 播面
播面 如何估算一个 Decoder-only 模型的参数量和训练/推理时的显存占用?
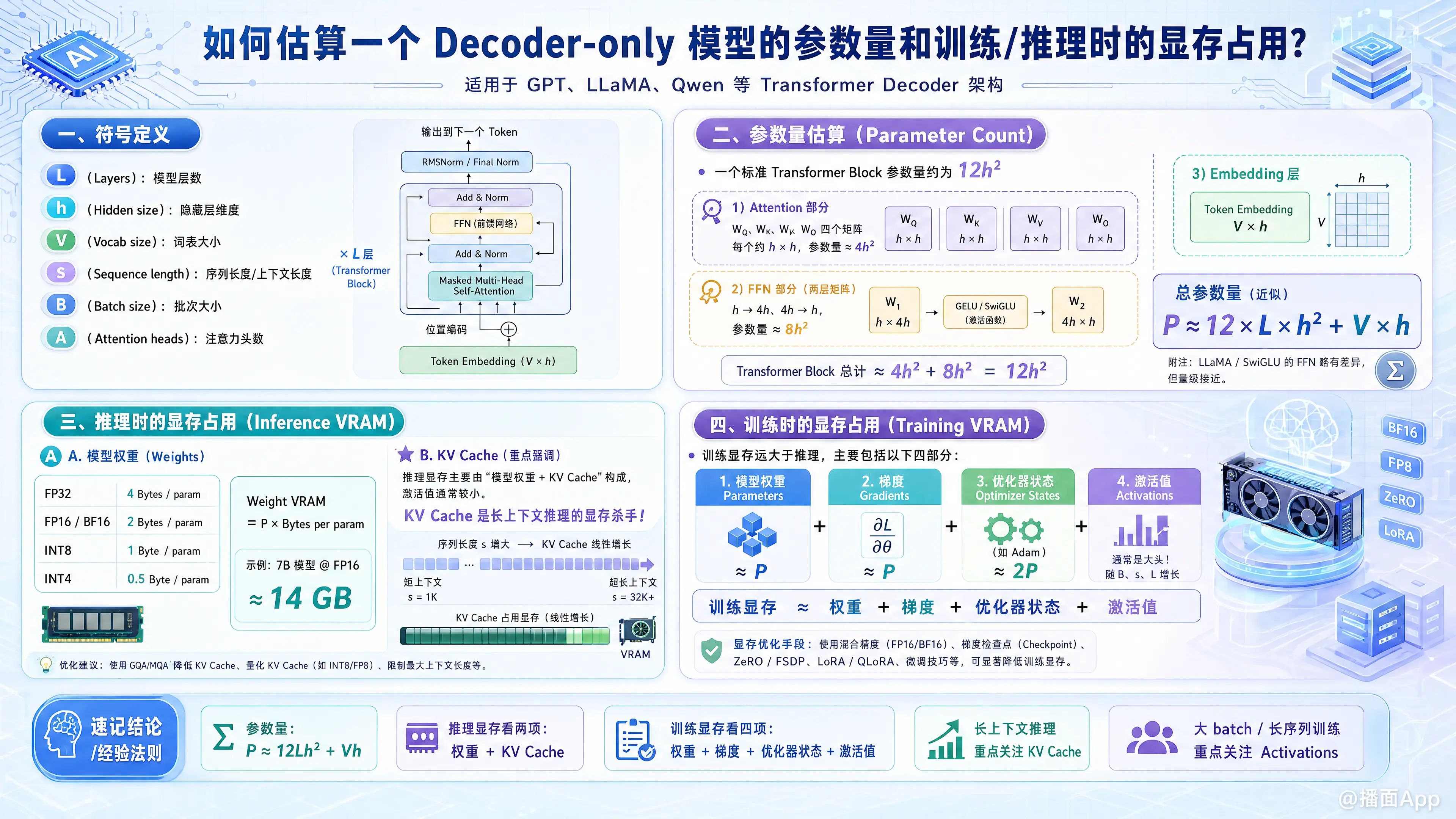
估算 Decoder-only 模型(如 GPT 系列、LLaMA、Qwen 等)的参数量和显存占用是深度学习工程中的基本功。显存占用主要分为 推理(Inference) 和 训练(Training) 两个场景,两者的计算逻辑完全不同。
以下是详细的估算指南:
一、 符号定义
在开始之前,我们需要定义几个核心超参数:
- (Layers): 模型层数 (Number of layers)
- (Hidden size): 隐藏层维度 (Hidden dimension)
- (Vocab size): 词表大小 (Vocabulary size)
- (Sequence length): 序列长度/上下文长度
- (Batch size): 批次大小
- (Attention heads): 注意力头数
二、 参数量估算 (Parameter Count)
对于标准的 Transformer Decoder 架构,参数主要集中在两个部分:Attention 层 和 FFN (Feed-Forward Network) 层。
1. 估算公式
一个标准的 Transformer Block 参数量约为 。
- Attention 部分: 包含 四个矩阵,每个形状为 。
- 参数量
- FFN 部分: 包含两个矩阵(升维 和降维 )。
- 参数量
- 注:LLaMA 等模型使用 SwiGLU 激活函数,FFN 有 3 个矩阵,但中间维度通常缩小为 或 ,总参数量通常略大于标准 FFN。
- Embedding 层:
总参数量估算公式:
2. 举例 (LLaMA-7B)
- (64.4亿)
- (1.3亿)
- 总和 Billion。这与 7B 非常接近(实际差异在于 SwiGLU 和 Normalization 层的参数)。
三、 推理时的显存占用 (Inference VRAM)
推理时的显存主要由两部分组成:模型权重 和 KV Cache(键值缓存)。激活值(Activation)在推理时占用极小,通常可忽略。
1. 模型权重 (Model Weights)
取决于加载精度:
- FP32: 4 Bytes / param
- FP16 / BF16: 2 Bytes / param (主流)
- INT8: 1 Byte / param
- INT4: 0.5 Byte / param
例子 (7B 模型 @ FP16):
2. KV Cache (显存杀手)
在生成过程中,为了避免重复计算,我们会缓存每一层的 Key 和 Value 矩阵。KV Cache 的大小与序列长度 () 和 Batch Size () 成正比。
公式:
(系数 2 代表 Key 和 Value 两个矩阵)
例子 (7B 模型, FP16, Batch=1, 长度=4096):
如果并发数 () 增加到 32,或者上下文 () 增加到 32k,KV Cache 会迅速超过模型权重本身的大小。
3. 推理总显存
四、 训练时的显存占用 (Training VRAM)
训练比推理消耗大得多,因为需要存储:模型权重、梯度、优化器状态、激活值。
1. 静态内存 (Model + Gradients + Optimizer)
假设使用 AdamW 优化器和 混合精度训练 (Mixed Precision):
- 模型权重 (FP16): 2 Bytes
- 梯度 (FP16): 2 Bytes
- 优化器状态 (AdamW): 需要保存 FP32 的动量 (Momentum) 和方差 (Variance),以及 FP32 的主权重 (Master Weights)。
- FP32 Master Weights: 4 Bytes
- FP32 Momentum: 4 Bytes
- FP32 Variance: 4 Bytes
- 优化器总计: 12 Bytes
静态内存总计 (每参数): Bytes。
经验法则:全量微调 (Full Fine-tuning) 时,每 1B 参数大约需要 16GB - 20GB 显存(不包含激活值)。
- 7B 模型全量微调基础需求 (通常需要多卡 A100)。
2. 动态内存 (Activations)
为了反向传播计算梯度,前向传播的中间结果(激活值)必须被保存。激活值占用与 成正比。
粗略估算公式 (每层):
factor 取决于具体架构(Attention + FFN 的中间层大小),通常在 30-50 之间(Bytes)。
节省显存的关键技术:
- Gradient Checkpointing (梯度检查点): 用计算换显存。不存所有激活值,反向传播时重算。这可以将激活值显存降低约 或更多,通常能节省 50%-70% 的激活显存。
3. 微调优化技术 (PEFT)
由于全量微调太贵,我们通常使用 LoRA / QLoRA。
LoRA: 冻结主模型,只训练极小的 Adapter。
- 模型权重: 14GB (7B FP16)
- 优化器状态: 极小 (仅针对 LoRA 参数,通常 < 1GB)
- 梯度: 极小
- 激活值: 依然取决于 Batch Size 和 Sequence Length,但比全量少。
- 7B LoRA 显存: 约 16GB - 24GB (取决于 context length)。
QLoRA: 4-bit 量化主模型 + LoRA。
- 模型权重: 3.5GB - 4GB (7B INT4)
- 7B QLoRA 显存: 约 6GB - 10GB (单张消费级显卡即可跑)。
五、 总结速查表 (Cheat Sheet)
以 7B 模型 (Hidden=4096, Layers=32) 为例:
| 场景 | 精度/方法 | 估算公式 | 7B 模型典型显存需求 |
|---|---|---|---|
| 推理 | FP16 | ~14GB + KV Cache | |
| 推理 | INT4 | ~4GB + KV Cache | |
| 全量微调 | AdamW (FP16/32) | > 120GB (需多卡) | |
| LoRA 微调 | FP16 Base | ~24GB (3090/4090) | |
| QLoRA 微调 | INT4 Base | ~10GB (3080/4070) |
六、 实用建议
- FlashAttention: 务必开启。它不仅加速计算,还能大幅降低 Attention 部分的显存占用(从 降到 )。
- DeepSpeed / FSDP: 如果做全量微调,必须使用 ZeRO-2 或 ZeRO-3 策略,将优化器状态和参数切分到多张卡上,否则单卡显存肯定不够。
- 序列长度影响: 显存爆炸通常是因为 太长。如果显存 OOM (Out Of Memory),优先检查 KV Cache (推理时) 或 Batch Size (训练时)。