 播面
播面 什么是“幻觉率”?在 RAG 场景下如何具体量化幻觉?
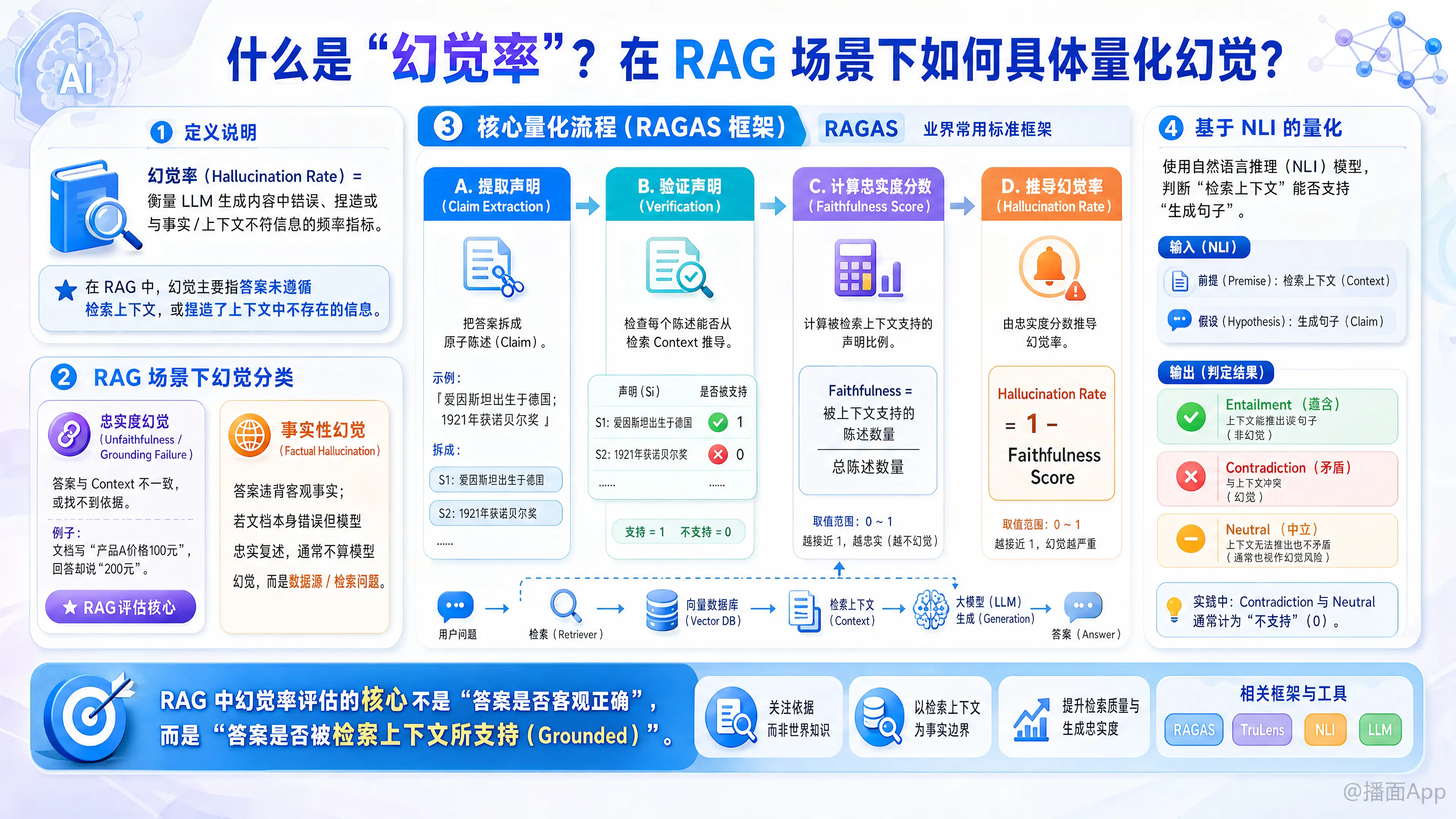
“幻觉率”(Hallucination Rate) 是衡量大语言模型(LLM)生成内容中包含错误、无中生有或与事实/上下文不符信息的频率指标。
在 RAG(检索增强生成) 场景下,幻觉率的定义比通用场景更为严格。RAG 的核心目的是让模型基于检索到的参考文档(Context)回答问题,因此,RAG 中的幻觉主要指模型生成的答案没有遵循检索到的上下文,或者捏造了上下文中不存在的信息。
以下是关于幻觉率的详细定义以及在 RAG 场景下具体的量化方法:
一、 RAG 场景下的“幻觉”分类
在量化之前,必须明确 RAG 中的幻觉主要分为两类:
忠实度幻觉(Unfaithfulness / Grounding Failure):
- 定义: 模型生成的答案与检索到的上下文(Context)不一致,或者答案中的信息在上下文中找不到依据。
- 例子: 文档说“产品A的价格是100元”,模型回答“产品A的价格是200元”。
- 这是 RAG 评估的核心: 即使模型利用其内部训练数据回答正确了(例如常识),但如果该信息不在检索到的文档中,通常也被视为 RAG 系统的“幻觉”(因为它没有由检索内容 Grounding)。
事实性幻觉(Factual Hallucination):
- 定义: 模型生成的答案违背了客观世界的事实。
- 注意: 在 RAG 中,如果检索到的文档本身就是错的,模型忠实地复述了错误信息,这通常不被算作模型的幻觉,而是数据源或检索层的问题。
二、 如何具体量化幻觉?(核心方法)
目前业界最主流的量化方法是使用 “LLM-as-a-Judge”(用更强的 LLM 来评估较小的 LLM)结合结构化的评估框架(如 RAGAS 或 TruLens)。
1. 基于 RAGAS 框架的量化(最常用)
RAGAS (Retrieval Augmented Generation Assessment) 是目前衡量 RAG 性能的标准框架,它通过 Faithfulness(忠实度) 指标来反向推导幻觉率。
计算步骤:
提取声明(Claim Extraction):
利用 LLM(如 GPT-4)将 RAG 生成的答案拆解为一个个独立的原子陈述(Statements)。- 答案: “爱因斯坦出生于德国,并在1921年获得诺贝尔奖。”
- 拆解: S1: 爱因斯坦出生于德国。 S2: 爱因斯坦在1921年获得诺贝尔奖。
验证声明(Verification):
利用 LLM 检查每一个陈述(S)是否可以从检索到的上下文(Context)中推导出来。- 如果 S1 在 Context 中存在 1
- 如果 S2 在 Context 中不存在 0
计算忠实度分数(Faithfulness Score):
推导幻觉率:
2. 基于 NLI (自然语言推理) 的量化
使用专门训练用于检测蕴含关系(Entailment)的小模型(如 DeBERTa 等 Cross-Encoder 模型)来判断。
- 输入: (前提:检索到的上下文, 假设:生成的句子)
- 输出分类:
- Entailment (蕴含): 上下文支持该句子 非幻觉。
- Contradiction (矛盾): 上下文与句子冲突 幻觉。
- Neutral (中立): 上下文未提及该信息 幻觉(在 RAG 严格模式下)。
- 量化: 统计被标记为 Contradiction 和 Neutral 的句子占比。
3. SelfCheckGPT (无参考文本的黑盒检测)
如果不想依赖外部检索文档做对比,可以使用模型自身的不确定性来量化。
- 原理: 让模型对同一个 Prompt 生成 N 次回复。
- 假设: 如果模型“知道”事实,N 次回复的内容应该高度一致;如果模型在“瞎编”(幻觉),N 次回复的内容会发散或互相矛盾。
- 量化: 计算 N 次回复之间的语义一致性(BERTScore)或困惑度(Perplexity)。一致性越低,幻觉率越高。
三、 具体的计算公式示例
假设我们进行了一次 RAG 问答测试:
- 用户问题: “特斯拉 Model 3 的续航是多少?”
- 检索到的上下文: “特斯拉 Model 3 标准版续航为 556 公里,高性能版为 675 公里。”
- 模型生成答案: “Model 3 标准版续航 556 公里,而且它支持太阳能充电。”
量化过程:
- 拆解声明:
- S1: Model 3 标准版续航 556 公里。
- S2: Model 3 支持太阳能充电。
- 验证:
- S1 上下文中有 Pass。
- S2 上下文中未提及 Fail (幻觉)。
- 计算:
- 总声明数 = 2
- 支持数 = 1
- Faithfulness = 1 / 2 = 0.5
- 幻觉率 = 1 - 0.5 = 50%
四、 总结与建议
在 RAG 生产环境中,建议关注以下两个核心指标来综合评估幻觉:
- Faithfulness (忠实度): 衡量 Answer vs Context。解决“模型是否在胡编乱造”的问题。这是直接的幻觉率指标。
- Answer Relevance (答案相关性): 衡量 Answer vs Question。解决“模型是否答非所问”的问题。虽然不是直接的幻觉,但答非所问往往伴随着逻辑混乱。
最佳实践:
不要仅依赖人工评估(太慢、太贵)。建立一套自动化评估管线(Evaluation Pipeline),使用 RAGAS 或 DeepEval 等工具,在每次模型迭代或 Prompt 更新后,自动运行测试集,计算出具体的“幻觉率”数值。