 播面
播面 KV Cache技术在Agent推理中如何应用?
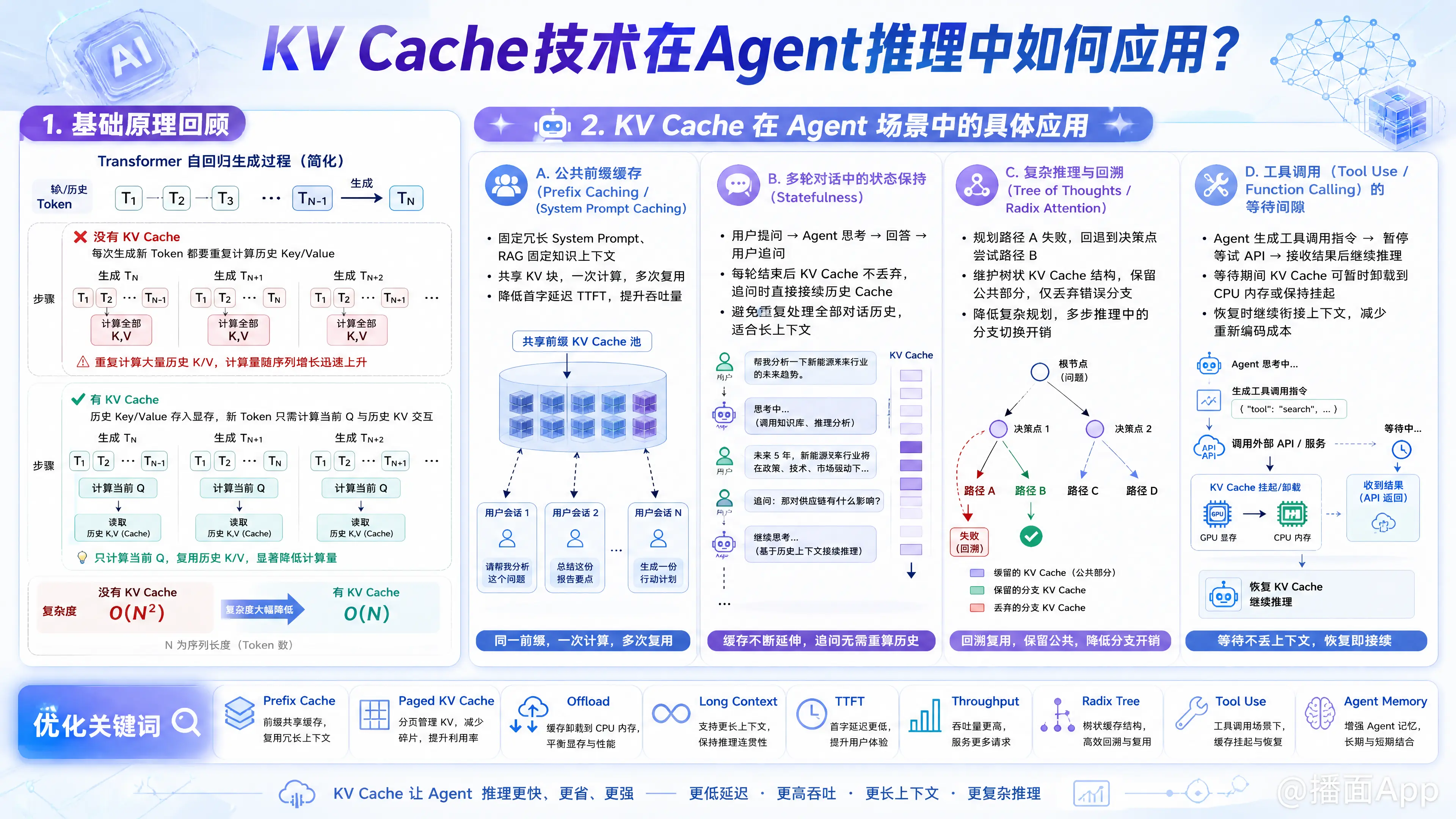
KV Cache(Key-Value Cache)技术是现代大语言模型(LLM)推理加速的核心手段。在 AI Agent(智能体) 的场景中,由于Agent通常涉及多轮对话、复杂的System Prompt、工具调用(Tool Use)以及长上下文推理,KV Cache的应用显得尤为关键。
以下是KV Cache技术在Agent推理中的具体应用方式和优化策略:
1. 基础原理回顾
在Transformer架构的自回归(Autoregressive)生成过程中,每生成一个新的Token,都需要计算它与之前所有Token的注意力机制(Attention)。
- 没有KV Cache: 每次生成新Token,都要重新计算之前所有Token的Key和Value矩阵,计算量随序列长度呈平方级增长。
- 有KV Cache: 将之前计算过的Key和Value向量存储在显存中,生成新Token时只需计算当前的Q与历史KV的交互。这极大地减少了计算量,将推理复杂度从 降为 。
2. KV Cache 在 Agent 场景中的具体应用
A. 公共前缀缓存(Prefix Caching / System Prompt Caching)
这是Agent场景中最具价值的应用之一。
- 场景: 大多数Agent都有一个固定的、冗长的System Prompt(例如:“你是一个专业的代码助手,可以使用以下工具...”),或者在RAG场景中有一段固定的知识库上下文。
- 应用:
- 共享KV块: 推理引擎(如vLLM、SGLang)识别出不同请求中相同的System Prompt部分。
- 一次计算,多次复用: 系统只需计算一次System Prompt的KV Cache,并将其驻留在显存中。当成千上万个用户与同一个Agent交互时,直接复用这部分Cache,无需重复计算。
- 效果: 显著降低了首字延迟(TTFT, Time To First Token),并大幅提升了吞吐量。
B. 多轮对话中的状态保持(Statefulness)
Agent的核心是多轮交互(Memory)。
- 场景: 用户提问 -> Agent思考 -> Agent回答 -> 用户追问。
- 应用:
- 在每一轮对话结束后,推理引擎不会立即丢弃当前的KV Cache。
- 当用户进行追问时,系统将新的输入(User Prompt)拼接到历史Cache之后继续生成。
- 这避免了Agent每次回答都要重新处理整个历史对话记录(Re-computation),对于长上下文Agent至关重要。
C. 复杂推理与回溯(Tree of Thoughts / Radix Attention)
高级Agent往往采用“思维树”(Tree of Thoughts)或多次尝试(Self-Consistency)策略。
- 场景: Agent在规划路径A时发现走不通,需要回退到决策点,尝试路径B。
- 应用(Radix Attention):
- 推理引擎维护一个KV Cache的树状结构(Radix Tree)。
- 当Agent回退时,系统自动匹配到决策分叉点的KV Cache节点,保留公共部分的Cache,只丢弃错误路径的Cache。
- SGLang 等框架利用此技术,使得Agent在进行复杂规划和多步推理时,切换分支的开销极低。
D. 工具调用(Tool Use / Function Calling)的等待间隙
- 场景: Agent生成“调用天气API”的指令 -> (暂停推理,等待外部API返回) -> 接收API结果 -> 继续推理。
- 应用:
- 在等待外部工具执行期间,GPU显存中的KV Cache可以被暂时“卸载”(Offload)到CPU内存,或者如果显存充足则保持挂起(PagedAttention机制)。
- 一旦工具返回结果,系统迅速重新加载或激活之前的KV Cache,拼接上工具返回的结果继续生成。这比重新输入整个上下文要快得多。
3. 针对 Agent 的 KV Cache 优化技术
由于Agent通常伴随着超长的上下文(Long Context),KV Cache会占用巨大的显存(显存墙问题),以下技术用于解决这一瓶颈:
A. PagedAttention (分页注意力)
- 原理: 受到操作系统虚拟内存管理的启发,将KV Cache切分成固定大小的块(Block),非连续地存储在显存中。
- Agent收益: 减少了显存碎片,允许更大的Batch Size,使得单个GPU能同时服务更多的Agent实例。
B. KV Cache Quantization (量化)
- 原理: 将KV Cache的数据精度从FP16(16位)降低到INT8(8位)甚至FP4(4位)。
- Agent收益: 直接将显存占用减半或更多。这对于需要处理 100k+ Token 上下文的Agent(如阅读整本书进行分析的Agent)是必须的,否则显存会瞬间溢出。
C. 混合存储与层级缓存 (Tiered Caching)
- 原理: GPU显存 <-> CPU内存 <-> NVMe SSD。
- Agent收益: 对于不活跃的Agent会话,将其KV Cache换出到CPU内存;当用户再次激活Agent时,快速换入。这使得单卡可以支持无限长度的Agent会话(仅受限于磁盘速度)。
D. 滑动窗口与驱逐策略 (Eviction Policies)
- 原理: 像StreamingLLM或H2O (Heavy Hitter Oracle) 算法,只保留最近的Token和最重要的“注意力汇聚点”(Attention Sinks)的KV Cache。
- Agent收益: 允许Agent进行无限轮次的对话,而KV Cache的大小保持恒定,不会随对话长度无限增长。
4. 总结
在Agent推理中,KV Cache 不仅仅是一个底层的加速技巧,它是实现高性能、低延迟、低成本Agent的关键基础设施。
- 对于开发者: 选择支持 Prefix Caching 和 PagedAttention 的推理后端(如 vLLM, TGI, LMDeploy)是构建生产级Agent的首要步骤。
- 对于架构设计: 需要根据Agent的System Prompt长度和平均对话轮数,合理规划显存容量和KV Cache的驱逐策略。