 播面
播面 什么是“父子索引”(Parent-Child Indexing)或“小块检索大块生成”(Small-to-Big Retrieval)策略?
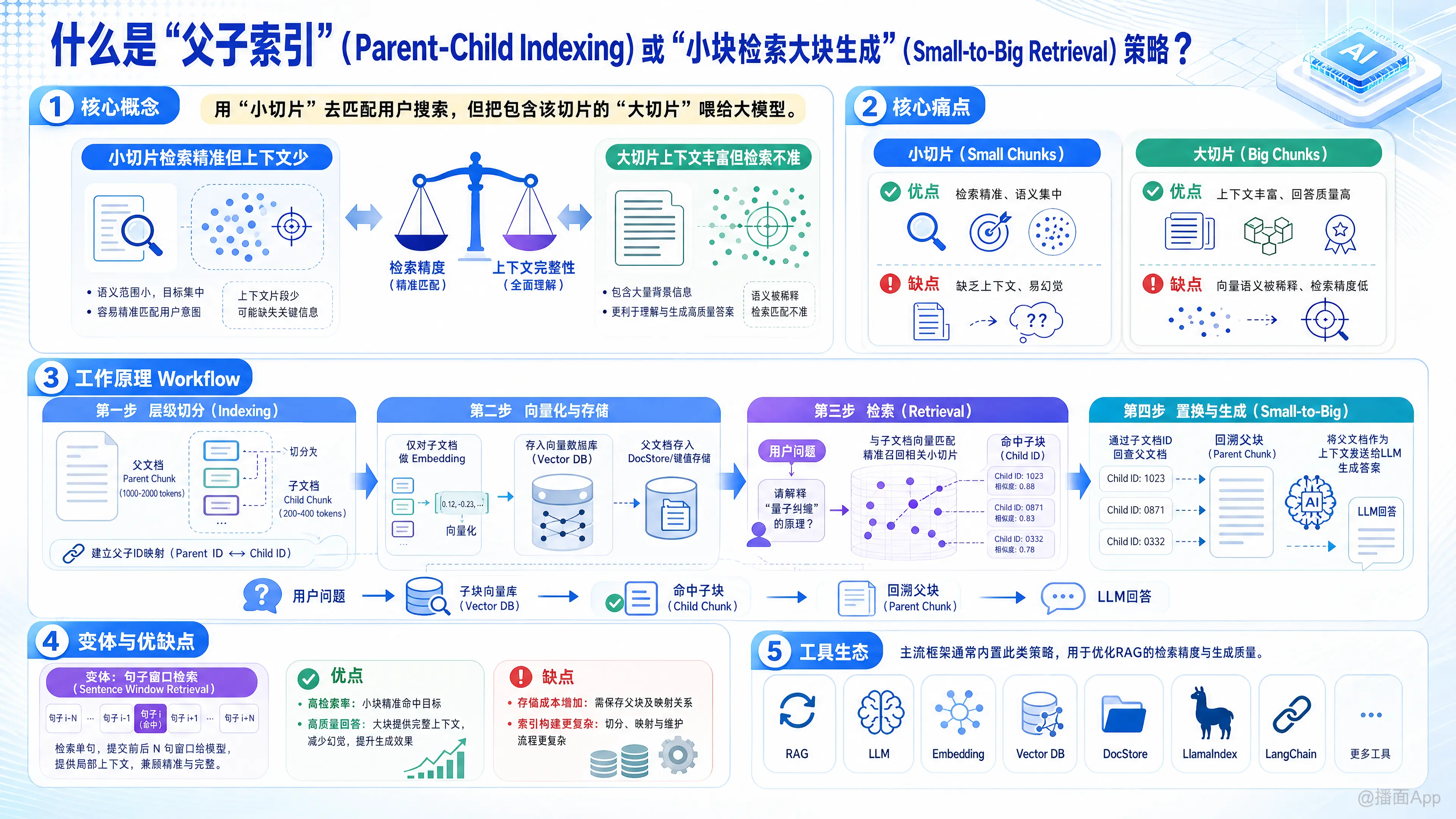
“父子索引”(Parent-Child Indexing) 和 “小块检索大块生成”(Small-to-Big Retrieval) 指的是同一种在 RAG(检索增强生成)应用中用于优化效果的高级策略。
简单来说,这种策略的核心思想是:用“小切片”去匹配用户的搜索,但把包含该切片的“大切片”喂给大模型。
这种策略旨在解决传统 RAG 中的一个核心矛盾:检索精度与上下文完整性之间的权衡。
以下是详细的解释:
1. 核心痛点:为什么要用这个策略?
在构建 RAG 系统时,我们需要把长文档切分成块(Chunks)。这里存在一个两难的选择:
- 如果切片很小(Small Chunks):
- 优点: 检索非常精准。因为文本短,语义集中,向量(Embedding)能很好地代表这段话的含义,容易匹配到用户的具体问题。
- 缺点: 缺乏上下文。如果直接把这短短的一句话喂给 LLM(大模型),模型可能因为缺乏前因后果而无法回答问题,或者产生幻觉。
- 如果切片很大(Big Chunks):
- 优点: 上下文丰富。模型能看到完整的段落或章节,更容易理解逻辑,生成的回答质量高。
- 缺点: 检索精度低。一段长文本包含太多杂乱的信息,其向量表示会被稀释(diluted),导致很难通过语义搜索精准找到它。
“父子索引”策略就是为了兼得二者的优点:用小的做检索,用大的做生成。
2. 工作原理(Workflow)
这个策略的实施通常分为以下几个步骤:
第一步:层级切分(Indexing)
- 父文档(Parent Chunk): 首先将文档切分成较大的块(例如 1000-2000 tokens)。这些大块包含了完整的上下文信息。
- 子文档(Child Chunk): 然后,将每个“父文档”进一步切分成多个更小的“子文档”(例如 200-400 tokens)。
- 建立关联: 在数据库中,记录下子文档与父文档的映射关系(即:这个子切片属于哪个父切片)。
第二步:向量化与存储
- 只对“子文档”进行向量化(Embedding): 我们只计算小切片的向量,并存入向量数据库用于搜索。
- 存储“父文档”: 父文档通常存储在键值存储(DocStore)中,不需要向量化,只需要能通过 ID 索引到即可。
第三步:检索(Retrieval)
- 当用户提问时,系统将问题与子文档的向量进行匹配。
- 由于子文档语义集中,系统能非常精准地找到最相关的几个小切片。
第四步:置换与生成(Small-to-Big)
- 系统找到最相关的子文档后,并不直接把子文档给 LLM。
- 系统通过预存的 ID,找到该子文档所属的父文档。
- 系统将内容丰富的父文档作为 Context(上下文)发送给 LLM 进行回答生成。
3. 变体:句子窗口检索(Sentence Window Retrieval)
这是“小块检索大块生成”的一种特定且常见的实现方式:
- 小块: 单个句子。
- 大块: 该句子前后各扩展 N 个句子的窗口(Window)。
- 逻辑: 检索时匹配某一个具体的句子,但发给 LLM 时,带上这个句子前后的上下文。
4. 优缺点总结
优点:
- 高检索率(Recall): 小切片更容易匹配到具体的细节问题。
- 高质量回答: 大模型获得了充足的上下文,理解更深刻,回答更连贯,减少断章取义。
缺点:
- 存储成本增加: 需要同时存储父块和子块(或者存储全文并动态截取),比单纯存储一种切片占用更多空间。
- 索引构建稍慢: 预处理逻辑比简单的切分要复杂一些。
5. 常见实现工具
目前主流的 LLM 开发框架都内置了这种策略:
- LlamaIndex: 称之为
AutoMergingRetriever或ParentDocumentRetriever。它是这个概念最主要的推广者。 - LangChain: 提供了
ParentDocumentRetriever类来实现这一功能。
总结
“父子索引” 是将搜索单元(Search Unit)和生成单元(Generation Unit)解耦的一种技术。它让 RAG 系统既拥有搜索引擎的精准度,又拥有阅读理解所需的完整视野。