 播面
播面 如何降低 Agent 的响应延迟(Latency)?流式输出(Streaming)在 Agent 中如何实现?
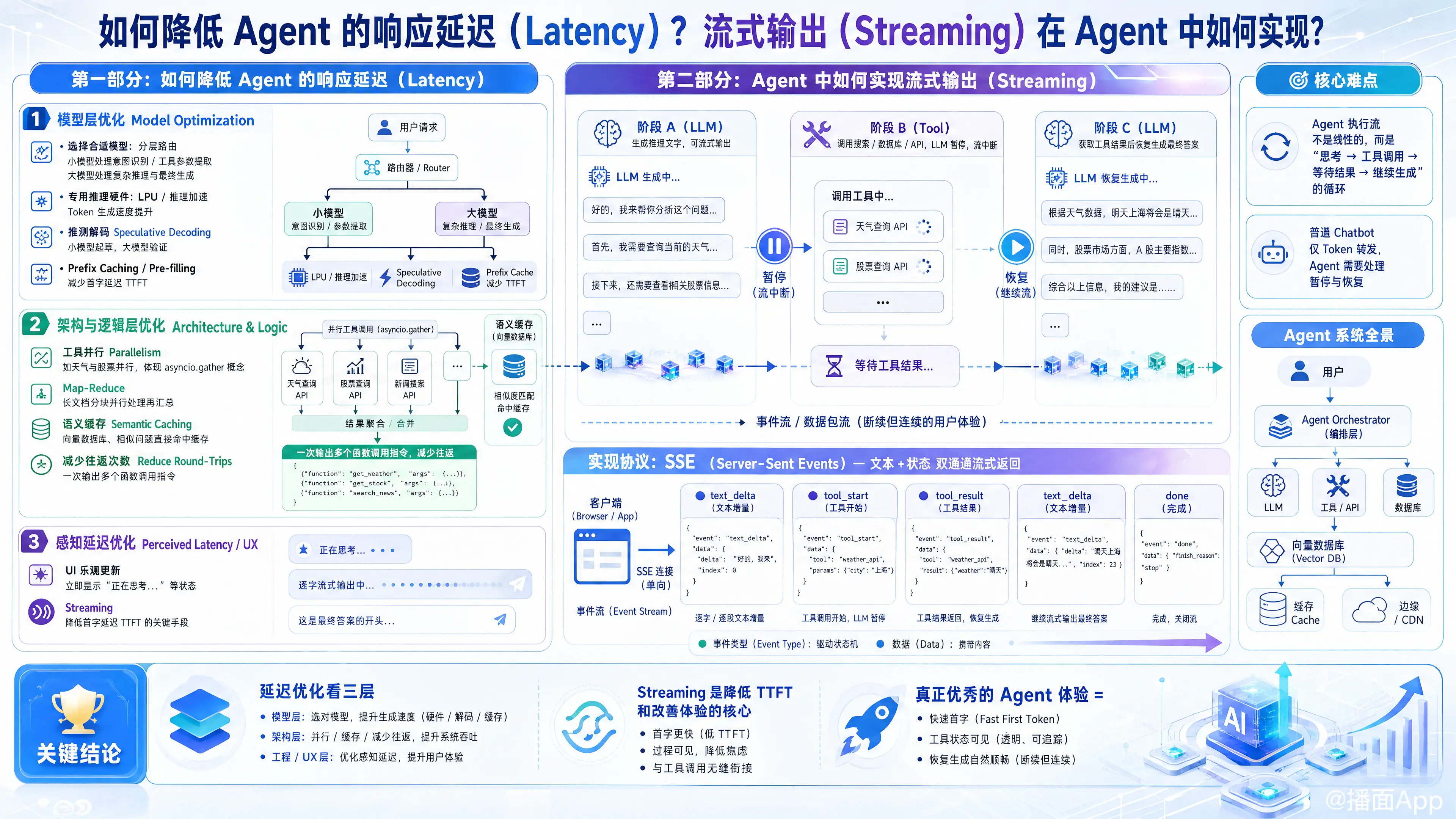
降低 Agent(智能体)的响应延迟并实现流畅的流式输出(Streaming),是提升 AI 应用用户体验(UX)最关键的两个环节。Agent 与普通 Chatbot 不同,它涉及“推理 -> 工具调用 -> 结果处理 -> 再推理”的循环,这使得延迟优化和流式传输变得更加复杂。
以下是详细的优化策略和技术实现方案:
第一部分:如何降低 Agent 的响应延迟 (Latency)
降低延迟通常从三个维度入手:模型层、架构层、工程层。
1. 模型层优化 (Model Optimization)
- 选择合适的模型 (Model Selection):
- 分层路由: 不要所有步骤都用 GPT-4。对于简单的意图识别或工具参数提取,使用 Llama 3 8B, Haiku, GPT-3.5 等小模型,仅在最终生成或复杂推理时使用大模型。
- 专用推理硬件: 考虑使用 Groq (LPU) 或 Sambanova 等推理加速服务,它们能将 Token 生成速度提高 10 倍以上。
- 推测解码 (Speculative Decoding):
- 使用一个小模型快速生成草稿,大模型仅负责验证。这可以显著提高 Token 生成速度。
- 预填充 (Prefix Caching / Pre-filling):
- 如果你的 System Prompt 或上下文很长,使用支持 Prefix Caching 的推理服务(如 Anthropic 或 DeepSeek),可以减少首字延迟(TTFT)。
2. 架构与逻辑层优化 (Architecture & Logic)
- 并行执行 (Parallelism):
- 工具并行: 如果 Agent 需要调用搜索天气和搜索股票,这两个动作应该并行(
asyncio.gather),而不是串行。 - Map-Reduce: 处理长文档时,分块并行处理,最后汇总。
- 工具并行: 如果 Agent 需要调用搜索天气和搜索股票,这两个动作应该并行(
- 语义缓存 (Semantic Caching):
- 在 LLM 之前加一层向量数据库(如 Redis + Vector)。如果用户问了类似的问题(语义相似度 > 0.95),直接返回缓存结果,跳过 LLM 和工具调用。
- 减少往返次数 (Reduce Round-Trips):
- 优化 Prompt,让模型一次性输出多个工具调用指令(Function Calling),而不是问一步走一步。
3. 感知延迟优化 (Perceived Latency - UX)
- UI 乐观更新: 用户输入后立即显示“正在思考...”,而不是留白。
- 流式输出(Streaming): 这是降低首字延迟 (Time to First Token, TTFT) 最有效的手段(详见下文)。
第二部分:Agent 中如何实现流式输出 (Streaming)
在普通 Chatbot 中,流式输出只是简单的 Token 转发。但在 Agent 中,流式输出非常困难,因为中间夹杂着“思考 -> 暂停去调工具 -> 等待结果 -> 继续生成”的过程。
1. 核心难点
Agent 的执行流不是线性的,而是断续的。
- 阶段 A (LLM): 生成推理:“我需要查一下 Google。” -> (流式输出)
- 阶段 B (Tool): 执行 Google 搜索 -> (此时 LLM 停止生成,流中断)
- 阶段 C (LLM): 根据搜索结果生成最终答案 -> (恢复流式输出)
2. 实现协议:Server-Sent Events (SSE)
HTTP 标准的 SSE 是实现流式输出的最佳选择。你需要定义一套事件协议,不仅仅传输文本,还要传输状态。
建议的数据结构 (JSON Chunk):
json
// 1. 文本增量事件
{ "type": "delta", "content": "北" }
{ "type": "delta", "content": "京" }
// 2. 状态/工具事件
{ "type": "tool_start", "tool_name": "weather_api", "input": "Beijing" }
{ "type": "tool_end", "output": "25°C" }
// 3. 错误或结束事件
{ "type": "error", "message": "API timeout" }
{ "type": "done" }3. 代码实现思路 (Python 伪代码)
假设不使用 LangChain 等框架,手写一个 Generator 来实现 Agent 流式输出:
python
import json
import time
# 模拟 LLM 流式生成
def llm_stream(prompt):
# 实际场景调用 OpenAI stream=True
response = ["我", "正在", "查询", "天气", "..."]
for token in response:
yield token
time.sleep(0.1)
# 模拟工具调用
def call_weather_tool(city):
time.sleep(1) # 模拟网络延迟
return f"{city} 天气晴朗"
# Agent 的核心流式生成器
def agent_stream_generator(user_query):
# 1. 第一阶段:思考与规划
# 此时 LLM 可能会输出一些“思考过程”
yield json.dumps({"type": "delta", "content": "收到,正在为您"}) + "\n"
yield json.dumps({"type": "delta", "content": "处理..."}) + "\n"
# 2. 决策阶段:模型决定调用工具
# 告诉前端:我要开始调工具了,请显示加载动画
yield json.dumps({
"type": "tool_start",
"tool": "weather_api",
"args": {"city": "Shanghai"}
}) + "\n"
# 执行工具(这是同步或异步阻塞的)
tool_result = call_weather_tool("Shanghai")
# 告诉前端:工具调完了
yield json.dumps({
"type": "tool_end",
"result": tool_result
}) + "\n"
# 3. 最终响应阶段:把工具结果喂给 LLM,流式输出最终答案
final_prompt = f"用户问: {user_query}, 工具结果: {tool_result}, 请回答。"
for token in llm_stream(final_prompt):
# 封装成前端能懂的格式
yield json.dumps({"type": "delta", "content": token}) + "\n"
# Flask/FastAPI 接口
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
app = FastAPI()
@app.get("/chat")
async def chat(query: str):
return StreamingResponse(
agent_stream_generator(query),
media_type="text/event-stream"
)4. 框架实现 (LangChain / Vercel AI SDK)
如果你使用框架,它们通常已经封装好了这种复杂的流式逻辑。
LangChain (
astream_events):
LangChain 的Runnable协议支持astream_eventsv2 API。它可以自动区分是on_chat_model_stream(文本生成) 还是on_tool_start(工具调用)。pythonasync for event in agent.astream_events(inputs, version="v2"): kind = event["event"] if kind == "on_chat_model_stream": # 发送文本 token print(event["data"]["chunk"].content, end="|") elif kind == "on_tool_start": # 发送工具状态 print(f"\n[正在调用工具: {event['name']}]")Vercel AI SDK (Next.js):
如果你做全栈开发,Vercel AI SDK 的StreamData可以在流式文本之外,附加额外的数据(如工具调用信息)。javascript// 前端接收时,会自动处理文本流和 Data 流的合并 const { messages, data } = useChat();
总结
- 降延迟: 优先用小模型做路由,用并行做工具调用,用语义缓存挡请求。
- 流式输出: 必须建立事件驱动的思维。不要只流式传输文本,要流式传输“状态”(Thinking, Tool Calling, Final Answer)。使用 SSE 协议配合 JSON 结构化数据是目前的行业标准。