 播面
播面 Elasticsearch 中的Analysis(分词)?Analyzer 由哪几部分组成?
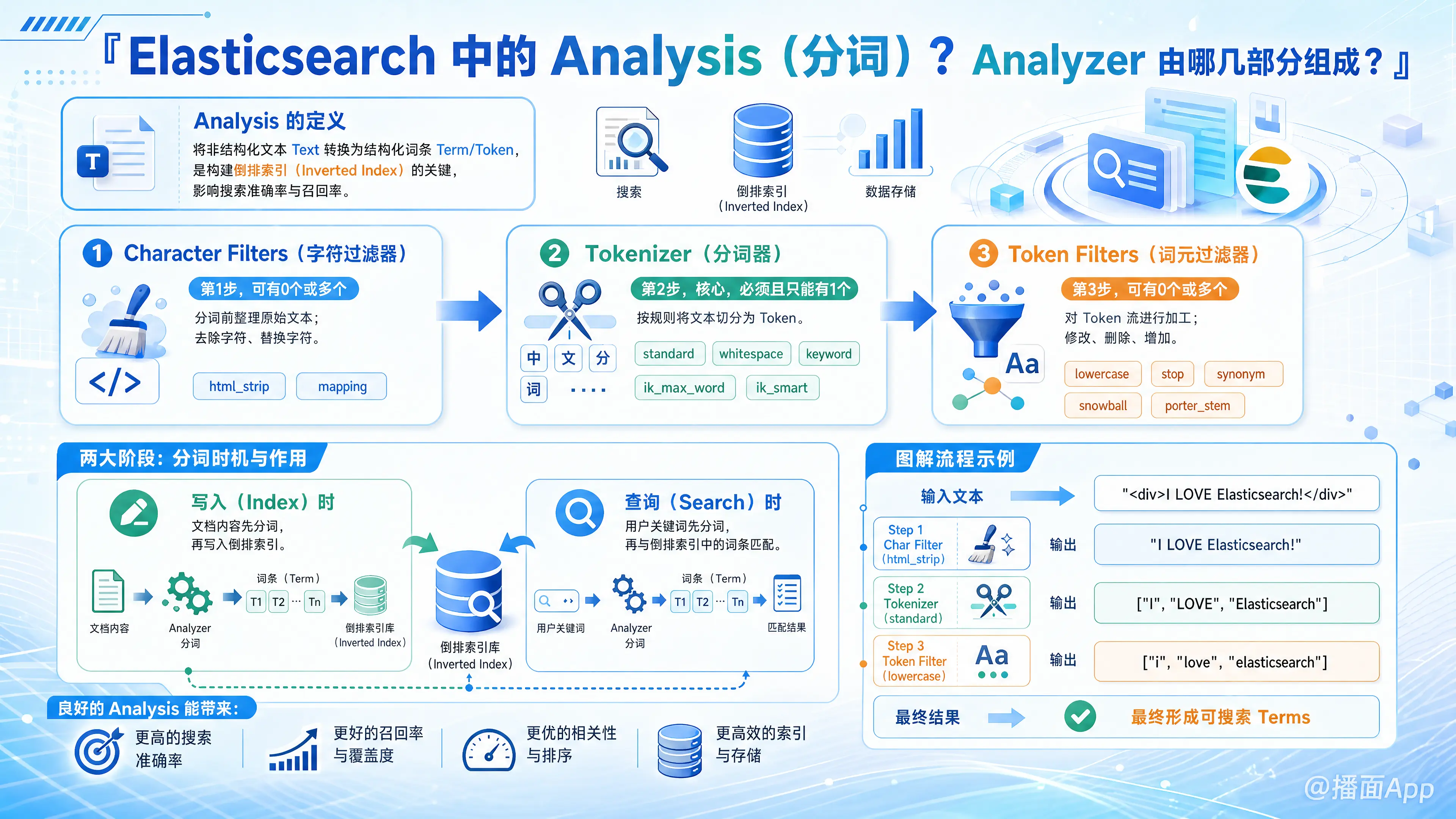
在 Elasticsearch 中,Analysis(分析/分词) 是将非结构化的文本数据(Text)转换为结构化的词条(Term/Token)的过程。这个过程对于构建倒排索引(Inverted Index)至关重要,直接决定了搜索的准确性和召回率。
Analysis 主要发生在两个阶段:
- 写入(Index)时:将文档内容分词后存入倒排索引。
- 查询(Search)时:将用户的搜索关键词(全文检索时)分词,以便与倒排索引中的词条进行匹配。
Analyzer(分析器)的组成
一个 Analyzer 就像一个流水线(Pipeline),严格按照顺序由以下 三部分 组成:
1. Character Filters(字符过滤器)
- 执行顺序:第一步。
- 数量:0 个或多个。
- 作用:在分词之前对原始文本进行处理。主要用于整理文本。
- 去除字符(例如:去除 HTML 标签)。
- 替换字符(例如:将
&替换为and,或者将表情符号替换为文字)。
- 常见例子:
html_strip:去除<div>,<p>等 HTML 标签。mapping:自定义映射替换。
2. Tokenizer(分词器)
- 执行顺序:第二步(核心)。
- 数量:必须且只能有 1 个。
- 作用:按照特定的规则将文本切分为一个个的单词(Token)。
- 常见例子:
standard(默认):按单词切分,去除标点符号。whitespace:仅按空格切分。keyword:不切分,将整个输入作为一个 Token(类似 Exact Match)。ik_max_word/ik_smart:中文分词器(需安装插件)。
3. Token Filters(词元过滤器/Token 过滤器)
- 执行顺序:第三步。
- 数量:0 个或多个(按顺序执行)。
- 作用:对 Tokenizer 切分后的 Token 流进行加工。
- 修改:将 Token 转为小写(Lowercase)。
- 删除:去除停用词(Stopwords,如 "a", "the", "is")。
- 增加:添加同义词(Synonyms,如 "jump" -> "leap")。
- 常见例子:
lowercase:转小写(实现大小写不敏感搜索的关键)。stop:移除停用词。synonym:处理同义词。snowball/porter_stem:词干提取(Stemming),如将 "running" 还原为 "run"。
图解流程
假设我们有一个 Analyzer,配置如下:
- Char Filter:
html_strip - Tokenizer:
standard - Token Filter:
lowercase
输入文本:"<div>I LOVE Elasticsearch!</div>"
处理过程:
Char Filter (
html_strip):- 输入:
"<div>I LOVE Elasticsearch!</div>" - 输出:
"I LOVE Elasticsearch!"(HTML 标签被移除)
- 输入:
Tokenizer (
standard):- 输入:
"I LOVE Elasticsearch!" - 输出:
["I", "LOVE", "Elasticsearch"](按单词切分,标点符号!被丢弃)
- 输入:
Token Filter (
lowercase):- 输入:
["I", "LOVE", "Elasticsearch"] - 输出:
["i", "love", "elasticsearch"](全部转为小写)
- 输入:
最终存入倒排索引的就是:i, love, elasticsearch。
如何测试 Analyzer?
Elasticsearch 提供了一个非常有用的 API _analyze,可以用来测试分词效果:
json
GET /_analyze
{
"analyzer": "standard",
"text": "Elasticsearch is AWESOME!"
}或者自定义组合测试:
json
GET /_analyze
{
"tokenizer": "standard",
"filter": ["lowercase"],
"text": "Elasticsearch is AWESOME!"
}总结
- Analysis 是文本到索引词条的转换过程。
- Analyzer = Char Filters (预处理) + Tokenizer (切分,核心) + Token Filters (后处理)。