 播面
播面 MHA/GQA/MQA三种注意力机制在Agent场景下的选择策略
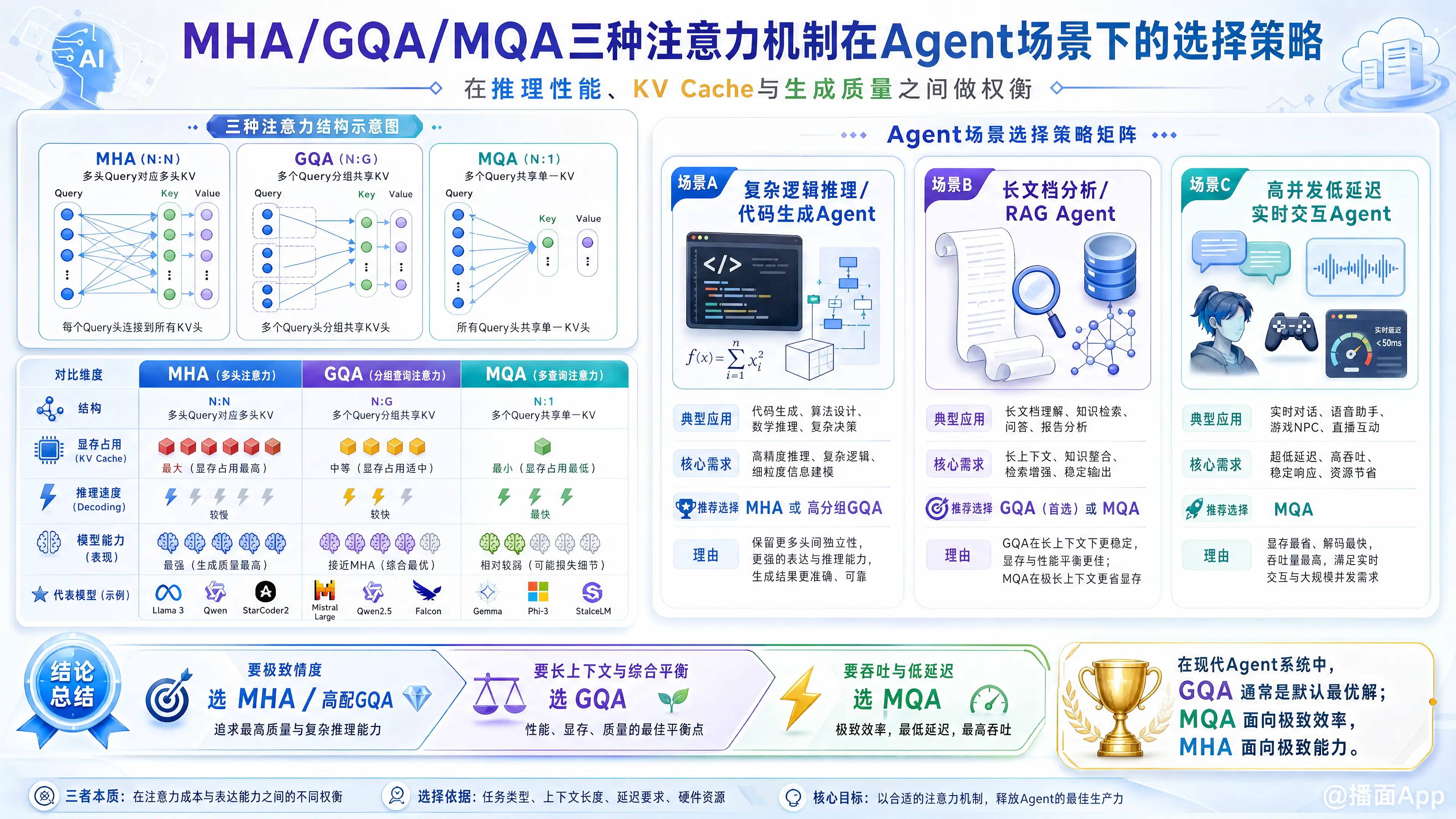
在构建基于大语言模型(LLM)的 Agent(智能体) 系统时,选择哪种注意力机制(MHA、GQA、MQA)主要取决于推理性能(Latency/Throughput)、显存占用(KV Cache)与模型生成质量(Accuracy)之间的权衡。
Agent 场景通常涉及多轮对话、长上下文(RAG)、工具调用(Tool Use)和复杂推理,这使得推理效率尤为关键。
以下是针对 MHA、GQA、MQA 在 Agent 场景下的详细选择策略:
1. 机制简述与核心差异
| 特性 | MHA (Multi-Head Attention) | GQA (Grouped-Query Attention) | MQA (Multi-Query Attention) |
|---|---|---|---|
| 结构 | Query 头数 = KV 头数 () | Query 头数 > KV 头数 (分组共享, ) | 只有 1 个 KV 头 () |
| 显存占用 (KV Cache) | 极大 | 中等 (约为 MHA 的 ) | 极小 (约为 MHA 的 ) |
| 推理速度 (Decoding) | 慢 (受限于内存带宽) | 快 | 极快 |
| 模型能力 (表现) | 最强 (细节捕捉最好) | 接近 MHA | 略有下降 (信息有损) |
| 代表模型 | GPT-2, BERT, Llama-1 | Llama-2/3, Mistral, Qwen | Falcon, StarCoder |
2. Agent 场景下的选择策略矩阵
场景 A:极度依赖复杂逻辑推理与代码生成的 Agent
- 典型应用:全自动代码工程师(Devin类)、复杂数学解题 Agent、科研推理 Agent。
- 需求:模型需要捕捉 Query 和 Key 之间最细微的关联,容错率极低。
- 推荐选择:MHA 或 GQA (High Group Count)
- 理由:
- MHA 提供最强的表达能力,确保在复杂的 Prompt 和多步推理中不丢失细节。
- 如果模型参数量较小(如 7B 以下),MHA 的显存开销可以接受,优先保质量。
- 注:目前主流高性能模型(如 Llama 3)已证明 GQA 能在几乎不损失精度的情况下替代 MHA,因此纯 MHA 的新模型越来越少。
场景 B:长文档分析与 RAG(检索增强生成)Agent
- 典型应用:法律文档审查、金融研报分析、基于整个代码库的问答。
- 需求:超长上下文窗口(Long Context)。
- 推荐选择:GQA (首选) 或 MQA
- 理由:
- KV Cache 瓶颈:在长文本(如 128k context)下,MHA 的 KV Cache 会占据巨大的显存(甚至超过模型权重本身),导致 OOM(显存溢出)。
- GQA 能显著减少 KV Cache 大小,允许 Agent 加载更多的上下文历史,同时保持足够的注意力精度来提取文档中的具体事实。
- 如果是极端长文本(如 1M token)且资源受限,MQA 是唯一选择。
场景 C:高并发、低延迟的实时交互 Agent
- 典型应用:游戏 NPC、客户服务机器人、实时语音对话 Agent。
- 需求:极高的吞吐量(Throughput)和极低的首字延迟(TTFT)。
- 推荐选择:MQA
- 理由:
- MQA 只需要加载极少的 KV 数据,大幅降低了内存带宽的压力(Memory Bandwidth Bound)。
- 在 Batch Size 较大时,MQA 的推理速度优势巨大,适合同时服务成千上万用户的场景。
- 虽然 MQA 会牺牲少量精度,但在闲聊或简单任务执行中,这种损失通常是用户无感的。
场景 D:通用型任务处理 Agent (The "Sweet Spot")
- 典型应用:个人助理、任务规划器、工具调用 Router。
- 需求:在生成质量和部署成本之间取得平衡。
- 推荐选择:GQA (通常是 8 分组)
- 理由:
- 这是目前业界的黄金标准(Llama 3, Mistral 等均采用)。
- 它提供了接近 MHA 的智商,同时将推理速度和显存效率提升到了接近 MQA 的水平。
- 对于大多数企业级 Agent 部署,GQA 是最具性价比的选择。
3. 深度技术考量:KV Cache 对 Agent 的影响
Agent 与普通 Chatbot 最大的区别在于 System Prompt 往往很长(包含工具定义、Few-shot 示例、记忆),且经常处于 Loop(循环) 状态。
显存占用 (VRAM):
- 假设 Hidden Size = 4096, Layers = 32, Context = 8192, Batch = 1, FP16。
- MHA: KV Cache 约 4GB。
- GQA (8 groups): KV Cache 约 0.5GB。
- 结论:使用 GQA/MQA,你可以在单张显卡上运行更大参数的模型,或者支持更长的历史记录,这对 Agent 的“记忆力”至关重要。
Prefill 与 Decode 阶段:
- Agent 经常需要读取新的检索内容(Prefill),然后生成指令(Decode)。
- MQA/GQA 主要加速 Decode 阶段(生成 Token 时),因为此时受限于内存带宽加载 KV Cache 的速度。
- 如果你的 Agent 主要是“读多写少”(如阅读大量文本只输出
Yes/No),MHA 的劣势不明显;如果是“写多”(如生成长报告),必须上 GQA/MQA。
4. 总结建议
- 默认选择:GQA。如果你在训练或微调自己的 Agent 模型,GQA 是目前的 SOTA 选择(如 Llama 2/3 架构),它解决了 MHA 的显存问题,修复了 MQA 的精度问题。
- 极端性能优化:MQA。仅当你需要极致的并发(Batch Size > 64)或在端侧设备(手机/笔记本)上部署 Agent 时使用。
- 特定小模型/科研:MHA。仅在模型参数很小(< 3B)且上下文较短,同时对逻辑严密性要求极高时考虑。
一句话策略:在 Agent 场景下,为了支持更长的上下文记忆和更快的工具响应,应坚决抛弃 MHA,首选 GQA,在极端资源受限时下探至 MQA。