 播面
播面 Python 的内存管理机制
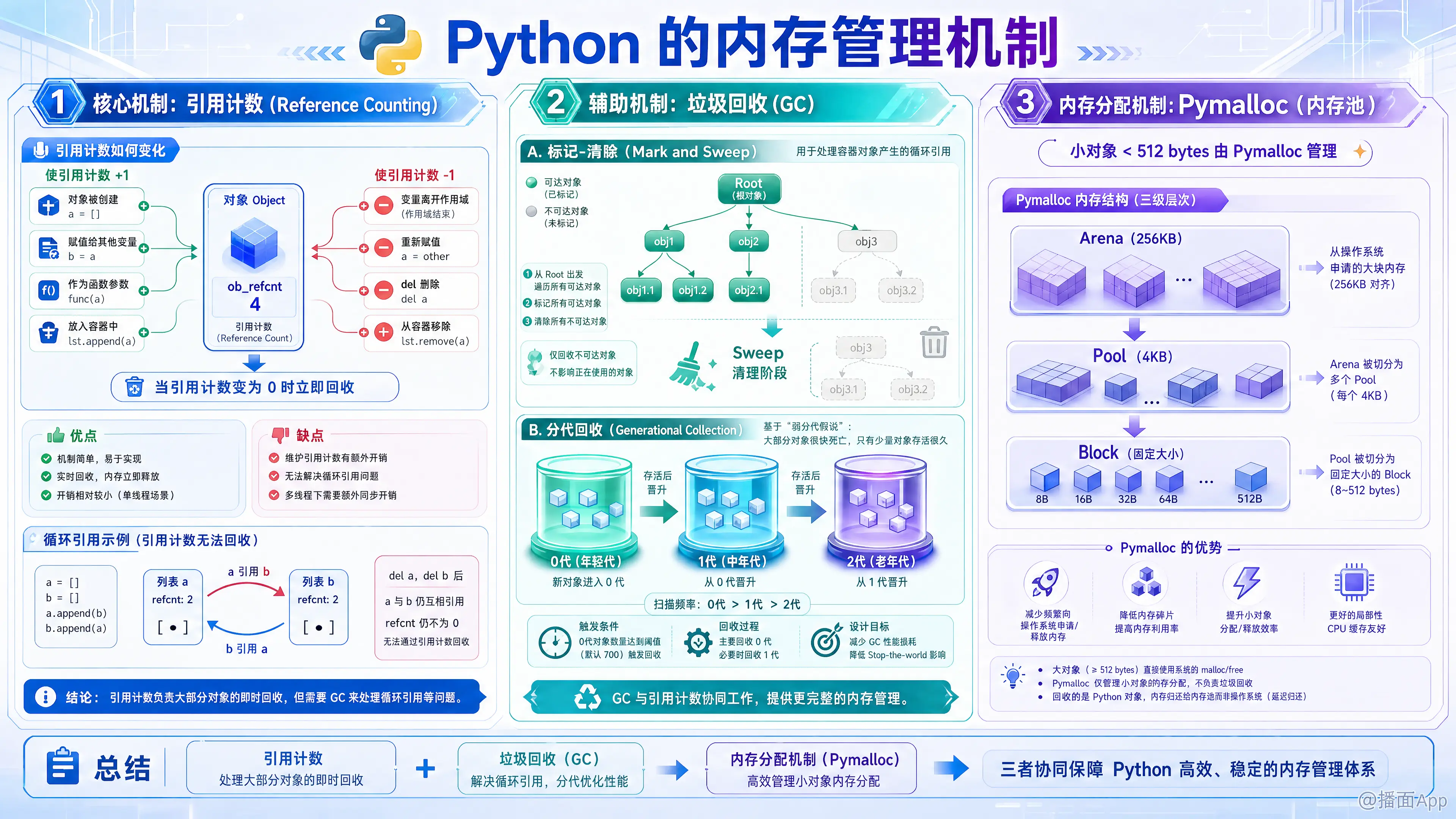
Python 的内存管理机制是一个非常高效且复杂的系统,简单来说,它采用了 “引用计数为主,标记-清除和分代回收为辅” 的策略,并结合了 特有的内存池机制 来优化小对象的分配。
下面我们将从三个核心维度深入剖析:
1. 核心机制:引用计数 (Reference Counting)
这是 Python 内存管理的基础。Python 中的每个对象都有一个 ob_refcnt 字段,用于记录有多少个变量引用了该对象。
工作原理:
- 增加引用 (+1): 对象被创建(
a = [1])、被赋值给其他变量(b = a)、作为参数传递给函数、或被放入容器(如列表、字典)中。 - 减少引用 (-1): 变量离开作用域、变量被赋值为其他对象、使用
del显式删除、或从容器中移除。 - 回收: 当一个对象的引用计数变为 0 时,Python 会立即回收该对象的内存。
- 增加引用 (+1): 对象被创建(
优点: 简单、实时性高(一旦不用立即回收)。
缺点:
- 维护引用计数需要消耗资源。
- 无法解决循环引用 (Cyclic Reference) 问题。
循环引用示例:
pythona = [] b = [] a.append(b) # a 引用 b b.append(a) # b 引用 a del a del b即使执行了
del,a 和 b 的引用计数仍然是 1(互相引用),导致内存无法通过引用计数机制释放。这就是为什么需要垃圾回收机制。
2. 辅助机制:垃圾回收 (Garbage Collection, GC)
为了解决循环引用的问题,Python 引入了垃圾回收机制,主要包含 标记-清除 和 分代回收。
A. 标记-清除 (Mark and Sweep)
主要用于解决容器对象(List, Dict, Tuple, Class等)产生的循环引用。
- 原理: GC 算法会从“根对象”(Root,如全局变量、栈中的变量)出发,遍历所有能访问到的对象并打上标记(Mark)。遍历结束后,没有被标记的对象就是不可达对象,会被清除(Sweep)。
B. 分代回收 (Generational Collection)
基于“弱代假说”(大部分对象都是“朝生夕死”的),Python 将对象分为三代:0代、1代、2代。
0代 (Generation 0): 新创建的对象都会放入 0 代。
1代 (Generation 1): 如果 0 代经历了一次 GC 扫描后依然存活,它就会被移入 1 代。
2代 (Generation 2): 同理,1 代中存活的对象会移入 2 代。
策略:
- GC 扫描频率:0代 > 1代 > 2代。
- 当 0 代对象数量达到阈值(默认 700 个)时,触发 0 代回收。
- 随着代数增加,回收的频率降低,从而减少 GC 带来的性能损耗(Stop-the-world)。
3. 内存分配机制:Pymalloc (内存池)
为了避免频繁地向操作系统申请和释放内存(这很慢且容易造成内存碎片),Python 引入了一个内存池机制,名为 Pymalloc。
Python 将内存分配分为两类:
A. 小对象 (< 512 bytes)
使用 Pymalloc 管理。Python 会预先向操作系统申请一大块内存,自己管理。
- 结构层级:
- Arena (256KB): 直接向系统申请的大块内存。
- Pool (4KB): 一个 Arena 包含多个 Pool。
- Block: 一个 Pool 被切分成固定大小的 Block(如 8字节、16字节...)。对象直接存储在 Block 中。
- 优势: 极大地提高了小对象的分配和释放速度,减少了内存碎片。
B. 大对象 (> 512 bytes)
直接调用系统的 C 语言标准库函数 malloc() 和 free() 进行分配和释放。
4. 特殊优化机制
为了进一步节省内存,Python 对某些特定的不可变对象进行了缓存(Interning):
- 小整数池: Python 启动时会自动创建范围在
[-5, 256]之间的整数对象。这些数字在内存中是全局唯一的,不会被回收。pythona = 100 b = 100 print(a is b) # True - 字符串驻留 (String Interning): 只有包含字母、数字、下划线的短字符串会被缓存。相同的字符串变量指向同一个内存地址。
总结图解
当你创建一个对象时,Python 的处理流程如下:
- 判断大小:
- 大对象 -> 找操作系统要内存 (
malloc)。 - 小对象 -> 找 Python 内存池要内存 (
pymalloc)。
- 大对象 -> 找操作系统要内存 (
- 使用过程:
- 通过 引用计数 监控对象生命周期。
- 销毁过程:
- 引用计数归零 -> 立即回收(归还给内存池或操作系统)。
- 引用计数不为零但不可达(循环引用) -> 等待 分代垃圾回收 扫描发现并清除。
开发者注意事项
- 手动回收: 一般不需要。如果内存占用极高,可以使用
gc.collect()强制回收,或手动del大变量。 - 避免循环引用: 虽然有 GC,但 GC 有延迟且消耗性能。尽量避免复杂的对象互相引用,或者使用
weakref(弱引用) 来打破循环。