 播面
播面 RLHF模型为什么比SFT表现更好?Agent训练中有何优势?
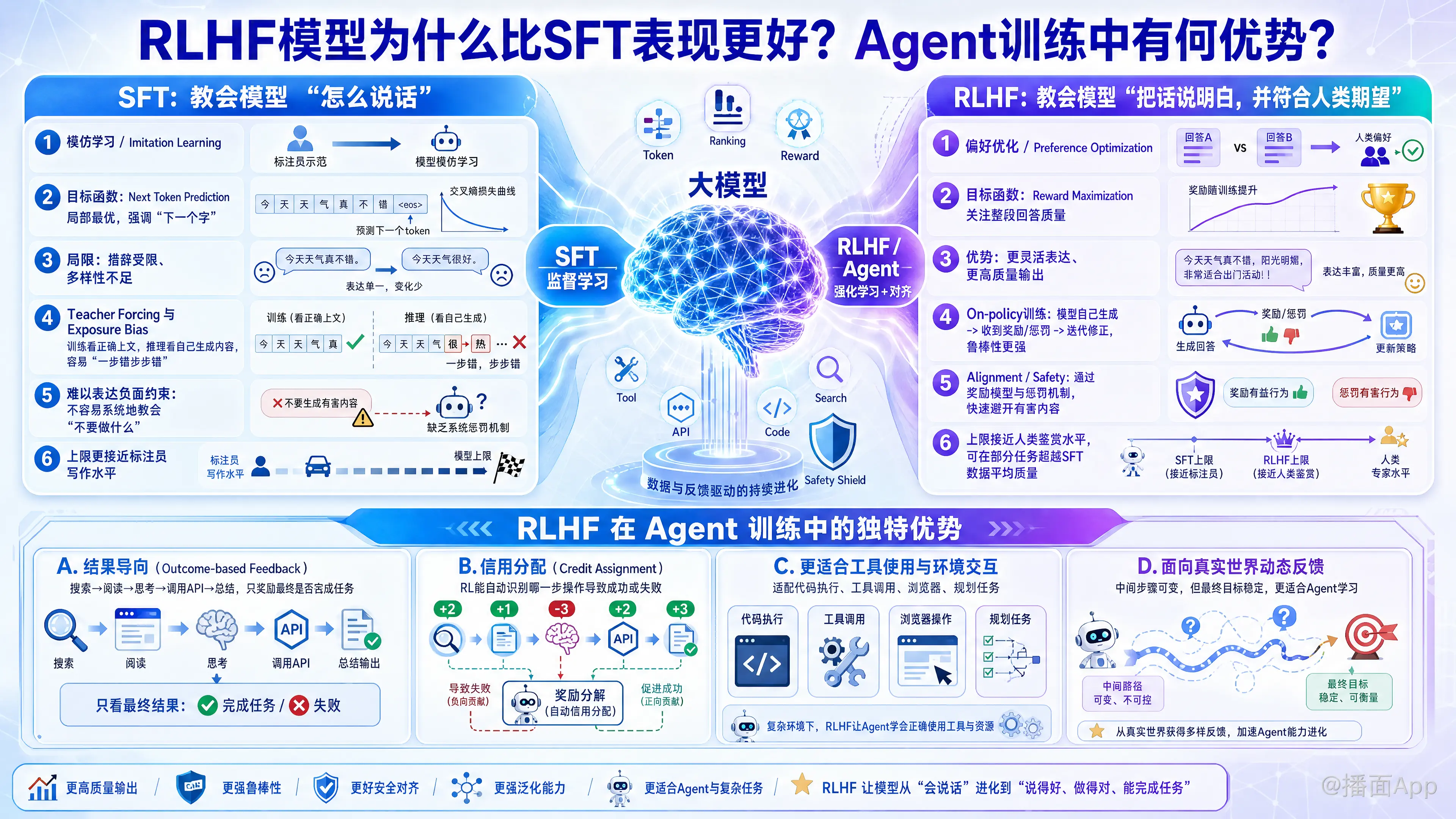
这是一个非常深刻且触及大模型(LLM)核心训练机制的问题。简单来说,SFT(有监督微调)教会模型“怎么说话”,而RLHF(基于人类反馈的强化学习)教会模型“怎么把话说明白、说得符合人类期望”。
以下从通用模型表现和Agent(智能体)训练两个维度深入解析。
第一部分:为什么 RLHF 比 SFT 表现更好?
SFT 的本质是模仿学习(Imitation Learning),而 RLHF 的本质是偏好优化(Preference Optimization)。RLHF 之所以能超越 SFT,主要解决了 SFT 的几个核心缺陷:
1. 目标函数的差异:局部 vs. 全局
- SFT (Next Token Prediction): SFT 的损失函数是交叉熵(Cross-Entropy)。它只关注下一个字预测得准不准。只要模型预测的字和训练数据不一样,哪怕意思完全相同,也会受到惩罚。
- 弊端: 这限制了模型的多样性,迫使模型死记硬背训练数据的特定措辞。
- RLHF (Reward Maximization): RLHF 引入了奖励模型(Reward Model)。它关注的是整段回答的质量(是否有用、安全、逻辑通顺)。
- 优势: 只要最终生成的答案质量高,中间用什么词、什么句式,RLHF 并不强制限制。这让模型能探索出比 SFT 数据集更好的表达方式。
2. 解决“分布偏移”与“暴露偏差” (Exposure Bias)
- SFT 的问题: 在训练时,SFT 使用“Teacher Forcing”模式(即模型每一步都看到正确的上文)。但在推理(测试)时,模型只能看到自己生成的上文。一旦模型在开头犯了一个小错,因为没见过这种错误路径,SFT 模型往往会“一步错,步步错”,产生幻觉或胡言乱语。
- RLHF 的优势: RLHF 是在模型自己生成的内容上进行训练的(On-policy)。模型在训练过程中会经历“犯错 -> 收到低分 -> 修正”的过程。因此,RLHF 训练出的模型具有更强的鲁棒性,即使前面生成得不够完美,它也有能力自我纠正,或者在后续生成中挽回局面。
3. 更好地处理“负面约束” (Alignment)
- SFT 的局限: 很难通过 SFT 教会模型“不要做什么”。例如,要教会模型“不要种族歧视”,你很难构建一个全是“非种族歧视”的数据集来覆盖所有情况。
- RLHF 的优势: 强化学习非常擅长处理惩罚。如果模型生成了有毒内容,Reward Model 给予一个极大的负分,模型会迅速学会避开这些高风险区域。这是 RLHF 在安全性(Safety)和对齐(Alignment)上表现优异的关键。
4. 超越人类标注员的平均水平
- SFT 的上限是标注员的写作水平。
- RLHF 的上限是标注员的鉴赏水平。
- 例子: 写一首完美的诗很难(SFT 数据难做),但判断哪首诗写得好很容易(RM 数据好做)。RLHF 允许模型通过尝试不同的路径来获得高分,从而在某些任务上产生超越 SFT 训练数据的表现。
第二部分:RLHF 在 Agent(智能体)训练中的独特优势
在 Agent 场景下(如调用工具、多步推理、写代码执行),RLHF(以及更广泛的 RL)的优势比在纯对话场景下更加显著。
1. 结果导向 vs. 过程导向 (Outcome-based Feedback)
Agent 的任务通常是多步的(例如:搜索 -> 阅读 -> 思考 -> 调用API -> 总结)。
- SFT 的困境: 需要标注员一步步写出完美的中间步骤(Chain of Thought)。如果中间某一步 API 返回的结果变了,SFT 的数据就失效了。
- RL 的优势: 我们可以只奖励最终结果。例如,“帮我订一张票”,只要最终票订成功了,给予正向奖励;失败了,给予负向奖励。RL 算法会自动进行信用分配(Credit Assignment),推断出是哪一步操作导致了成功或失败。
2. 探索未知路径 (Exploration)
- Agent 需要在复杂的环境中找到最优解。SFT 只能教模型走“人类演示过的那条路”。
- RL 允许 Agent 进行探索(Exploration)。Agent 可能会发现一种人类标注员没想到的工具组合方式,或者一种更高效的代码写法,能更快解决问题。DeepSeek-R1 等推理模型之所以强大,正是因为通过 RL 探索出了人类未曾演示过的思维链路径。
3. 整合非对齐的反馈信号 (Environment Feedback)
Agent 训练不仅仅依赖人类反馈(RLHF),更多依赖环境反馈(RLEF - RL from Environmental Feedback)。
- 代码解释器: 代码能否运行?是否报错?
- API 调用: 返回状态码是 200 还是 404?
- 数学题: 最终答案对不对?
这些信号是离散的、不可导的,无法直接用于 SFT 的反向传播,但天然适合作为 RL 的 Reward 信号。这使得 Agent 可以通过大量的自我博弈和试错来进化。
4. 解决长程推理的误差累积
Agent 的任务链路通常很长。
- 在 SFT 中,第一步推理的微小误差会被放大,导致第十步完全偏离目标。
- RL 训练通常针对整个 Trajectory(轨迹)进行优化。它训练模型在做第一步决策时,就考虑到这一步对第十步结果的影响(通过 Value Network 预估未来收益)。这极大地提高了 Agent 完成复杂长任务的成功率。
总结
- SFT 是“填鸭式教育”: 老师写在黑板上,学生死记硬背。学生能学会基础知识,但不懂变通,且容易学到老师的坏习惯。
- RLHF 是“启发式教育”: 学生自己做题,老师只打分(对/错/好/坏)。学生为了拿高分,会自己琢磨解题思路,甚至找出比老师更好的解法。
在 Agent 领域,因为环境复杂、步骤繁多且标准答案不唯一,RL(RLHF/RLEF)提供的“试错探索”和“结果导向”机制,是实现高水平智能体的必经之路。