 播面
播面 Temporal Table Join和Interval Join的区别
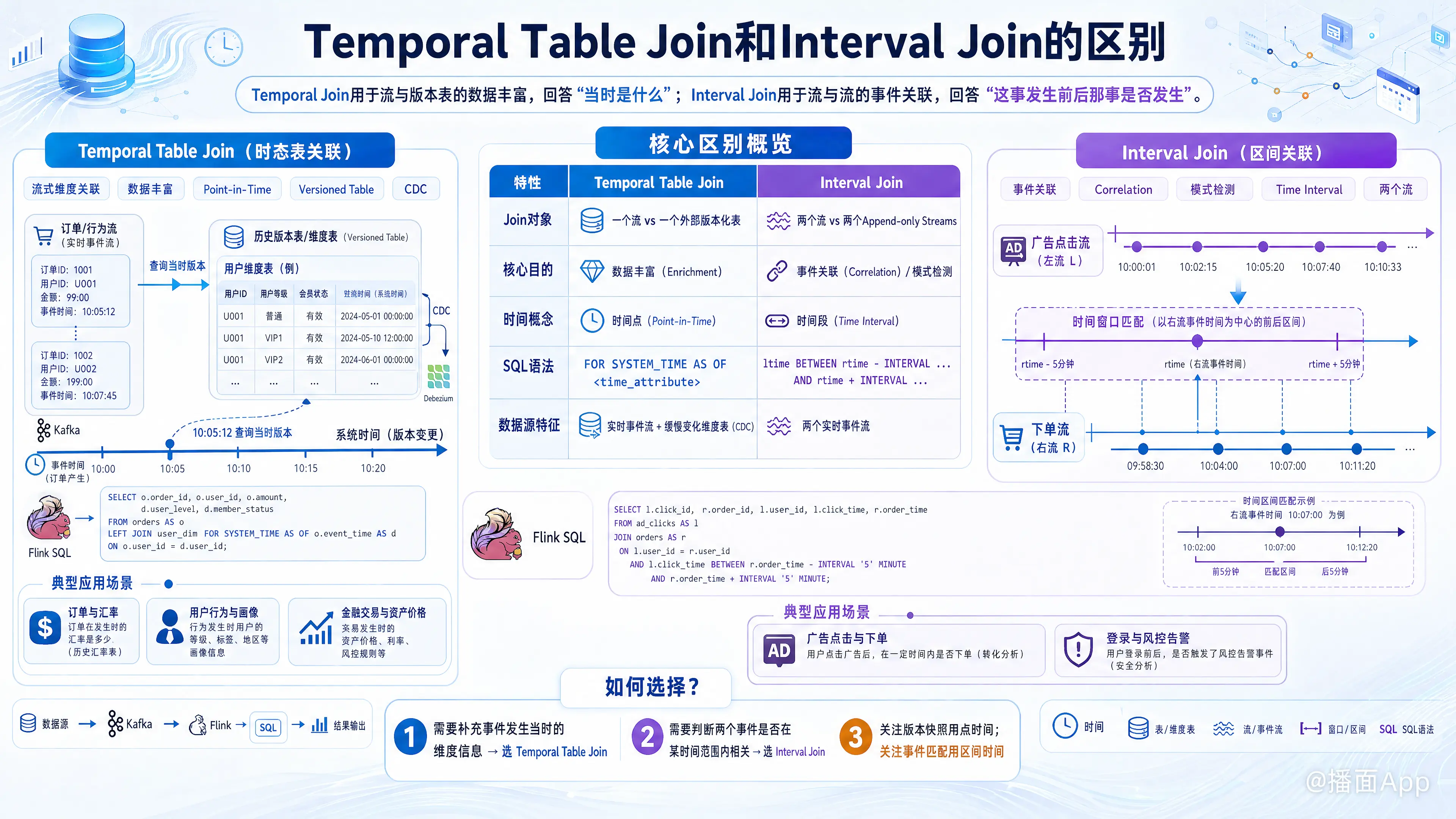
本文对比了Flink SQL中的两种时间关联:Temporal Join用于流与版本表的“数据丰富”,解决“当时是什么”的问题;Interval Join用于流与流的“事件关联”,解决“这事发生前后那事是否发生”的问题。
核心区别概览
一言以蔽之:
- Temporal Table Join 是 流 (Stream) 和 历史版本表 (Versioned Table) 的关联,目的是用“过去某个时间点”的维度数据来 丰富 流数据。它解决的是“当时是什么?”的问题。
- Interval Join 是 流 (Stream) 和 流 (Stream) 的关联,目的是将两个流中在“某个时间窗口”内发生的事件 关联 起来。它解决的是“这事发生前后,那事发生了吗?”的问题。
下面是一个清晰的对比表格:
| 特性 | Temporal Table Join | Interval Join |
|---|---|---|
| Join 对象 | 一个流 (Append-only) vs. 一个外部版本化表 (Changelog/Upsert Stream) | 两个流 (Append-only Streams) |
| 核心目的 | 数据丰富 (Enrichment) | 事件关联 (Correlation) / 模式检测 |
| 时间概念 | 时间点 (Point-in-Time):流中的每条记录需要查询版本化表在 那个时间点 的状态。 | 时间段 (Time Interval):一个流中的记录与另一个流中在 一段时间范围内 的记录进行匹配。 |
| SQL 语法 | FOR SYSTEM_TIME AS OF |
... ltime BETWEEN rtime - INTERVAL '...' AND rtime + INTERVAL '...' |
| 数据源特征 | 一个是实时事件流(如订单流),另一个是缓慢变化的维度表(如商品价格、汇率,通常来自数据库 CDC)。 | 两个都是实时事件流(如广告点击流、用户下单流)。 |
1. Temporal Table Join (时态表关联)
适用场景
当你需要用一个会随时间变化的状态或维度信息来补充你的实时事件流时,就应该使用 Temporal Table Join。这在数据仓库和实时数仓中非常常见,被称为 “流式维度关联”。
典型场景:
- 订单与汇率:处理一笔国际订单时,需要关联该订单发生 那一刻 的实时汇率,而不是当前的汇率。
- 用户行为与用户画像:分析用户点击行为时,需要关联用户点击 当时 的会员等级、所在城市等信息(这些信息可能会改变)。
- 金融交易与资产价格:撮合一笔交易时,需要关联交易发生 瞬间 的股票或加密货币价格。
示例:订单与实时汇率
假设我们有一个来自 Kafka 的订单流,订单金额是美元。同时,我们有一个来自数据库(通过 CDC 技术如 Debezium 同步到 Flink)的汇率表,这个汇率表每分钟都会更新。
数据流:
Orders(订单流, append-only)order_id amount_usd order_time 1 100 10:00:05 2 200 10:01:20 CurrencyRates(汇率表, changelog stream)currency rate update_time USD 6.8 10:00:00 USD 6.9 10:01:00 USD 6.85 10:02:00
目标:计算每笔订单发生时对应的人民币金额。
Flink SQL 实现:
sql
-- 1. 定义订单流 (来自 Kafka)
CREATE TABLE Orders (
order_id BIGINT,
amount_usd DECIMAL(10, 2),
order_time TIMESTAMP(3),
-- 定义事件时间戳和 Watermark
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
...
);
-- 2. 定义汇率表 (来自数据库 CDC)
-- 它是一个 changelog stream,Flink 会在内部维护其历史版本
CREATE TABLE CurrencyRates (
currency STRING,
rate DECIMAL(10, 4),
update_time TIMESTAMP(3),
-- 定义主键,用于 Flink 识别更新
PRIMARY KEY (currency) NOT ENFORCED,
-- 定义事件时间戳
WATERMARK FOR update_time AS update_time
) WITH (
'connector' = 'kafka',
'value.format' = 'debezium-json',
...
);
-- 3. 执行 Temporal Table Join
SELECT
o.order_id,
o.amount_usd,
-- 使用 FOR SYSTEM_TIME AS OF 语法
-- o.order_time 是流的时间戳,它决定了要查询 CurrencyRates 的哪个历史版本
r.rate,
o.amount_usd * r.rate AS amount_cny
FROM
Orders AS o
JOIN
CurrencyRates FOR SYSTEM_TIME AS OF o.order_time AS r
ON
o.currency = r.currency; -- 假设订单表中也有货币类型字段,这里简化为'USD'
执行逻辑:
- 当订单
order_id = 1(时间10:00:05) 到达时,Flink 会去CurrencyRates的历史版本中查找在10:00:05这个时间点有效的汇率。它会找到10:00:00更新的记录,所以使用的rate是6.8。 - 当订单
order_id = 2(时间10:01:20) 到达时,Flink 会查找在10:01:20这个时间点有效的汇率。它会找到10:01:00更新的记录,所以使用的rate是6.9。
2. Interval Join (区间关联)
适用场景
当你需要分析两个独立的事件流,并找出它们在时间上紧密相关的事件对时,就应该使用 Interval Join。
典型场景:
- 广告点击与转化:将用户在点击广告后 5分钟内 发生的购买行为进行关联,以评估广告效果。
- 订单与支付:关联用户下完订单后 15分钟内 完成的支付记录。
- 设备异常与操作日志:找出设备上报异常信号 前后30秒内 的用户操作日志,以排查问题。
示例:广告点击与用户下单
假设我们有两个独立的 Kafka topic,一个记录了用户的广告点击,另一个记录了用户的下单行为。
数据流:
AdClicks(广告点击流)user_id ad_id click_time user1 ad_A 09:55:00 user2 ad_B 09:58:00 Orders(订单流)user_id order_id order_time user1 order_X 09:57:00 user3 order_Y 10:05:00
目标:找出所有在点击广告后10分钟内下单的用户行为。
Flink SQL 实现:
sql
-- 1. 定义广告点击流
CREATE TABLE AdClicks (
user_id STRING,
ad_id STRING,
click_time TIMESTAMP(3),
WATERMARK FOR click_time AS click_time
) WITH (
'connector' = 'kafka',
...
);
-- 2. 定义订单流
CREATE TABLE Orders (
user_id STRING,
order_id STRING,
order_time TIMESTAMP(3),
WATERMARK FOR order_time AS order_time
) WITH (
'connector' = 'kafka',
...
);
-- 3. 执行 Interval Join
SELECT
c.user_id,
c.ad_id,
o.order_id,
o.order_time
FROM
AdClicks AS c
JOIN
Orders AS o
ON
-- 首先必须有关联键 (key)
c.user_id = o.user_id
AND
-- 核心:时间区间条件
o.order_time BETWEEN c.click_time AND c.click_time + INTERVAL '10' MINUTE;执行逻辑:
user1在09:55:00点击了广告,然后在09:57:00下单。由于09:57:00在[09:55:00, 10:05:00]这个时间区间内,所以这两个事件会成功关联。user2点击了广告但没有下单,不会产生关联结果。user3下了单但之前没有点击广告,也不会产生关联结果。
总结
| 对比维度 | Temporal Table Join | Interval Join |
|---|---|---|
| 问的问题 | “处理这个订单时,当时的汇率是多少?” | “这个用户下单前10分钟内,有没有点过广告?” |
| Join 关系 | 一对一(一个事件关联一个特定版本的状态) | 一对多(一个事件可能关联时间窗口内的多个事件) |
| 核心机制 | 基于时间点的状态查找 | 基于时间段的事件匹配 |
理解这两者的核心区别,能帮助你根据业务需求选择正确的工具来解决实时数据处理中的关联问题。