 播面
播面 RAG 主要解决了大模型的哪些核心痛点(如幻觉、知识过时、私有数据)?
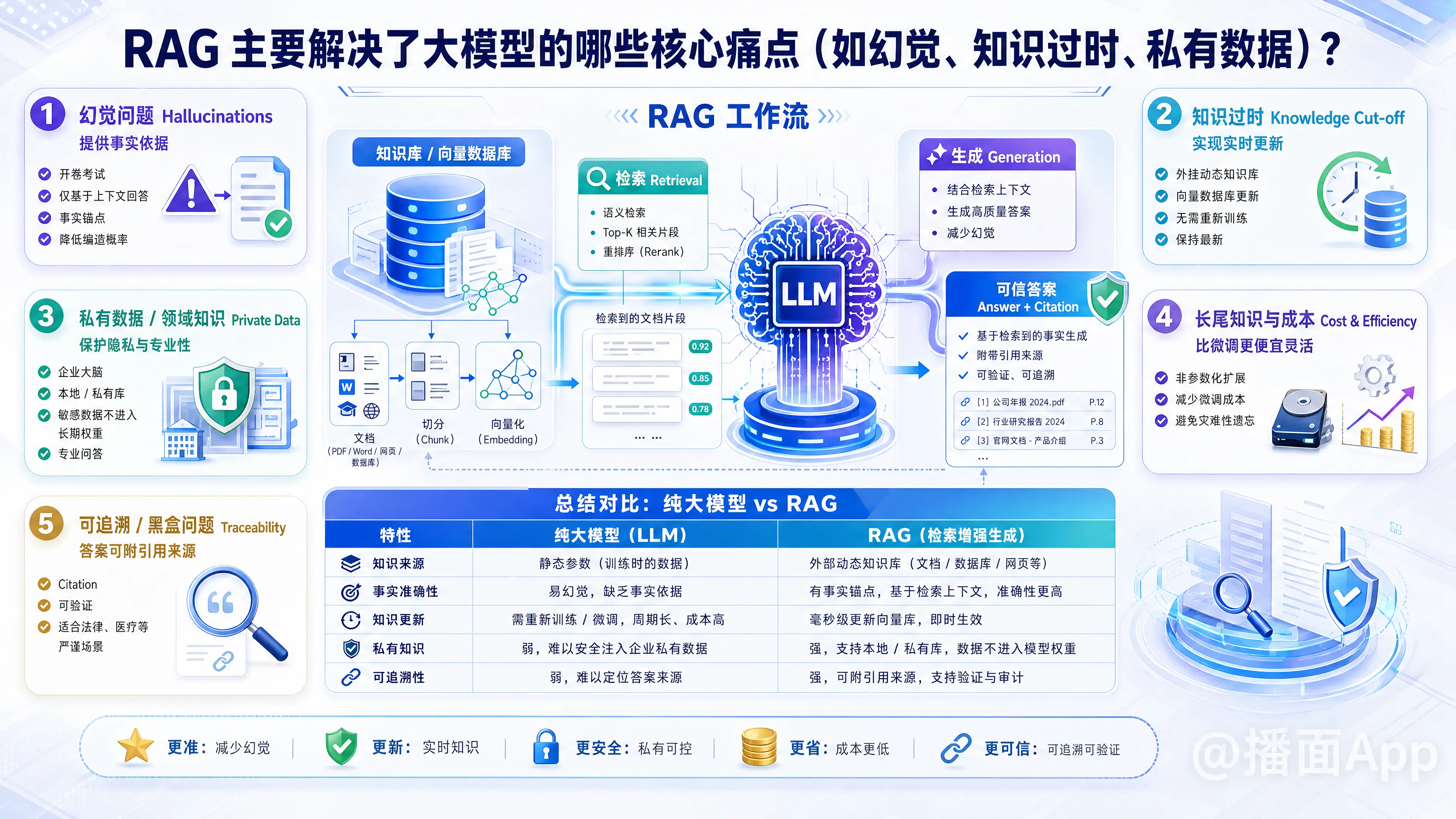
RAG(Retrieval-Augmented Generation,检索增强生成)确实是目前大模型(LLM)落地应用中最主流的技术架构。它通过在生成回答之前先从外部知识库中“检索”相关信息,再结合这些信息进行“生成”,巧妙地解决了大模型原生存在的几个核心痛点。
以下是 RAG 主要解决的三个核心痛点,以及两个额外的关键优势:
1. 解决“幻觉”问题 (Hallucinations) —— 提供事实依据
- 痛点: 大模型本质上是概率模型,它预测下一个字的概率,而不是像数据库一样存储确切的事实。当模型遇到它不知道的问题时,它倾向于一本正经地胡说八道(即“幻觉”),因为它优先保证语句通顺而非事实正确。
- RAG 的解法: “开卷考试”模式。
- RAG 强制模型在回答问题前,先阅读检索到的相关文档片段(Context)。
- 通过提示词(Prompt)约束,要求模型仅根据提供的上下文回答问题。
- 结果: 极大地降低了模型编造事实的概率,使回答具有了“事实锚点”(Grounding),提高了回答的准确性和可信度。
2. 解决“知识过时”问题 (Knowledge Cut-off) —— 实现实时更新
- 痛点: 大模型的训练成本极高且耗时,因此模型一旦训练完成,其参数就固定了。它的知识截止于训练数据的最后日期(Knowledge Cut-off)。例如,一个 2023 年初训练的模型不知道昨天发生的重大新闻。
- RAG 的解法: 外挂“动态知识库”。
- RAG 将知识存储在外部的向量数据库中,而不是模型的权重里。
- 当有新数据(新闻、新政策、新文档)产生时,只需将其更新到向量数据库中(成本极低,毫秒级更新)。
- 结果: 模型无需重新训练或微调,就能回答关于最新事件的问题,保持知识的实时性。
3. 解决“私有数据/领域知识缺失”问题 (Private Data) —— 保护隐私与专业性
- 痛点: 公共大模型(如 ChatGPT)是基于互联网公开数据训练的。它们不知道企业的内部文档(如 HR 手册、代码库、财务报表)或个人的私有笔记。同时,企业也不希望将敏感数据上传用于训练公有模型。
- RAG 的解法: 构建“企业大脑”。
- 企业可以将私有数据索引到本地或私有的向量数据库中。
- 当提问涉及内部知识时,RAG 系统从私有库中检索信息,仅将相关的片段作为上下文发送给大模型(甚至可以使用本地部署的大模型)。
- 结果: 既让大模型拥有了企业的“独家记忆”和专业领域知识,又在很大程度上规避了数据泄露风险(因为数据没有进入模型的长期记忆/权重中)。
除了上述三点,RAG 还解决了以下两个重要问题:
4. 解决“长尾知识与成本”问题 (Cost & Efficiency)
- 痛点: 如果想让模型学会某些长尾知识(很冷门的知识),使用微调(Fine-tuning)的方法不仅昂贵,而且容易导致“灾难性遗忘”(学会了新知识,忘了旧能力)。
- RAG 的解法: RAG 是一种非参数化的知识扩展方式。你不需要修改昂贵的模型参数,只需要增加存储空间(硬盘/数据库)。这比微调模型要便宜、灵活得多。
5. 解决“不可追溯/黑盒”问题 (Traceability/Interpretability)
- 痛点: 当大模型直接给出答案时,你不知道它是从哪里学来的,无法验证真伪。
- RAG 的解法: RAG 系统在检索时知道引用了哪几篇文章或段落。因此,生成的答案可以附带“引用来源”(Citation)。用户可以点击链接查看原文,验证答案的正确性,这对于医疗、法律等严谨场景至关重要。
总结对比
| 特性 | 纯大模型 (LLM) | RAG (检索增强生成) |
|---|---|---|
| 知识来源 | 训练时的内部参数(静态) | 内部参数 + 外部实时数据库 |
| 知识时效性 | 截止于训练结束日期 | 实时更新 |
| 私有数据支持 | 差(需微调,有泄露风险) | 极好(外挂知识库) |
| 幻觉程度 | 较高(不知道时会编造) | 较低(基于检索到的事实) |
| 可解释性 | 黑盒(无法溯源) | 透明(可提供引用来源) |
简单来说,如果把大模型比作一个超级学霸,RAG 就是给了这个学霸一本随时更新的参考书,并要求他必须翻书回答问题。