 播面
播面 RAG 中,如何去除检索回来的冗余信息(Diversity Ranking)?
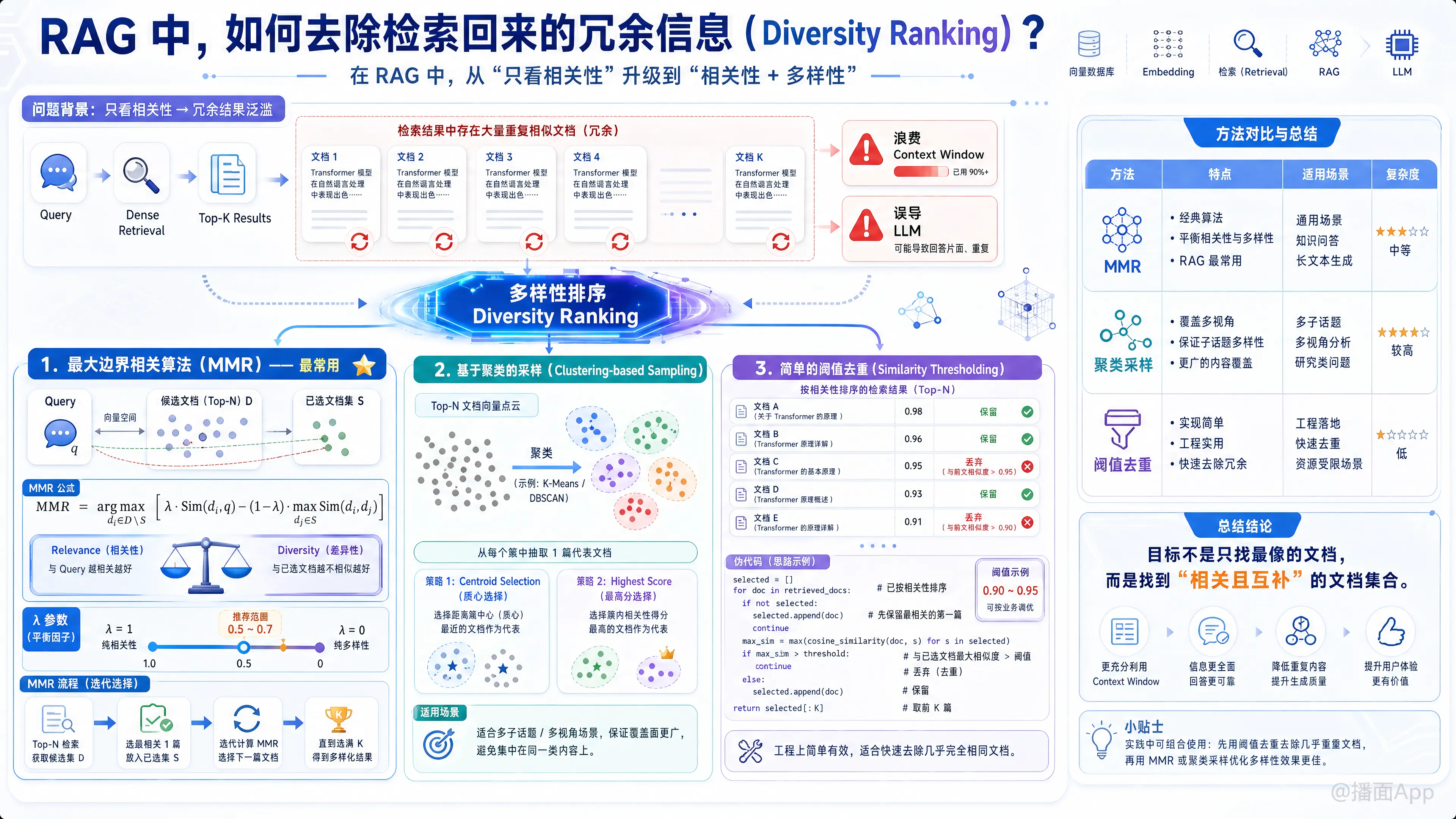
在 RAG(检索增强生成)系统中,标准的向量检索(Dense Retrieval)通常只关注相关性(Relevance)。这意味着如果你的知识库中有大量相似的文档(例如多篇关于同一新闻的报道,或者同一概念的重复定义),检索出的 Top-K 结果往往内容高度重复。
这会导致两个问题:
- 浪费 Context Window:大模型的上下文窗口有限,重复信息挤占了其他潜在有用信息的空间。
- 误导 LLM:重复信息可能导致模型产生“幻觉”或过分关注某一点,忽略了更全面的视角。
为了解决这个问题,我们需要引入多样性排序(Diversity Ranking)。以下是几种主流的去除冗余、提升多样性的方法:
1. 最大边界相关算法 (Maximal Marginal Relevance, MMR) —— 最常用
这是目前 RAG 中最经典、最常用的去重与多样性算法(LangChain 和 LlamaIndex 均内置支持)。
核心思想:
在选择下一个文档时,不仅要看它与Query(查询)的相关性,还要看它与已选文档集的差异性(不相似度)。
公式逻辑:
- : 候选文档与查询的相关性。
- : 候选文档与已选文档的相似度(惩罚项)。
- : 超参数(0~1)。
- : 纯相关性搜索(标准向量搜索)。
- : 纯多样性搜索(寻找差别最大的)。
- 通常设为 0.5 ~ 0.7 以取得平衡。
操作流程:
- 先检索出 Top-N 个结果(N > 最终需要的 K,例如 N=20, K=5)。
- 选择与 Query 最相关的 1 个文档放入集合 。
- 循环选择剩余文档,计算 MMR 得分,选分最高的放入 ,直到选满 K 个。
2. 基于聚类的采样 (Clustering-based Sampling)
这种方法适用于检索结果包含多个不同“子话题”或“视角”的场景。
核心思想:
将检索回来的 Top-N 个文档进行聚类,然后从每个簇(Cluster)中选取最具代表性的文档。
操作流程:
- 检索 Top-N 文档(例如 N=20)。
- 利用文档的 Embedding 向量进行聚类(如 K-Means 或 DBSCAN)。假设聚成 K 类。
- 抽取策略:
- Centroid Selection:选择离每个簇中心最近的文档。
- Highest Score:选择每个簇中与 Query 相关性最高的文档。
- 这样保证了最终提交给 LLM 的 K 个文档分别来自不同的语义簇,覆盖面更广。
3. 简单的阈值去重 (Similarity Thresholding)
这是一种简单粗暴但有效的工程化手段,用于去除“几乎完全一样”的文档。
核心思想:
按相关性排序后,遍历列表,如果当前文档与列表中排在前面的任何文档的相似度超过某个阈值(如 0.95),则直接丢弃。
伪代码:
final_docs = []
for doc in retrieved_docs:
is_redundant = False
for selected in final_docs:
if cosine_similarity(doc, selected) > 0.90: # 阈值
is_redundant = True
break
if not is_redundant:
final_docs.append(doc)4. 确定性点过程 (Determinantal Point Processes, DPP) —— 进阶
DPP 是一种源自物理学的数学模型,用于对子集进行概率建模,天然倾向于选择多样性高的子集。
核心思想:
构建一个核矩阵(Kernel Matrix),其中对角线元素代表相关性,非对角线元素代表相似性。DPP 选择子集的概率与该子集对应的子矩阵的行列式成正比。
特点:
- 数学上比 MMR 更优雅,能同时优化整体集合的多样性,而不是贪婪地逐个选择。
- 缺点:计算复杂度相对较高(),在实时性要求极高的 RAG 中不如 MMR 普及。
5. 利用 LLM 或 Cross-Encoder 进行重排 (Listwise Reranking)
利用更强大的模型来替你做去重判断。
方案 A:Cross-Encoder Reranking
使用 Cross-Encoder(如 BGE-Reranker, Cohere Rerank)对 Top-N 结果进行打分。虽然 Cross-Encoder 主要优化相关性,但一些训练良好的 Reranker 会隐式地压低冗余信息的排名,或者你可以结合 MMR 逻辑使用 Cross-Encoder 的分数。
方案 B:LLM Listwise Prompting
直接将 Top-N 的摘要或标题发给 LLM(如 GPT-3.5/4),Prompt 如下:
"以下是关于用户查询的 10 个搜索结果。请从中挑选出 3 个最相关且内容互不重复的段落,返回它们的 ID。"
- 优点:语义理解能力最强,能识别“文字不同但意思一样”的深层冗余。
- 缺点:增加了延迟和 Token 成本。
总结与建议
在实际 RAG 落地中,推荐的实施路径如下:
首选方案:MMR (Maximal Marginal Relevance)。
- 理由:实现简单,计算开销小,效果立竿见影。LangChain 等框架一行代码即可开启。
- 配置:先检索 Top-20,再通过 MMR 筛选出 Top-5。
如果存在大量完全重复的数据(如由于切片导致的重叠):
- 先做 阈值去重(Similarity Threshold > 0.95),再做 MMR。
如果对精度要求极高:
- Vector Search (Top 50) -> Cross-Encoder Rerank (Top 10) -> MMR (Top 5)。
- 这种“三明治”结构既保证了相关性(Rerank),又保证了多样性(MMR)。