 播面
播面 为什么 ZooKeeper 集群节点数通常建议为奇数?
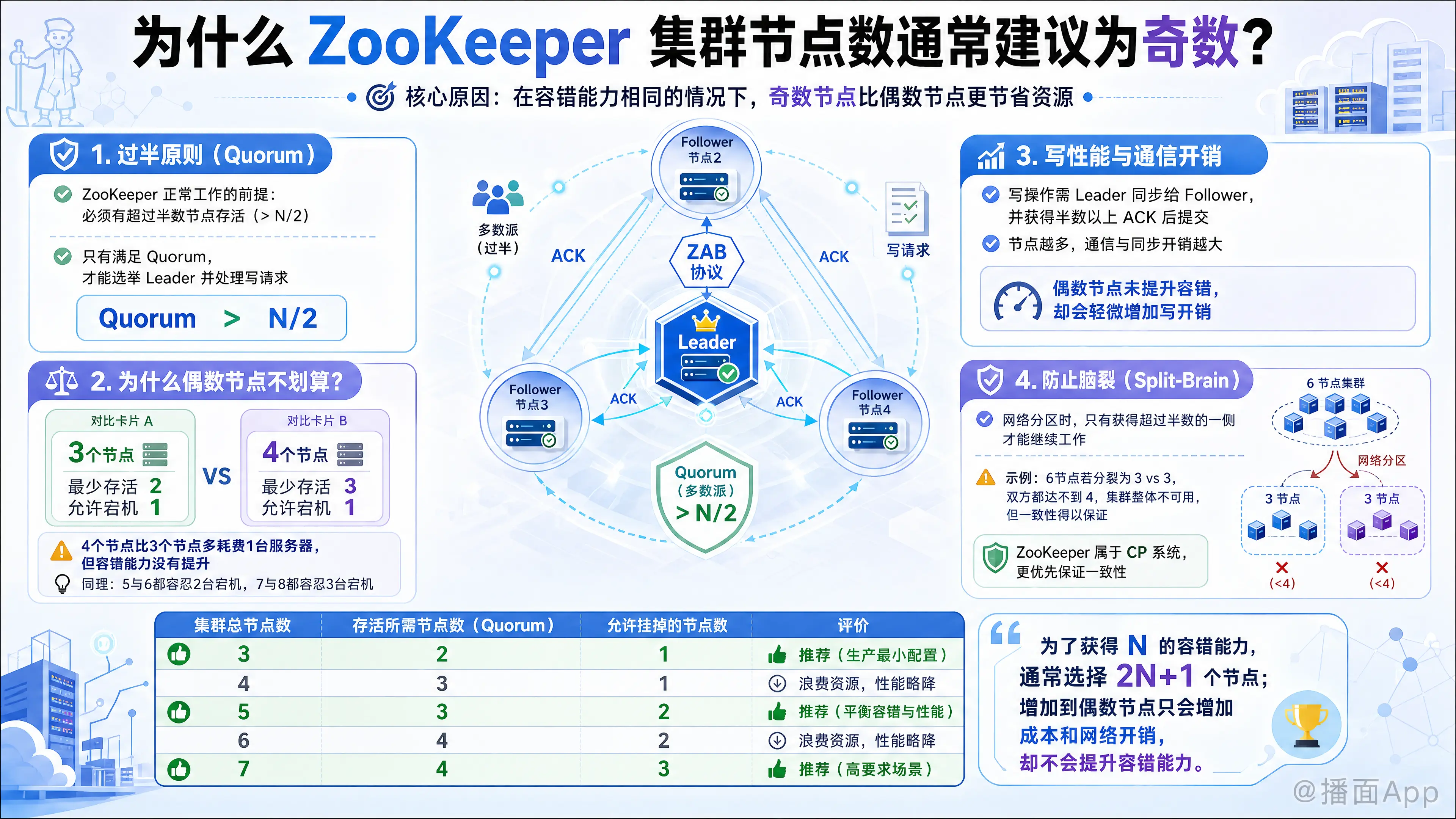
ZooKeeper 集群节点数建议为奇数,核心原因可以总结为一句话:在容错能力相同的情况下,奇数节点数比偶数节点数更节省资源(性价比更高)。
以下是详细的解释,主要涉及 ZooKeeper 的过半机制(Quorum)和容错性计算。
1. 核心机制:过半原则 (Majority Rule)
ZooKeeper 集群(ZAB 协议)正常工作的前提是:集群中必须有超过半数的节点存活。
- 如果有 个节点,正常工作所需的最小节点数(Quorum)必须 。
- 只有满足这个条件,集群才能选举出 Leader 并处理写请求。
2. 为什么偶数节点“不划算”?
我们可以通过对比 3个节点 和 4个节点 的情况来看出端倪:
场景 A:3 个节点的集群 (奇数)
- 总节点数 (N): 3
- 存活所需最少节点数 (): 2
- 允许挂掉的节点数 (容错数):
- 结论: 3个节点允许挂掉 1 个。
场景 B:4 个节点的集群 (偶数)
- 总节点数 (N): 4
- 存活所需最少节点数 (): 3 (注意:必须大于2,所以是3)
- 允许挂掉的节点数 (容错数):
- 结论: 4个节点也只能允许挂掉 1 个。
对比结果
- 容错能力相同: 3个节点和4个节点都只能容忍 1 台机器宕机。
- 资源浪费: 部署4个节点比3个节点多浪费了一台服务器的成本,却没有提升任何高可用性。
同理,5个节点和6个节点都只能容忍 2 台机器宕机。因此,部署偶数个节点在容错性上是“亏本”的。
3. 性能因素 (写操作开销)
ZooKeeper 的写操作(增删改)需要 Leader 节点同步给 Follower 节点,并且收到半数以上的 ACK 确认才能提交。
- 节点越多,通信开销越大: 增加节点会增加 Leader 与 Follower 之间的数据同步和网络通信压力。
- 偶数节点的劣势: 4个节点的集群不仅没有比3个节点增加容错性,反而因为多了一个节点,导致写操作时的网络通信量增加,轻微降低了写性能。
4. 防止脑裂 (Split-Brain)
虽然过半机制本身就是为了防止脑裂(即网络分区导致出现两个 Leader),但奇数节点在逻辑上更直观。
如果集群是偶数(比如 6 个),网络断开将集群平分成两半(3 vs 3),两边都无法满足“大于半数(需4个)”的条件,导致整个集群不可用。虽然这保证了数据一致性(CP系统),但从可用性规划的角度来看,奇数节点能更精确地利用“过半”这个数学特性。
总结表格
| 集群总节点数 | 存活所需节点数 (Quorum) | 允许挂掉的节点数 (容错数) | 评价 |
|---|---|---|---|
| 3 | 2 | 1 | 推荐 (生产环境最小配置) |
| 4 | 3 | 1 | 浪费资源,性能略降 |
| 5 | 3 | 2 | 推荐 (平衡容错与性能) |
| 6 | 4 | 2 | 浪费资源,性能略降 |
| 7 | 4 | 3 | 推荐 (高要求场景) |
一句话总结:
为了获得 个节点的容错能力,你需要 个节点。增加第 个节点(偶数)只会增加成本和网络开销,而不会增加容错能力。