 播面
播面 BPE (Byte Pair Encoding)、WordPiece 和 SentencePiece 分词算法的区别与原理
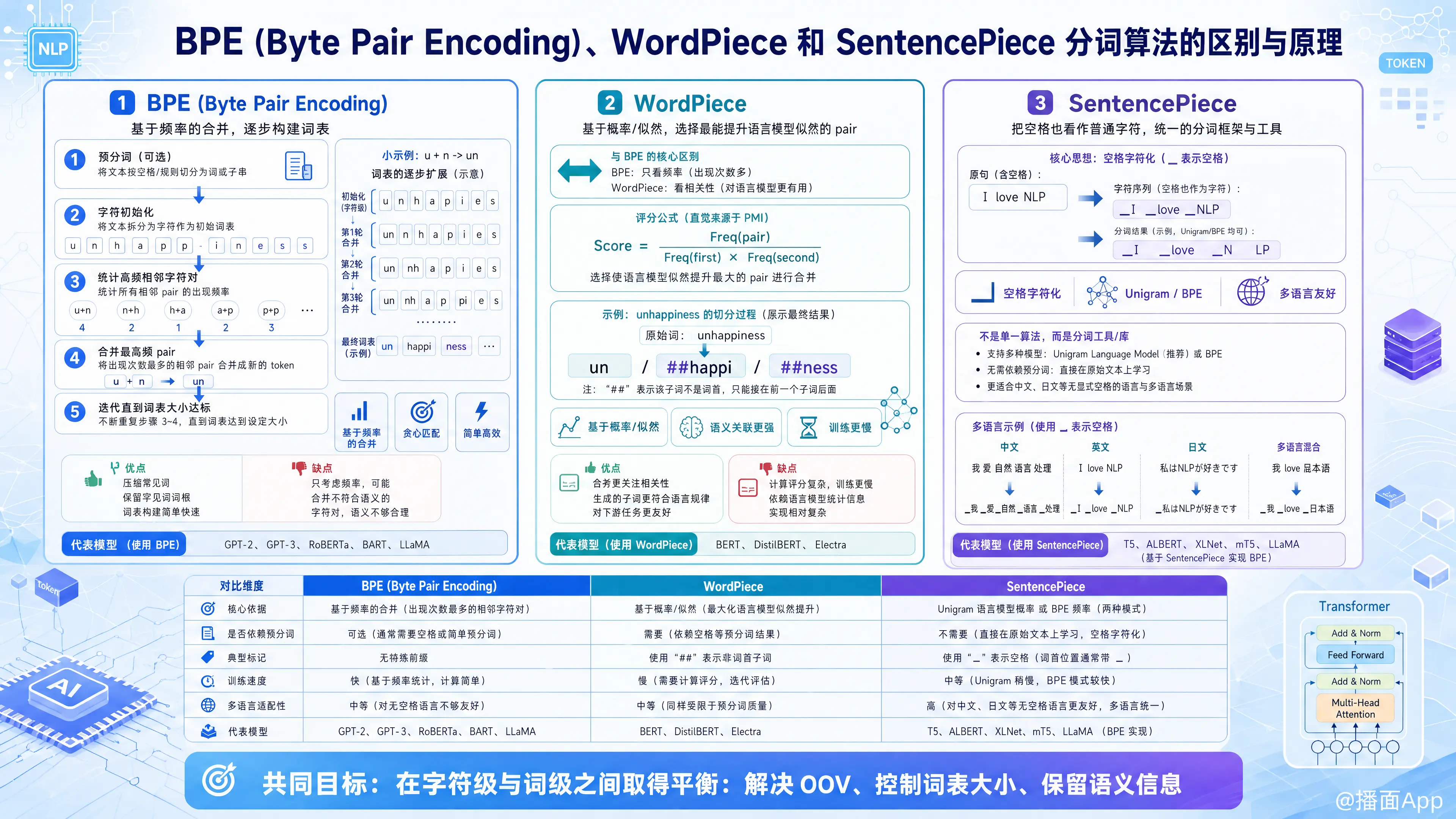
在自然语言处理(NLP)特别是大模型(LLM)时代,BPE、WordPiece 和 SentencePiece 是三种最主流的子词分词(Subword Tokenization)算法。
它们的共同目标是:在“字符级”(Character-level)和“单词级”(Word-level)分词之间寻找平衡。既能解决未登录词(OOV)问题,又能控制词表大小,同时保留语义信息。
以下是这三种算法的原理、区别及详细对比。
1. BPE (Byte Pair Encoding)
原理:基于频率的合并
BPE 最初是一种数据压缩算法,后被引入 NLP。它的核心思想是统计语料中相邻字符对(Character Pair)的出现频率,迭代地合并频率最高的字符对。
训练过程(构建词表):
- 预分词:将文本按空格切分成单词,并在每个单词末尾添加特殊符号(如
</w>)以标记单词边界。 - 初始化:将所有单词拆分为字符序列。词表初始包含所有基础字符。
- 统计:统计所有相邻字符对(如
('u', 'n'))在语料中出现的频率。 - 合并:找到频率最高的字符对,将其合并成一个新的子词(如
'un'),加入词表。 - 迭代:重复步骤 3-4,直到词表大小达到预设值(如 30k 或 50k)。
编码过程(Inference):
对新文本,按贪心策略,从长到短匹配词表中的子词。
代表模型:
- GPT-2, GPT-3, RoBERTa, BART, LLaMA (LLaMA 使用的是基于 BPE 的 SentencePiece 实现)。
特点:
- 优点:简单高效,能有效压缩常见词,保留罕见词的词根。
- 缺点:基于频率合并,可能导致合并后的子词在语义上不一定合理(例如将两个不相关的字合并,仅因为它们常在一起出现)。
2. WordPiece
原理:基于概率(似然)的合并
WordPiece 由 Google 开发,用于 BERT。它的流程与 BPE 非常相似,但在选择合并哪一对字符时的标准不同。
核心区别:
- BPE:选择频率最高的相邻字符对。
- WordPiece:选择合并后能使训练数据语言模型似然值(Likelihood)增加最大的相邻字符对。
数学直觉:
WordPiece 衡量的是两个子词的相关性。它使用的打分公式类似于逐点互信息(PMI):
如果两个子词 和 经常单独出现(分母大),即使它们组成的 频率较高,得分也可能低;反之,如果 和 很少单独出现,主要以 形式出现,得分就会高。
特殊标记:
WordPiece 会在非单词开头的子词前加前缀(如 BERT 中的 ##)。例如 "unhappiness" 可能被分为 ['un', '##happi', '##ness']。
代表模型:
- BERT, DistilBERT, Electra。
特点:
- 优点:比 BPE 更关注子词间的语义关联,通常能生成质量更高的词表。
- 缺点:训练速度比 BPE 慢(计算量大)。
3. SentencePiece
原理:将空格视为字符 + Unigram/BPE
SentencePiece 不是一种独立的算法逻辑,而是一个分词库/工具(由 Google 开发),它提出了一种新的处理视角,并通常搭配 Unigram Language Model 算法使用(也可以选 BPE)。
核心痛点解决:
BPE 和 WordPiece 通常需要先按空格进行“预分词”(Pre-tokenization)。这对于以空格分隔单词的语言(英语)很容易,但对于中文、日文等不使用空格分隔单词的语言,处理起来很麻烦。
SentencePiece 的创新:
- Raw Stream:它将输入视为原始的 Unicode 字符流,将空格也视为一个普通字符(通常用下划线
_或 Unicode U+2581 代替)。 - 语言无关:不需要针对特定语言的预分词逻辑,中英文处理方式一致。
- 可逆性:分词结果可以直接还原为原始文本(包括空格),不会丢失格式信息。
Unigram Language Model (SentencePiece 的默认算法):
与 BPE/WordPiece 的“增量合并”不同,Unigram 采用减量剪枝策略:
- 初始化:构建一个巨大的初始词表(包含所有可能的子字符串)。
- EM 算法:计算每个子词的概率,评估如果移除某个子词,总的损失函数(Loss)会增加多少。
- 剪枝:移除那些对 Loss 影响最小(即最不重要)的子词(通常保留前 80%)。
- 迭代:重复直到达到目标词表大小。
代表模型:
- T5, ALBERT, XLNet, mBART, ChatGLM (使用 SentencePiece 的 BPE 模式)。
特点:
- 优点:真正的端到端(End-to-End),无需特定语言的预处理,原生支持多语言,支持分词采样(Subword Regularization)以增强模型鲁棒性。
- 缺点:Unigram 训练时的采样过程较慢。
总结对比表
| 特性 | BPE (Byte Pair Encoding) | WordPiece | SentencePiece (Unigram 模式) |
|---|---|---|---|
| 合并/构建策略 | 增量式:合并频率最高的对 | 增量式:合并似然值增益最大的对 | 减量式:从大词表中剪枝概率低的子词 |
| 核心指标 | 频率 (Frequency) | 互信息/概率 (PMI / Likelihood) | 概率 (Probability / Loss) |
| 预分词需求 | 需要 (通常按空格切分) | 需要 (通常按空格切分) | 不需要 (将输入视为 Raw Stream) |
| 空格处理 | 通常在预处理阶段去除 | 通常在预处理阶段去除 | 保留 (视为特殊字符 _) |
| 可逆性 | 较弱 (可能丢失空格信息) | 较弱 | 强 (完全可逆) |
| 典型代表 | GPT 系列, RoBERTa | BERT 系列 | T5, ALBERT, LLaMA (SP库+BPE算法) |
| 适用场景 | 生成式任务 (GPT) | 理解式任务 (BERT) | 多语言任务, 中日韩语言 |
简单的一句话总结
- BPE:谁出现次数多,我就把谁粘在一起。(GPT 的选择)
- WordPiece:谁粘在一起后能让模型更惊讶(概率提升大),我就粘谁。(BERT 的选择)
- SentencePiece:不管你是中文英文还是空格,我都当成字符流,用概率模型挑出最好的子词组合。(多语言通用的瑞士军刀)