 播面
播面 在 RAG 中,常见的文本切分(Chunking)策略有哪些?固定大小切分和语义切分(Semantic Chunking)有什么区别?
在 RAG(检索增强生成)系统中,文本切分(Chunking) 是决定检索质量的关键预处理步骤。切分过大可能导致包含过多噪音,切分过小可能导致上下文缺失。
以下是常见的切分策略,以及“固定大小切分”与“语义切分”的详细对比。
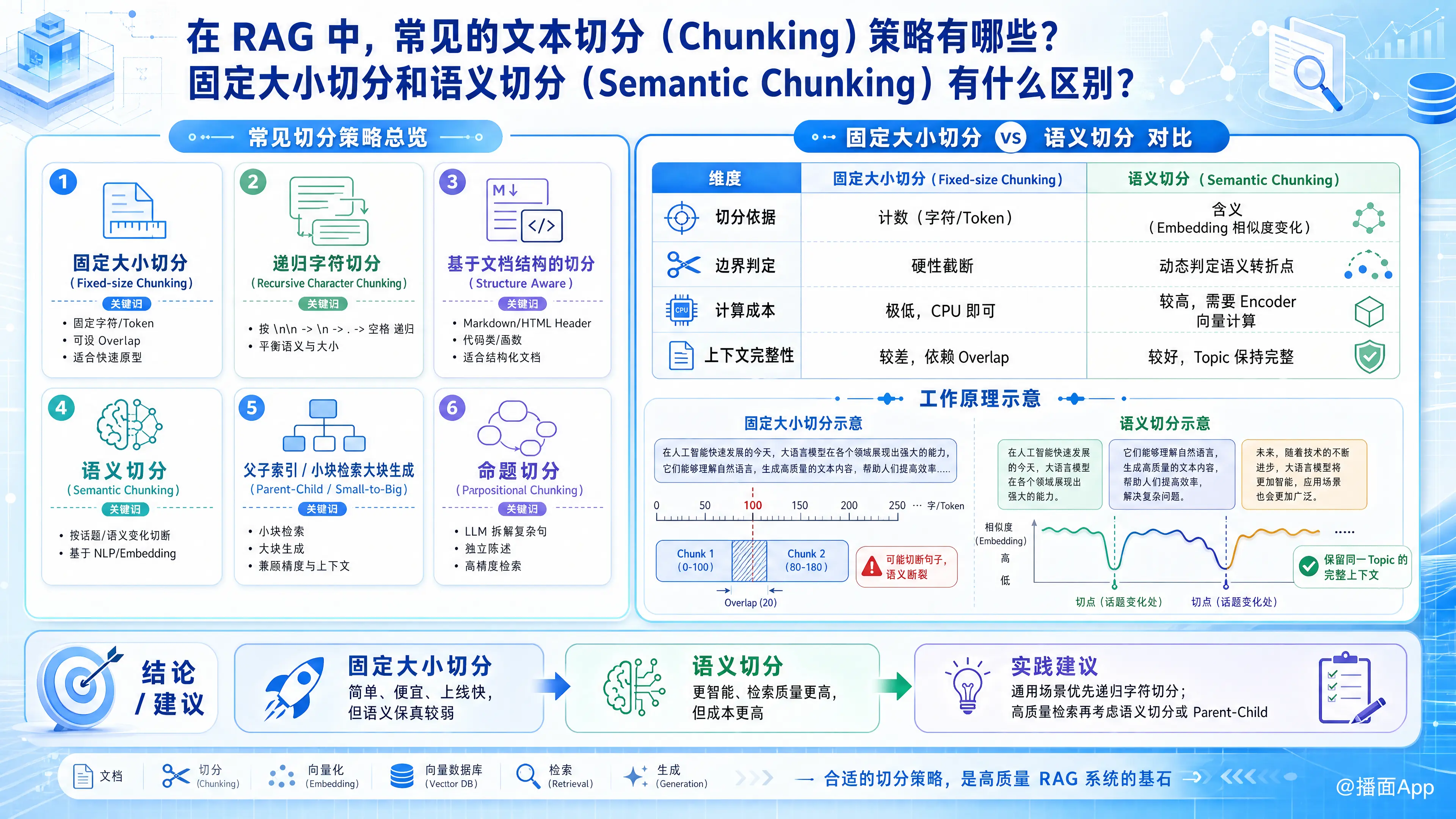
一、 RAG 中常见的文本切分策略
1. 固定大小切分 (Fixed-size Chunking)
这是最基础的方法。直接设定一个固定的字符数(Character)或 Token 数,将文本强行截断。
- 特点: 通常会设定一个 重叠窗口(Overlap)(例如每块 500 tokens,重叠 50 tokens),以防止上下文在切分点丢失。
- 适用场景: 快速原型开发、对上下文连贯性要求不高的场景。
2. 递归字符切分 (Recursive Character Chunking)
这是目前最常用的“通用”策略(如 LangChain 的默认策略)。
- 原理: 它尝试按顺序使用一组分隔符(如
\n\n->\n->.-> - 适用场景: 通用文档,试图在保持语义结构和控制块大小之间取得平衡。
3. 基于文档结构的切分 (Document Based / Structure Aware)
根据文件的特定格式进行切分。
- Markdown/HTML: 利用 Header (
#,##) 或 HTML 标签 (<div>,<p>) 切分。 - 代码: 利用类、函数定义进行切分。
- 适用场景: 结构化良好的文档(如技术手册、API 文档)。
4. 语义切分 (Semantic Chunking)
利用 NLP 模型理解文本含义,在“话题”或“语义”发生变化的地方进行切断(详见下文对比)。
5. 父子索引 / 小块检索大块生成 (Parent-Child / Small-to-Big)
这是一种高级策略,不是单纯的切分方式,而是索引方式。
- 原理: 将文档切分成极小的块(Child chunks)用于检索,但每个小块都链接到一个更大的父块(Parent chunk)。检索时匹配小块,但送给 LLM 的是父块。
- 适用场景: 需要精准定位细节,但回答问题需要宏观上下文的场景。
6. 命题切分 (Propositional Chunking)
利用 LLM 将复杂的长句拆解为多个独立的、包含完整上下文的简单陈述句(命题)。
- 适用场景: 文本非常密集、逻辑复杂,且需要极高检索精度的场景。
二、 固定大小切分 vs. 语义切分
这是“机械式处理”与“智能处理”的区别。
1. 核心区别 (Core Differences)
| 维度 | 固定大小切分 (Fixed-size) | 语义切分 (Semantic Chunking) |
|---|---|---|
| 切分依据 | 计数:字符数或 Token 数。 | 含义:基于 Embedding(向量)的相似度变化。 |
| 边界判定 | 硬性截断(可能切在句子中间)。 | 动态判定(切在语义转折点)。 |
| 计算成本 | 极低:无需模型推理,CPU 即可完成。 | 较高:需要 Encoder 模型计算句子的向量。 |
| 上下文完整性 | 较差,依赖 Overlap 补救。 | 较好,同义群组(Topic)会被保留在一起。 |
2. 工作原理对比
固定大小切分:
- 设定
Chunk Size = 100,Overlap = 20。 - 程序数到第 100 个字,直接切一刀。
- 问题: 可能会把“我喜欢吃...”和“...苹果”切到两个不同的块里,导致检索“苹果”时找不到“我喜欢”这个主语。
- 设定
语义切分:
- 第一步: 将文本按句子分割。
- 第二步: 使用 Embedding 模型计算相邻句子的余弦相似度。
- 第三步: 设定阈值(Threshold)。如果 句子A 和 句子B 的相似度很高,说明它们在讲同一件事,就合并;如果相似度突然下降(例如从 0.8 降到 0.3),说明话题变了,就在这里切一刀。
- 结果: 介绍“公司历史”的段落会被归为一个块,介绍“产品功能”的段落会被归为另一个块,即使它们的长度完全不同。
3. 优缺点深度分析
固定大小切分 (Fixed-size)
- 优点:
- 速度极快,适合处理海量数据。
- 结果可预测,块的大小均匀(利于向量数据库存储)。
- 缺点:
- 语义断裂:容易切断逻辑链条。
- 噪音:为了包含完整信息,往往需要设置较大的 Overlap,导致存储冗余。
语义切分 (Semantic Chunking)
- 优点:
- 检索更精准:因为每个块内部的语义是高度内聚的,向量表示更纯净,检索时的匹配度更高。
- 上下文完整:LLM 接收到的上下文是逻辑完整的片段,减少幻觉。
- 缺点:
- 慢且贵:需要对全文档做推理,构建索引的时间显著增加。
- 参数难调:相似度阈值(Threshold)很难设定。阈值太高会导致块太碎,太低会导致块太大。
- 长尾问题:对于某些逻辑跳跃快或废话多的文本,效果可能不如预期。
三、 总结与建议
- 如果你的项目处于 POC(概念验证)阶段,或者数据量巨大且计算资源有限,请使用 递归字符切分(Recursive Character Chunking),它是固定大小切分的升级版,性价比最高。
- 如果你发现检索出来的块总是缺头少尾,或者包含多个不相关的主题导致 LLM 回答混乱,那么应该尝试 语义切分。
- 最佳实践: 很多高精度 RAG 系统会结合使用。例如,先用语义切分确定大致边界,再结合 Token 限制进行微调。