 播面
播面 Lucene 内部的数据结构(如 FST, SkipList, BKD Tree)
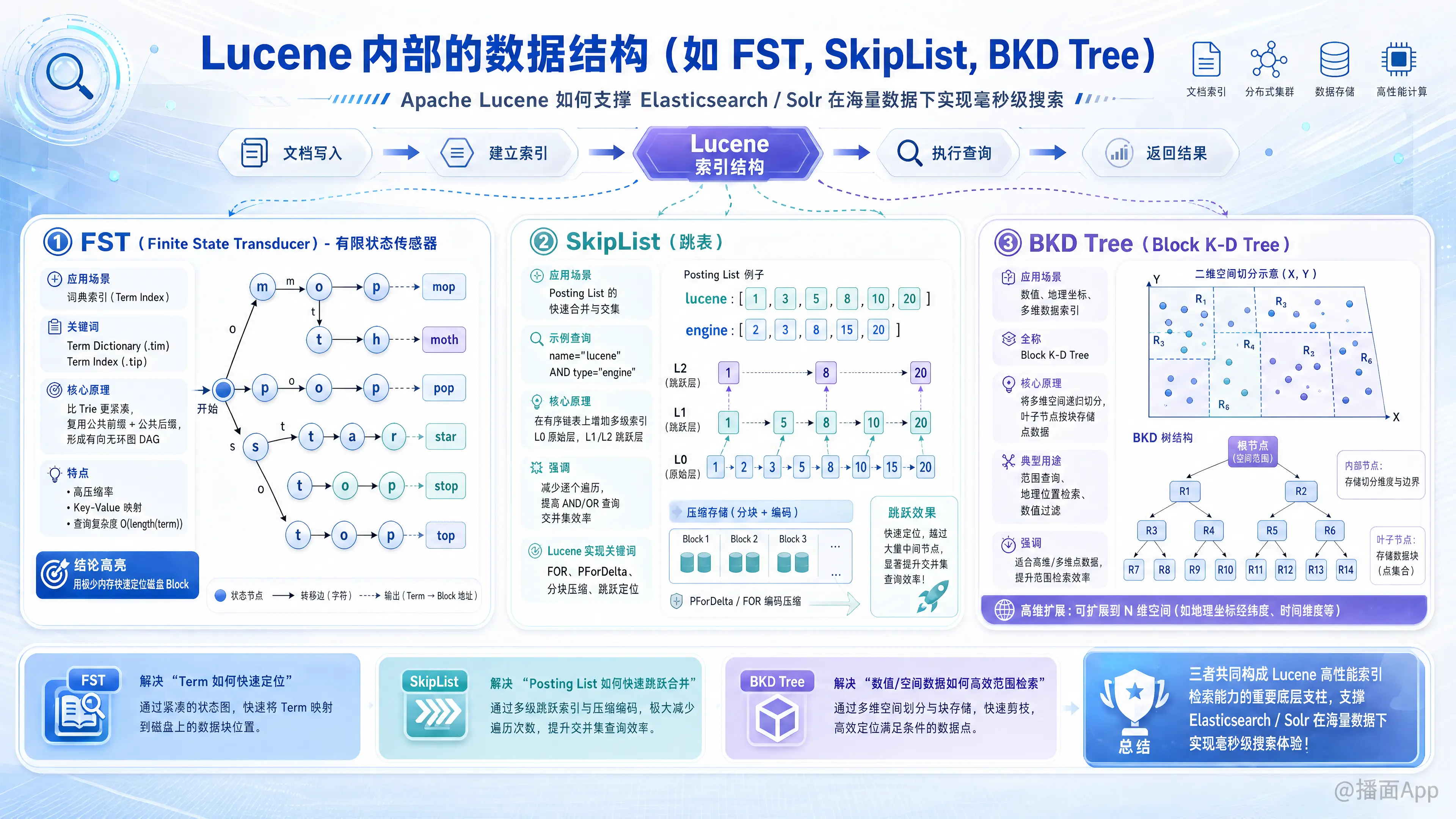
Apache Lucene 是 Elasticsearch 和 Solr 等搜索引擎的核心。为了在海量数据下实现毫秒级的搜索响应,Lucene 在底层使用了多种极其精妙的数据结构。
你提到的 FST、SkipList 和 BKD Tree 分别解决了倒排索引中不同环节的性能瓶颈。
以下是这三种核心数据结构的详细深度解析:
1. FST (Finite State Transducer) - 有限状态传感器
应用场景:词典索引 (Term Index)
在倒排索引中,我们需要根据关键词(Term)找到对应的文档 ID 列表(Posting List)。
- Term Dictionary (.tim):存储了所有的 Term,按字典序排列。
- Term Index (.tip):为了快速在 Dictionary 中定位 Term,需要一个索引。
早期 Lucene 将 Term Dictionary 全部加载到内存,但随着数据量增大,内存会爆。后来引入了 FST 作为 Term Index,它常驻内存(或堆外内存),用于快速定位 Term 在磁盘上的大概位置。
FST 的核心原理
FST 可以理解为一种更紧凑的 Trie 树(前缀树)。
- Trie 树:利用字符串的公共前缀来节省空间(例如 "cat" 和 "car" 共享 "ca")。
- FST:不仅利用公共前缀,还利用公共后缀。
举例:
假设我们要存储 "mop", "moth", "pop", "star", "stop", "top"。
- Trie: 会合并前缀。
- FST: 会发现 "mop" 和 "pop" 的后缀 "op" 是一样的,"stop" 和 "top" 的后缀 "top" 是一样的。FST 会将这些后缀节点合并,形成一个有向无环图 (DAG)。
FST 的特点
- 极高的压缩率:相比 HashMap 或 TreeMap,FST 可以节省大量的内存(通常只有原始文本大小的几分之一甚至几十分之一)。
- Key-Value 映射:FST 不仅能判断 Key 是否存在,还能关联一个 Value(Output)。在 Lucene 中,Input 是 Term 的前缀,Output 是该 Term 在磁盘 Block 中的偏移量。
- 查询复杂度:,与 Term 的数量无关,只与 Term 的长度有关。
总结:FST 用极少的内存代价,换取了快速定位磁盘 Block 的能力。
2. SkipList (跳表)
应用场景:倒排表 (Posting List) 的快速合并与交集
当我们在 FST 中找到了 Term,就会去磁盘读取对应的 Posting List(包含该 Term 的所有文档 ID,有序排列)。
例如:查询 name="lucene" AND type="engine"。
lucene的 Posting List:[1, 3, 5, 8, 10, 20, ...]engine的 Posting List:[2, 3, 8, 15, 20, ...]
我们需要对这两个有序链表求交集。如果只是普通链表,必须逐个遍历,效率为 。
SkipList 的核心原理
SkipList 是在有序链表的基础上增加了多级索引。
- L0 层:原始数据
1 -> 3 -> 5 -> 8 -> 10 -> 20 - L1 层:每隔几个元素提取一个
1 ------> 8 -------> 20
Lucene 中的实现细节
Lucene 的 Posting List 实际上采用了 Frame of Reference (FOR) 或 PForDelta 算法进行压缩(差值存储 + 位打包)。
- 数据被分成一个个 Block(例如每 128 个文档 ID 一个块)。
- SkipList 指向这些 Block 的头部。
查询过程(Advance 操作):
当我们需要查找是否存在 ID 为 8 的文档时:
- 不需从 1 开始遍历。
- 查看 SkipList 高层,发现 1 跳到 8。
- 直接定位到包含 8 的那个 Block。
- 解压该 Block,在块内进行线性查找。
总结:SkipList 使得 Lucene 在做多条件查询(AND 操作)时,能够跳过大量无关的文档 ID,实现 级别的快速求交集。
3. BKD Tree (Block K-D Tree)
应用场景:数值类型 (Int/Long/Double) 和 地理位置 (GeoPoint) 的范围查询
在 Lucene 6.0 之前,数字是转换成字符串存储在倒排索引中的(Trie 结构)。这导致范围查询(Range Query)非常慢,因为需要遍历大量的 Term。
Lucene 6.0 引入了 BKD Tree(基于 Point Values),彻底解决了这个问题。
BKD Tree 的核心原理
BKD Tree 是 K-D Tree (K-Dimensional Tree) 的变种,专门为磁盘存储优化(类似 B+ 树之于二叉搜索树)。
- 多维空间切分:
- 如果是一维数据(如价格),它类似二叉搜索树,将数据不断二分。
- 如果是二维数据(如经纬度),它会交替按 X 轴和 Y 轴切分空间。
- Block (块) 存储:
- 标准的 K-D Tree 是二叉树,树太高,磁盘 I/O 多。
- BKD Tree 的叶子节点不再是单个点,而是一个 Block(包含 512-1024 个点)。
- 内部节点存储的是分割维度的最小值和最大值索引。
为什么 BKD Tree 快?
- 极快的写入:BKD Tree 在内存中构建满一个 Buffer 后会刷写到磁盘,合并策略高效。
- 高效的范围查询:
- 查询
Price > 100:BKD Tree 可以快速剪枝,忽略掉所有< 100的子树分支,直接定位到符合条件的 Block。 - 查询
GeoDistance:在二维空间中快速圈定矩形或圆形区域内的点。
- 查询
- 空间利用率高:相比旧版的 Trie 字符串存储,BKD Tree 存储数值更加紧凑。
总结:BKD Tree 让 Lucene/Elasticsearch 在处理数字范围、日期范围和地理位置查询时,性能比旧版本提升了数倍甚至数十倍。
4. 综合对比与架构图解
为了方便记忆,可以参考下表:
| 数据结构 | 英文全称 | 所在文件 | 核心作用 | 解决的问题 | 类似概念 |
|---|---|---|---|---|---|
| FST | Finite State Transducer | .tip (Term Index) | 词典索引 | 内存有限,无法存下所有 Term,需要极致压缩 | Trie + DAG |
| SkipList | Skip List | .doc (Postings) | 倒排表跳跃 | 两个长有序链表求交集太慢,需要快速跳过 | 链表 + 二分查找思想 |
| BKD Tree | Block K-D Tree | .dim (Points) | 数值/Geo索引 | 倒排索引不适合做范围查询和多维数据查询 | K-D Tree + B+ Tree |
补充:DocValues (列式存储)
除了上述三个,还有一个非常重要的结构是 DocValues。
- 倒排索引 (Inverted Index):Term -> Doc ID (适合搜索)
- DocValues:Doc ID -> Value (适合排序、聚合、脚本访问)
- 它采用列式存储 (Columnar Storage),将同一字段的值连续存储,对 CPU 缓存友好,极大提升了
Sorting和Aggregations的性能。
总结
Lucene 的强大在于它不是用一种数据结构解决所有问题,而是针对不同的数据类型和查询场景,选用了最适合的结构:
- 找词用 FST。
- 找文档交集用 SkipList。
- 找数字/坐标范围用 BKD Tree。
- 做排序聚合用 DocValues。