 播面
播面 Elasticsearch倒排索引(Inverted Index) 是如何工作的?
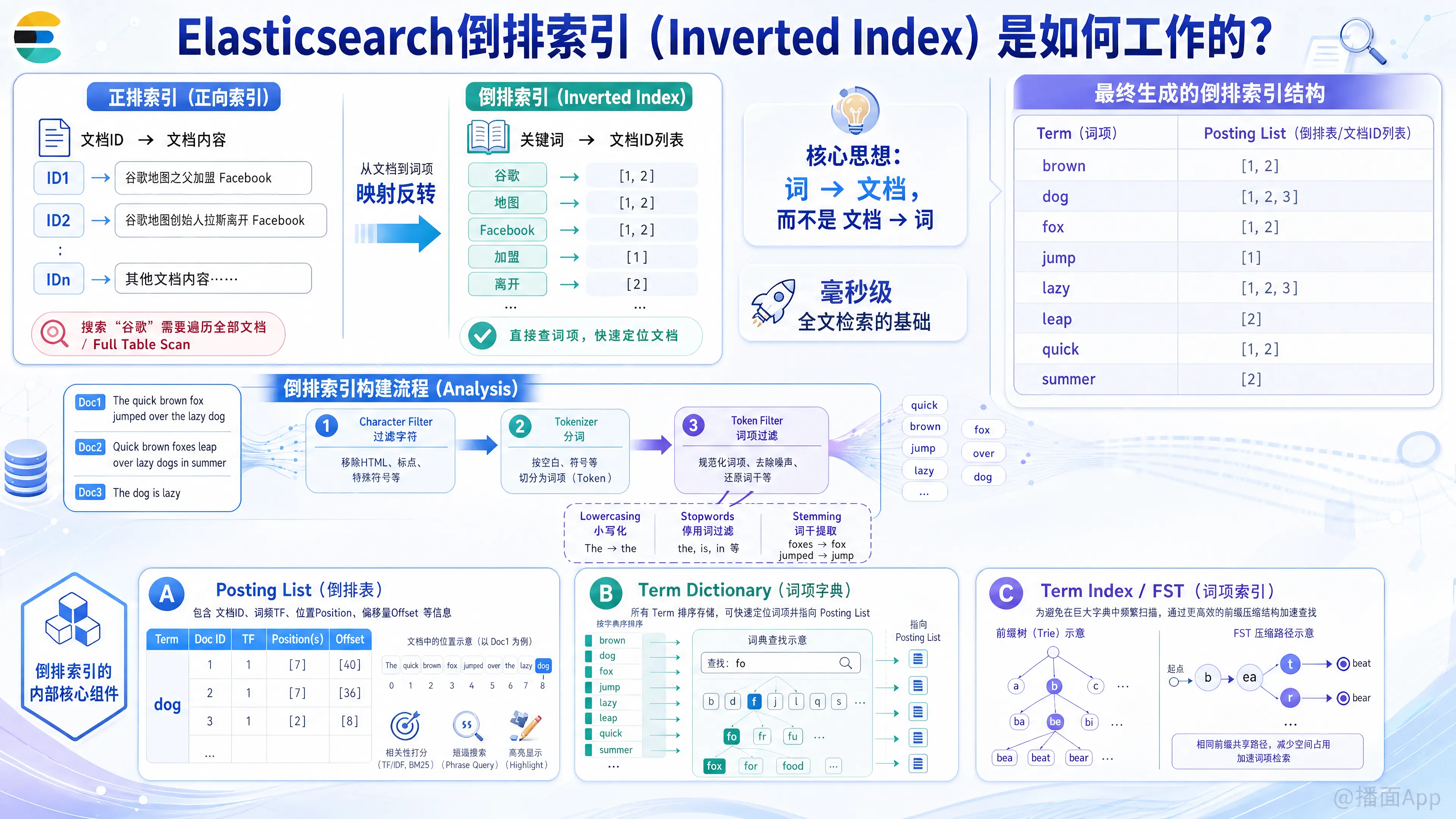
倒排索引(Inverted Index) 是 Elasticsearch(以及底层 Lucene)能够实现毫秒级全文搜索的核心数据结构。
为了理解它,我们首先需要理解它的对立面——正排索引(Forward Index)。
1. 直观对比:正排 vs 倒排
正排索引 (Forward Index)
这是传统关系型数据库(如 MySQL)存储数据的方式。
- 结构:
文档 ID -> 文档内容 - 例子:
- ID 1 -> "谷歌地图之父加盟 Facebook"
- ID 2 -> "谷歌地图创始人拉斯离开 Facebook"
- 搜索问题: 如果你要搜索包含“谷歌”的文档,数据库必须遍历每一行内容,检查是否包含该词。数据量大时,速度极慢(Full Table Scan)。
倒排索引 (Inverted Index)
这就好比书籍末尾的索引页。
- 结构:
关键词 (Term) -> 出现该词的文档 ID 列表 (Posting List) - 例子:
- "谷歌" -> [1, 2]
- "地图" -> [1, 2]
- "Facebook" -> [1, 2]
- "加盟" -> [1]
- "离开" -> [2]
- 搜索优势: 如果搜“加盟”,直接查表找到 ID [1]。不需要遍历所有文档。
2. 倒排索引的具体构建过程
假设我们有以下三个文档:
The quick brown fox jumped over the lazy dogQuick brown foxes leap over lazy dogs in summerThe dog is lazy
Elasticsearch 在写入数据时,会经过 Analysis(分析) 过程,包含以下步骤:
- Character Filter: 过滤字符(如去掉 HTML 标签)。
- Tokenizer (分词): 将文本切分为单词(Terms)。
- Token Filter (词项过滤):
- 小写化 (Lowercasing):
The->the - 停用词过滤 (Stopwords): 去掉
is,in,the等无意义词。 - 词干提取 (Stemming):
foxes->fox,jumped->jump。
- 小写化 (Lowercasing):
最终生成的倒排索引结构如下:
| Term (词项) | Posting List (倒排表/文档ID列表) |
|---|---|
| brown | [1, 2] |
| dog | [1, 2, 3] |
| fox | [1, 2] |
| jump | [1] |
| lazy | [1, 2, 3] |
| leap | [2] |
| quick | [1, 2] |
| summer | [2] |
3. 倒排索引的内部核心组件
在物理存储和内存中,倒排索引并不只是一个简单的哈希表,它由三部分组成,层层递进以优化性能:
A. Posting List (倒排表)
这是记录了包含特定 Term 的所有文档 ID 的列表。
除了文档 ID,它通常还包含:
- 词频 (TF): 该词在文档中出现的次数(用于打分排序)。
- 位置 (Position): 该词在文档中的位置(用于短语搜索,如 "quick brown")。
- 偏移量 (Offset): 字符的开始结束位置(用于高亮显示)。
B. Term Dictionary (词项字典)
由于 Term 非常多,我们需要把所有的 Term 排序后存储起来。
- 作用: 类似于查字典,通过二分查找快速找到 Term,然后指向对应的 Posting List。
- 存储: 通常存储在磁盘上。
C. Term Index (词项索引) —— 关键优化
如果 Term Dictionary 非常大(比如几千万个单词),放到内存里放不下,放到磁盘上查得慢(需要多次磁盘 IO)。
为了解决这个问题,Lucene 引入了 Term Index。
- 原理: 它是 Term Dictionary 的索引(索引的索引)。它不存储所有的 Term,只存储 Term 的前缀。
- 数据结构:FST (Finite State Transducer)。
- FST 是一种类似于 Trie 树(前缀树)的结构,但更节省空间。
- 它可以将公共前缀共享(例如 "bro" 是 "brown" 和 "brother" 的公共前缀)。
- 极度压缩: 它可以被完整地加载到内存中。
查找流程:
- 内存中查 Term Index 找到 Term 在 Dictionary 数据块的大致位置(Offset)。
- 去磁盘读取 Term Dictionary 的那个数据块 找到准确的 Term。
- 通过 Term 找到 Posting List 得到文档 ID。
4. 空间压缩黑科技 (Frame of Reference & Roaring Bitmaps)
Posting List 可能会包含成千上万个 ID(例如常用词 "the" 对应的 ID 列表)。如果直接存 Int 数组,非常浪费空间。Elasticsearch 使用了两种主要的压缩算法:
Frame of Reference (FOR) - 增量编码:
- 不存
[1, 3, 5, 8],而是存[1, 2, 2, 3](后一个数减前一个数的差值)。 - 差值通常很小,可以用更少的 bit 存储(比如不需要 32bit,只需要 2bit)。
- 适用场景: 稠密的 ID 列表。
- 不存
Roaring Bitmaps (咆哮位图):
- 利用位图(Bitmap)来表示 ID 是否存在。
- 优势: 进行交集(AND)、并集(OR)操作时,位运算速度极快。
- 适用场景: 比如 Filter 查询
status=active AND type=user,就是两个 Bitmap 做按位与操作。
5. 总结:Elasticsearch 搜索为什么快?
- 倒排结构: 避免了全表扫描,通过单词直接定位文档。
- 内存常驻 Term Index (FST): 利用 FST 极度压缩词前缀,保证了定位 Term 的速度几乎等同于内存随机访问。
- 高效的压缩算法 (FOR/Roaring): 减少了磁盘 IO,并且让 Posting List 的交集、并集运算(即复杂的组合查询)在 CPU 层面极快地完成。
这就是 Elasticsearch 倒排索引的工作原理:通过空间换时间,利用极致的压缩和分层索引结构,实现海量数据的快速检索。