 播面
播面 SFT 数据构建的关键点是什么?
SFT(Supervised Fine-Tuning,有监督微调)是让大模型从“续写文本”转变为“遵循指令、进行对话”的关键阶段。
与预训练(Pre-training)追求海量数据不同,SFT 的核心逻辑是 “Quality over Quantity”(质量优于数量)。根据 LIMA(Less Is More for Alignment)等研究,少量高质量的数据往往能取得比大量低质量数据更好的效果。
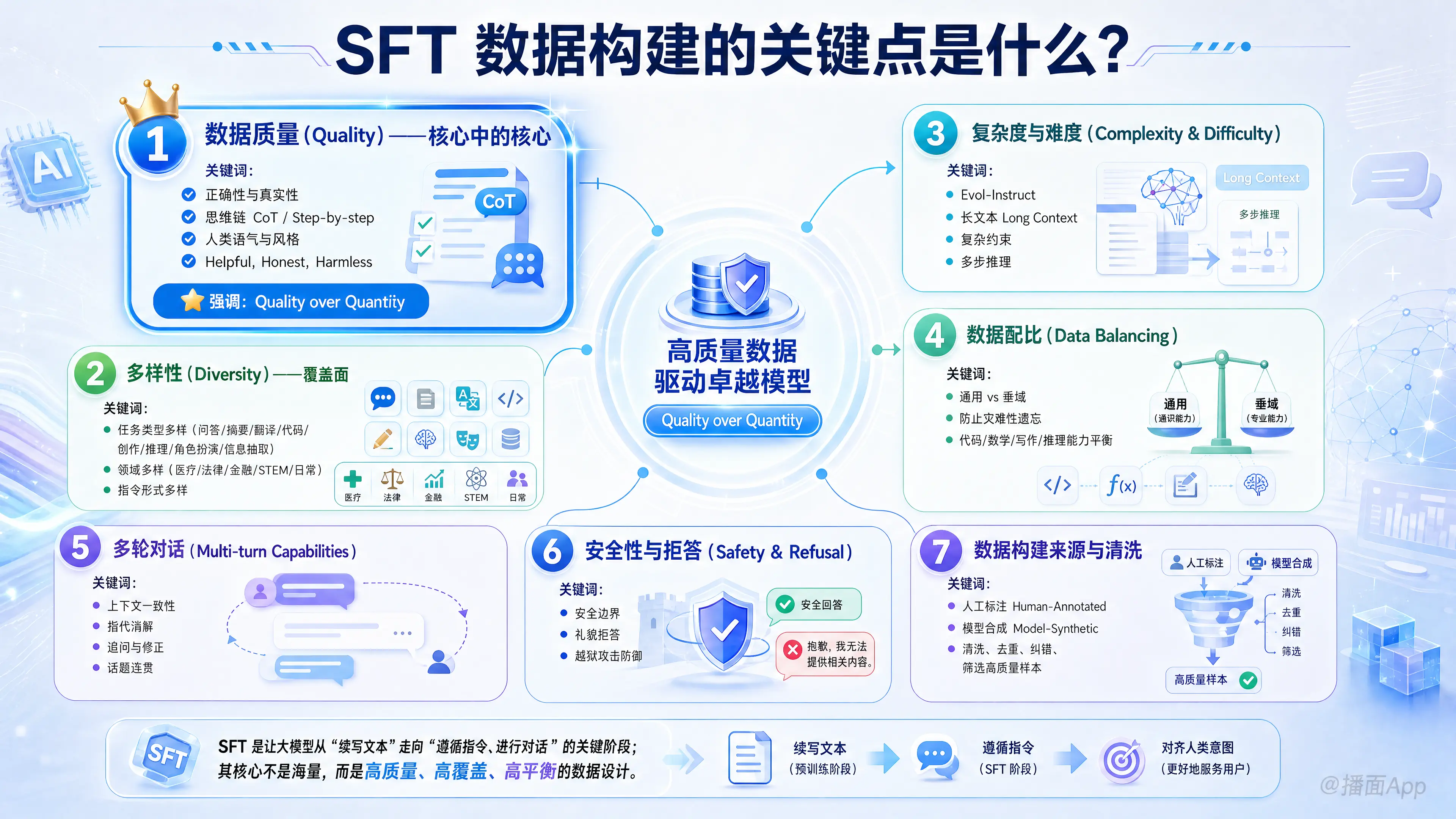
以下是 SFT 数据构建的几个关键点,按重要性排序:
1. 数据质量(Quality):核心中的核心
SFT 的本质是教会模型“如何利用预训练阶段学到的知识来回答问题”。如果 SFT 数据有误,模型就会产生幻觉或逻辑崩坏。
- 正确性与真实性:答案必须事实准确,代码必须能运行,数学推理步骤必须无误。
- 思维链(Chain of Thought, CoT):不仅仅给出答案,更要展示推理过程。高质量的 SFT 数据应包含详细的步骤解析(Step-by-step),这能显著提升模型的逻辑推理能力。
- 人类语气与风格:去除机器生成的生硬感,确保回答有帮助、诚实且无害(Helpful, Honest, Harmless)。
2. 多样性(Diversity):覆盖面
为了让模型具有泛化能力(即遇到没见过的问题也能回答),数据必须覆盖尽可能多的场景。
- 任务类型多样性:必须包含问答、摘要、翻译、代码生成、创意写作、逻辑推理、角色扮演、信息抽取等多种任务。
- 领域多样性:覆盖医疗、法律、金融、STEM(科学技术工程数学)、日常生活等不同垂直领域。
- 指令形式多样性:同一个意图应该用不同的问法来表达(例如:“把这个翻译成中文”、“用中文说”、“翻译:”),避免模型过拟合特定的指令模板。
3. 复杂度与难度(Complexity & Difficulty)
如果 SFT 数据全是简单的“1+1=2”,模型的能力会被“拉低”。
- 指令进化(Evol-Instruct):这是一种常用的数据增强方法,通过提示词让 GPT-4 等强模型将简单的指令改写得更复杂(增加约束条件、加长上下文、要求多步推理)。
- 长文本处理:包含长输入(Long Context)和长输出的数据,训练模型在长窗口下的注意力保持能力。
- 复杂约束:例如“请写一首关于春天的诗,不要使用字母 'e',且必须押韵”,这类数据能极大地提升模型的指令遵循能力(Instruction Following)。
4. 数据配比(Data Balancing)
不同类型的数据混合在一起训练,比例至关重要。
- 通用 vs 垂域:如果过度训练垂域数据(如全是医疗数据),模型可能会丧失通用对话能力(灾难性遗忘)。通常需要混入通用数据(General Data)作为“正则化”手段。
- 能力平衡:代码、数学、写作、逻辑推理的比例需要精细调整。例如,过多的短对话数据可能会削弱模型的长文写作能力。
5. 多轮对话(Multi-turn Capabilities)
真实的交互往往是连续的。
- 上下文一致性:构建数据时,需要包含多轮对话历史,训练模型指代消解(理解“它”、“那个”指代上一轮的什么)和保持话题连贯性的能力。
- 追问与修正:模拟用户对模型答案不满意的场景,要求模型进行修正或解释。
6. 安全性与拒答(Safety & Refusal)
SFT 也是初步对齐(Alignment)的过程。
- 安全边界:对于涉及违法、暴力、色情或偏见的指令,数据集中应包含标准的“拒答”范例(即礼貌地拒绝并解释原因),而不是生硬地切断。
- 诱导攻击防御:加入一些“越狱”攻击的 Prompt,并教会模型如何防御。
7. 数据构建来源与清洗
目前主流的 SFT 数据构建方式主要有两种:
- 人工标注(Human-Annotated):质量最高,但昂贵且慢。通常用于构建核心的“种子数据”或作为评估集。
- 模型合成(Model-Synthesized / Distillation):利用 GPT-4 等超强模型生成数据(如 Alpaca, Vicuna 模式)。
- 关键点:必须进行严格的清洗(Filtering)。模型生成的数据往往包含“作为一名AI语言模型...”的废话、重复语句或错误的幻觉,需要通过规则或奖励模型(Reward Model)进行过滤。
总结
SFT 数据构建的公式可以概括为:
SFT 效果 = (高正确率 CoT) + (极高的指令复杂度) + (广泛的任务分布) - (重复/低质数据)
现在的趋势是“合成数据+自动化筛选”,即利用强模型生成复杂的指令和思维链,然后用算法筛选出质量最高的子集进行微调。