改这个限制(单位是字节)。例如,在启动脚本中添加-Djute.maxbuffer=5242880可以将其改为 5MB。 - 实际建议: 尽管可以修改,但在生产环境中,建议 Znode 存储的数据量保持在 KB 级别(通常几 KB 到几十 KB)。
2. 为什么不建议在 ZK 中存储大量数据?
ZooKeeper 的设计目标是高可用的分布式协调服务(存元数据、配置信息、锁状态),而不是分布式存储系统(如 HDFS、Ceph)或缓存系统(如 Redis)。
如果在 ZK 中存储大量数据(例如单个 Znode 超过 1MB,或者总数据量过大),会引发以下严重问题:
A. 内存压力与 GC 问题 (最核心的原因)
- 全内存运行: ZK 为了保证高性能的读取,将所有数据加载在内存(JVM Heap)中。如果你存储了几个 G 的数据,就需要极大的堆内存。
- Garbage Collection (GC) 停顿: Java 的垃圾回收机制在处理大堆内存或大对象时,容易触发 "Stop-the-World" 的 Full GC。
- 后果: 当发生长时间的 GC 停顿(比如超过几秒),ZK 服务端会暂停响应。客户端会认为连接断开,导致 Session 超时,临时节点(Ephemeral Node)被误删,进而触发不必要的 Leader 选举或分布式锁释放,导致整个分布式系统发生雪崩。
B. 写入性能急剧下降 (ZAB 协议限制)
- 原子广播机制: ZK 的写操作需要通过 Leader 节点同步给所有 Follower 节点(ZAB 协议)。
- 同步阻塞: 如果一个写请求包含 10MB 的数据,Leader 需要将这 10MB 数据序列化并通过网络发送给 Quorum(半数以上)的 Follower。
- 后果: 网络传输大包会占用大量带宽,增加延迟。在同步完成前,该请求会阻塞后续的请求,导致 ZK 的写入吞吐量(TPS)断崖式下跌。
C. 启动与恢复时间变长
- 快照与事务日志: ZK 会定期将内存数据 Dump 到磁盘生成快照(Snapshot),并记录事务日志(TxnLog)。
- 后果: 如果数据量很大,磁盘 I/O 会成为瓶颈。当 ZK 节点重启或崩溃恢复时,需要从磁盘加载大量数据到内存,这会导致启动时间变得非常长。在恢复期间,该节点无法对外提供服务。
D. 客户端同步风暴
- GetData 通信: 当客户端监听(Watch)某个节点时,如果该节点数据更新,ZK 会通知客户端。客户端通常会随即调用
getData拉取最新数据。 - 后果: 如果数据很大(比如 5MB),且有 1000 个客户端同时监听这个节点,一旦数据变更,瞬间会有 1000 * 5MB = 5GB 的数据流量冲击 ZK 服务器网卡,直接导致网卡打满,服务不可用。
3. 总结与最佳实践
ZooKeeper 是“控制平面的数据库”,而不是“数据平面的数据库”。
打个比方:ZooKeeper 就像是机场的指挥塔,它负责协调飞机的起降顺序(元数据、锁、配置);它不是货运仓库,你不应该把货物(大量业务数据)塞进指挥塔里。
正确的做法:
- 存索引/路径: 在 ZK 中只存储数据的索引、ID 或者存放路径(例如 "hdfs://data/file_1")。
- 存真实数据: 将真实的大量数据存储在 Redis、MySQL、HDFS、S3 或 MongoDB 中。
- 保持轻量: 尽量保持 Znode 数据在 10KB 以下,以获得最佳性能。