 播面
播面 Encoder-Decoder 架构和 Decoder-only 架构的区别
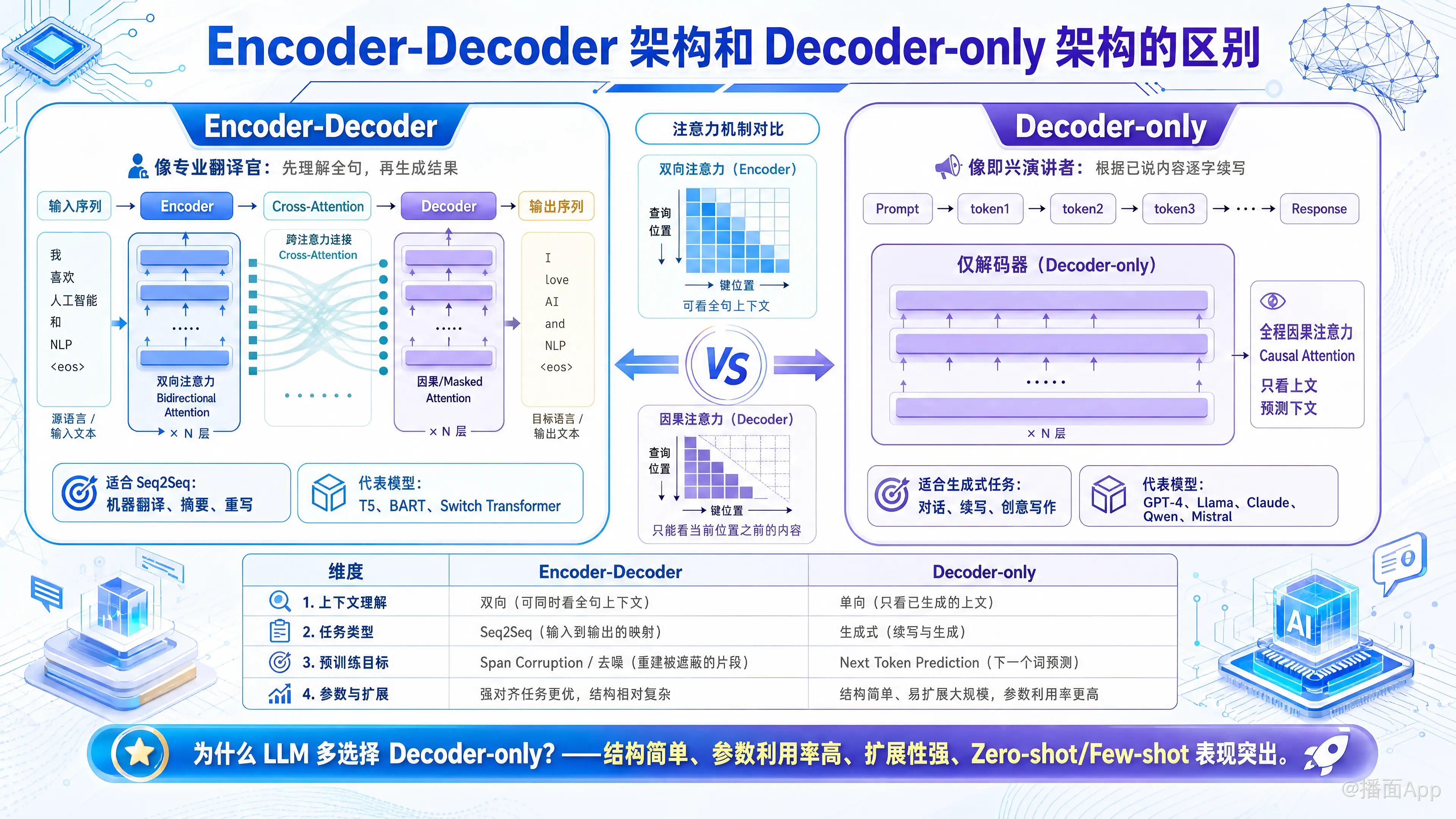
Encoder-Decoder 架构和 Decoder-only 架构都是基于 Google 在 2017 年提出的 Transformer 模型,但它们在结构设计、注意力机制(Attention Mechanism)以及适用场景上有显著的区别。
简单来说:
- Encoder-Decoder 像是“专业的翻译官”:先听完完整的一句话(理解全局),再进行翻译。
- Decoder-only 像是“即兴演讲者”:根据已经说出的内容,逐字推测下一个字是什么。
以下是详细的对比分析:
1. 核心架构与工作原理
Encoder-Decoder (编码器-解码器架构)
这是 Transformer 的原始形态。它由两个独立的部分组成:
- Encoder (编码器):负责“输入”。它使用双向注意力机制 (Bidirectional Attention),这意味着它在处理一个词时,可以同时看到它前面和后面的词。它的目标是把输入序列(如一句话)压缩成一个包含丰富语义的向量表示。
- Decoder (解码器):负责“输出”。它使用单向/因果注意力机制 (Causal/Masked Attention),只能看到当前时刻之前的词。
- 连接点:Decoder 通过 Cross-Attention (交叉注意力) 机制读取 Encoder 生成的语义向量,结合自己已经生成的词,来预测下一个词。
Decoder-only (仅解码器架构)
这是目前主流大模型(如 GPT 系列、Llama)采用的架构。
- 结构:它只有 Decoder 部分,去掉了独立的 Encoder。
- 原理:它将输入(Prompt)和输出(Response)看作一个连续的序列。
- 注意力机制:全程使用单向/因果注意力机制 (Causal Attention)。这意味着模型在处理第 个词时,严格看不见第 个及以后的词。它纯粹是基于“上文”来预测“下文”。
2. 关键区别维度
| 维度 | Encoder-Decoder | Decoder-only |
|---|---|---|
| 代表模型 | T5, BART, Switch Transformer, Google PaLM 2 (部分特性) | GPT-3/4, Llama, Claude, Qwen, Mistral |
| 上下文理解 | 双向 (Bidirectional):Encoder 可以同时看到整个输入句子,理解上下文语境能力极强。 | 单向 (Unidirectional):只能看到左边的内容(上文),无法直接利用下文信息来理解当前词。 |
| 任务类型 | Seq2Seq 任务:如机器翻译、文本摘要、文本重写。在输入和输出有明确对应关系的任务上表现极佳。 | 生成式任务:如文本续写、对话、创意写作。通过海量数据训练,现在也具备了极强的通用任务处理能力。 |
| 参数效率 | 在相同参数量下,处理纯理解任务(如分类)或强对齐任务(如翻译)通常略优。 | 参数利用率高,模型结构简单,更容易扩展到极大规模(Scaling Law)。 |
| 预训练目标 | 通常是 Span Corruption (如 T5,挖掉一段话让模型填空) 或去噪。 | Next Token Prediction (预测下一个词)。 |
3. 为什么现在的 LLM (大语言模型) 大多选择 Decoder-only?
在 BERT (Encoder-only) 和 T5 (Encoder-Decoder) 盛行的年代,大家认为双向理解是必须的。但 GPT 系列证明了 Decoder-only 的统治力,原因如下:
通用性与 Zero-shot 能力:
Decoder-only 架构通过“预测下一个词”的任务训练,非常符合人类生成语言的自然过程。这种结构在海量数据下展现出了惊人的 In-context Learning (上下文学习) 能力,即不需要微调,只给几个例子(Prompt)就能完成任务。工程实现的便利性与扩展性 (Scaling):
Decoder-only 结构更简单(没有 Cross-Attention,只有 Self-Attention)。在构建万亿参数级别的模型时,简单的结构意味着更容易进行分布式训练优化,且更符合 Scaling Law(模型越大,性能越好)。KV Cache 的复用:
在推理(生成)阶段,Decoder-only 架构可以非常高效地利用 KV Cache 技术,将之前的计算结果缓存下来,每生成一个新词只需计算一次增量,推理效率很高。虽然 Encoder-Decoder 也可以用,但 Decoder-only 的统一性使其优化更直接。
4. 总结
- 如果你需要做一个专门的机器翻译系统或者文本摘要工具,且模型规模不大(例如小于 10B 参数),Encoder-Decoder (如 FLAN-T5) 仍然是非常强劲且高效的选择。
- 如果你追求通用人工智能 (AGI),需要模型既能写代码、又能聊天、还能做逻辑推理,且准备训练超大规模模型,Decoder-only 是目前业界公认的最佳路径。