 播面
播面 如何通过 prompt 设计提升 Agent 的稳定性?
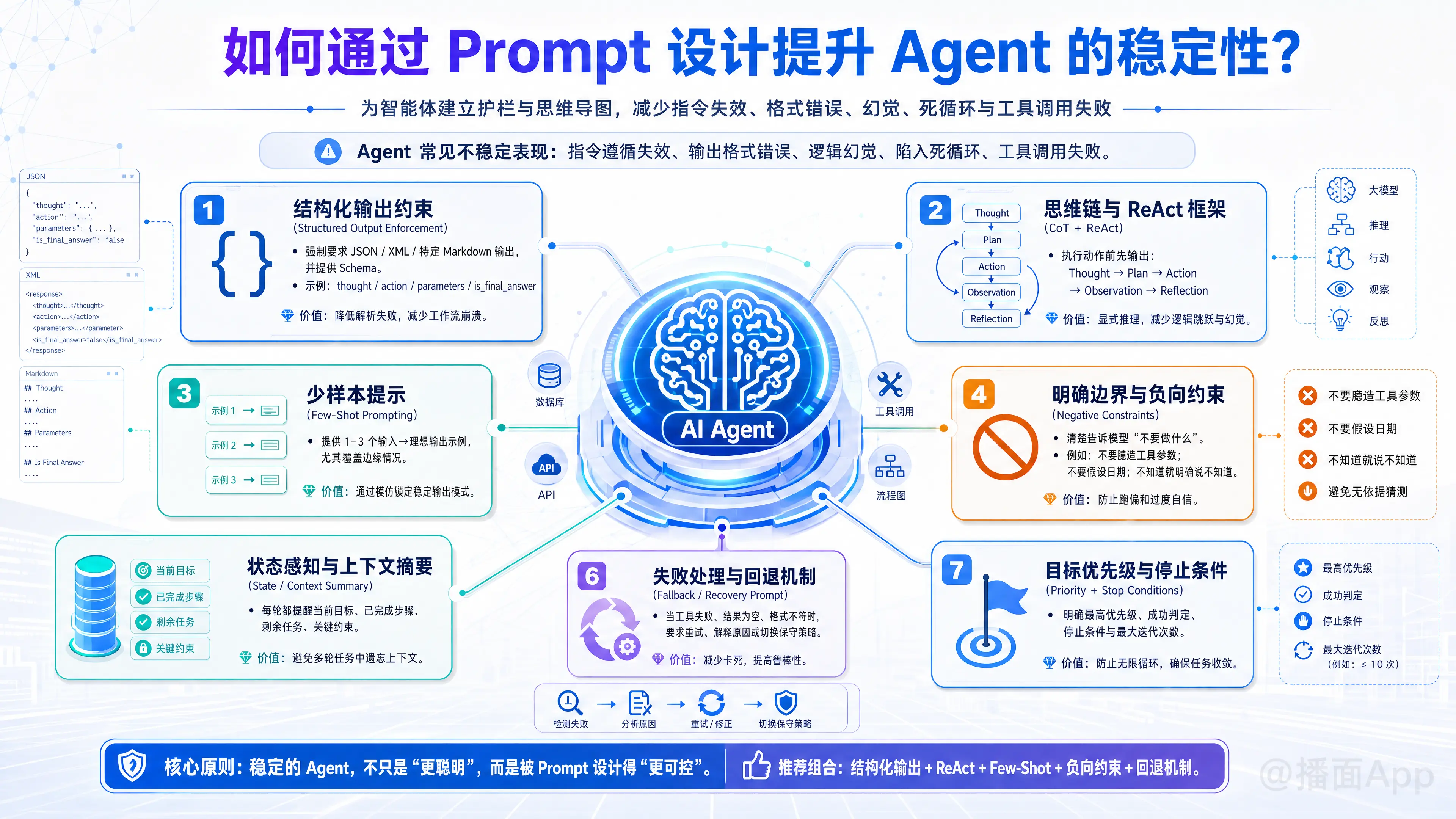
提升 Agent(智能体)的稳定性是当前大模型应用开发中的核心挑战。Agent 的“不稳定”通常表现为:指令遵循失效、输出格式错误、逻辑幻觉、陷入死循环或工具调用失败。
通过精心设计的 Prompt(提示词),可以显著为 Agent 建立“护栏”和“思维导图”。以下是提升 Agent 稳定性的 7 个核心 Prompt 设计策略:
1. 结构化输出约束 (Structured Output Enforcement)
Agent 通常需要与代码进行交互,如果输出格式混乱,整个工作流就会崩溃。
- 策略: 强制要求 JSON、XML 或特定的 Markdown 格式,并提供 Schema 定义。
- Prompt 示例:
你必须严格按照以下 JSON 格式输出,不要包含任何 markdown 标记或额外的解释文本:
json{ "thought": "你对当前任务的思考过程", "action": "调用的工具名称", "parameters": { "key": "value" }, "is_final_answer": boolean } - 原理: 降低了解析器的负担,减少了正则表达式匹配失败的概率。
2. 思维链 (Chain of Thought, CoT) 与 ReAct 框架
让模型直接给出结果容易导致逻辑跳跃或幻觉。强制模型“慢思考”能大幅提升复杂任务的准确率。
- 策略: 在执行动作前,强制模型先输出“思考过程”。对于 Agent,最经典的是 ReAct (Reason + Act) 模式。
- Prompt 示例:
在回答用户问题之前,请遵循以下步骤:
- Thought: 分析用户的意图和当前上下文。
- Plan: 列出解决问题的步骤。
- Action: 选择合适的工具(如果需要)。
- Observation: (这一步由系统填充工具返回的结果)。
- Reflection: 检查结果是否满足需求,如果满足则输出最终答案。
- 原理: 通过显式的推理步骤,模型更有可能发现逻辑漏洞并自我纠正。
3. 少样本提示 (Few-Shot Prompting)
这是提升稳定性最有效的手段之一。与其用千言万语描述规则,不如给它看几个完美的例子。
- 策略: 在 System Prompt 中包含 1-3 个“输入 -> 理想输出”的完整示例,特别是针对边缘情况(Edge Cases)。
- Prompt 示例:
...(前面的指令)...
示例 1:
用户:帮我查下明天的天气。
助手:{"tool": "weather_api", "args": {"date": "tomorrow"}, "thought": "用户询问天气,需调用天气工具。"}示例 2(错误处理):
用户:帮我预订去火星的票。
助手:{"tool": "none", "response": "抱歉,我目前无法处理星际旅行服务。", "thought": "该请求超出了现有工具的能力范围。"} - 原理: 利用大模型的上下文学习能力(In-Context Learning),通过模仿来锁定输出模式。
4. 明确的边界与“负向约束” (Negative Constraints)
告诉模型“不要做什么”和“要做什么”一样重要,这能防止 Agent 跑偏或过度自信。
- 策略: 明确列出禁止事项,以及当无法回答时的兜底策略。
- Prompt 示例:
- 不要 臆造工具不存在的参数。
- 不要 假设当前的日期,必须使用
get_current_time工具获取。 - 如果你不知道答案,请直接回答“我不知道”,严禁 编造事实。
- 仅使用提供的参考资料回答,不要 使用你的训练数据中的外部知识。
- 原理: 减少幻觉(Hallucination)和非预期行为。
5. 角色定义与任务拆解 (Persona & Decomposition)
赋予 Agent 一个具体的专家身份,并要求它将大任务拆解。
- 策略: 使用 "You are..." 开头,并要求 Agent 在执行复杂任务前先进行任务分解。
- Prompt 示例:
你是一位资深的 Python 代码审计专家(Agent)。你的目标是分析代码并修复 Bug。
当面对一段长代码时,不要试图一次性修复所有问题。请先将任务拆解为:
- 语法检查
- 逻辑流分析
- 安全漏洞扫描
然后逐一执行。
- 原理: 专家角色能激活模型特定领域的潜在知识,任务拆解能避免上下文过载导致的注意力丢失。
6. 自我反思与验证 (Self-Reflection / Critic)
在 Agent 输出最终结果前,增加一个“自我审查”的步骤。
- 策略: 在 Prompt 末尾要求模型检查自己的输出是否符合要求。
- Prompt 示例:
在输出最终 JSON 之前,请在内心自问:
- 这个 JSON 格式是否合法?
- 我调用的工具参数是否符合文档定义?
如果发现错误,请在输出前修正它。
- 原理: 大模型通常具备“识别自己错误”的能力,只要你提示它去检查。
7. 状态感知与记忆管理 (State Awareness)
Agent 在多轮对话中容易忘记之前的步骤或重复调用同一个工具。
- 策略: 在每一轮 Prompt 中动态注入当前的“状态摘要”或“已完成步骤”。
- Prompt 动态注入示例:
[当前状态]
- 已完成步骤:[1. 获取用户位置, 2. 查询附近餐厅]
- 待执行步骤:[3. 筛选评分大于 4.5 的餐厅]
- 历史工具报错:[工具 A 调用超时,请尝试备用方案]
- 原理: 显式地告诉 Agent 它在流程中的位置,防止死循环(Looping)。
综合模板示例 (System Prompt)
将上述策略组合,一个高稳定性的 Agent Prompt 结构如下:
# Role
你是一个专业的客户服务 Agent,专门负责处理订单退款。
# Objective
你的目标是根据公司政策,协助用户完成退款流程或解释为何无法退款。
# Tools
你拥有以下工具:
1. `check_order_status(order_id)`: 查询订单状态。
2. `process_refund(order_id)`: 执行退款。
# Constraints (负向约束)
- 禁止在未查询订单状态的情况下直接退款。
- 如果订单超过 30 天,严禁退款。
- 只能输出符合下方 Schema 的 JSON。
# Workflow (思维链)
1. Thought: 分析用户意图,提取订单号。
2. Action: 调用 `check_order_status`。
3. Observation: 根据返回的状态判断是否符合退款条件。
4. Response: 如果符合,调用 `process_refund`;否则解释原因。
# Output Format (结构化输出)
请严格遵循 JSON 格式:
{
"thought": "string",
"tool_use": { "name": "string", "params": object } | null,
"user_reply": "string"
}
# Few-Shot Examples (少样本)
User: 我想退款,订单号是 123。
Agent: {
"thought": "用户申请退款,需先查状态。",
"tool_use": { "name": "check_order_status", "params": {"order_id": "123"} },
"user_reply": "好的,正在为您查询订单 123 的状态。"
}总结
提升 Agent 稳定性不是靠“运气”,而是靠对模型行为的约束。
核心口诀:角色要清晰,输出要结构,思考要分步,例子不能少,边界要 锁死。