 播面
播面 Pre-Norm 和 Post-Norm 有什么区别?
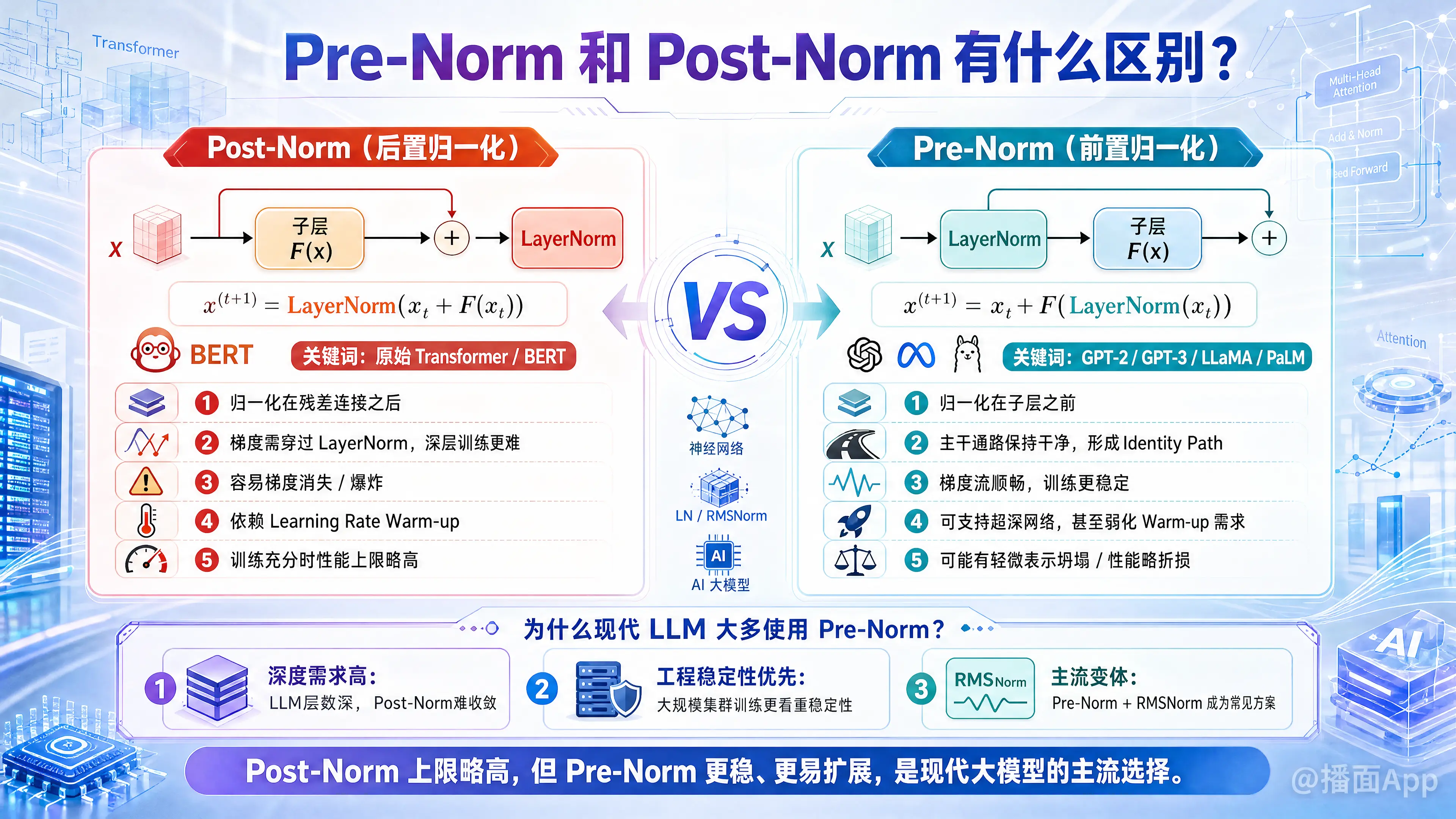
Pre-Norm(前置归一化)和 Post-Norm(后置归一化)是 Transformer 架构中 Layer Normalization (LN) 放置位置的两种不同策略。
虽然只是位置上的微小变动,但它们对模型的训练稳定性、收敛速度以及最终性能有着显著的影响。
以下是详细的对比分析:
1. 结构位置的区别
假设 是输入, 是子层(如 Self-Attention 或 Feed Forward Network),LayerNorm 为归一化操作。
Post-Norm (原始 Transformer / BERT):
- 顺序:先做子层计算,再残差连接,最后做归一化。
- 公式:
- 特点:归一化在残差连接之后。
Pre-Norm (GPT-2 / GPT-3 / LLaMA):
- 顺序:先做归一化,再做子层计算,最后残差连接。
- 公式:
- 特点:归一化在残差连接之内(子层之前),主干通路(Identity Path)保持“干净”。
2. 核心差异对比
A. 训练稳定性与梯度流 (Training Stability)
这是两者最大的区别。
- Post-Norm (难训练):
- 在反向传播时,梯度必须通过 LayerNorm 层。由于 Post-Norm 把归一化放在了主干路上,随着层数加深,梯度容易出现消失或爆炸的问题。
- 后果:为了训练深层的 Post-Norm 模型,通常必须使用 Learning Rate Warm-up(学习率预热)策略,即在训练初期使用极小的学习率,慢慢增加,否则模型很容易发散(训练崩塌)。
- Pre-Norm (易训练):
- 在 Pre-Norm 中,主干路是 ,形成了一条畅通无阻的“高速公路”。梯度可以直接沿着残差连接从最后一层传到第一层,不受 LayerNorm 的阻碍。
- 后果:训练非常稳定,甚至可以不需要 Warm-up,能够直接使用较大的学习率训练极深的网络(如 1000 层以上)。
B. 最终性能 (Performance)
虽然 Pre-Norm 更好训练,但在同等条件下,性能往往略逊一筹。
- Post-Norm (上限高):
- 由于输出经过了归一化,每一层的输出幅值都保持在一定范围内。这使得模型在训练充分(且使用了 Warm-up)的情况下,往往能达到比 Pre-Norm 略好的泛化性能。
- Pre-Norm (略有折损):
- 由于主干路是不断的累加 (),随着层数加深,主干 的幅值会越来越大,而子层 的贡献相对变得越来越小。这可能导致深层的参数更新效率降低,产生所谓的“表示坍塌”问题。
- 注:虽然理论上性能略低,但对于超大规模模型(如 GPT-3, PaLM, LLaMA),为了保证能训练起来,Pre-Norm 几乎是唯一选择。
3. 为什么现在的 LLM 大多使用 Pre-Norm?
尽管 Post-Norm 在 BERT 时代很流行,但现代的大语言模型(LLM)如 GPT 系列、LLaMA、PaLM 等几乎全部采用了 Pre-Norm(或者其变体,如 RMSNorm + Pre-Norm)。
原因如下:
- 深度需求:LLM 通常非常深,Post-Norm 在深层网络中极难收敛。
- 工程稳定性:在大规模集群训练中,稳定性压倒一切。Pre-Norm 极大地减少了梯度爆炸导致训练中断的风险。
4. 总结对比表
| 特性 | Post-Norm | Pre-Norm |
|---|---|---|
| 典型代表 | Transformer (原版), BERT | GPT-2, GPT-3, LLaMA, ViT |
| 公式 | ||
| 归一化位置 | 残差相加之后 | 进入子层之前 |
| 训练稳定性 | 较差,深层网络易梯度消失/爆炸 | 极好,梯度流通过残差直通 |
| Warm-up | 必须 (否则易发散) | 通常不需要 (或依赖较小) |
| 最终效果 | 理论上限略高 | 略低 (但在大模型中可接受) |
| 主干输出幅值 | 稳定 (被 Norm 限制) | 随层数增加而变大 |
5. 补充:折中方案
为了结合两者的优点(Post-Norm 的高性能和 Pre-Norm 的稳定性),研究界也提出了一些改进方案,例如:
- Sandwich Norm:在 Pre-Norm 的基础上,在残差连接后也加一个 Norm。
- DeepNet:通过调整初始化的缩放系数(DeepNorm),使得 Post-Norm 结构也能稳定训练深层网络。
但在目前的开源大模型生态中,Pre-Norm (配合 RMSNorm) 依然是绝对的主流配置。