 播面
播面 大模型的评估方案有哪些?
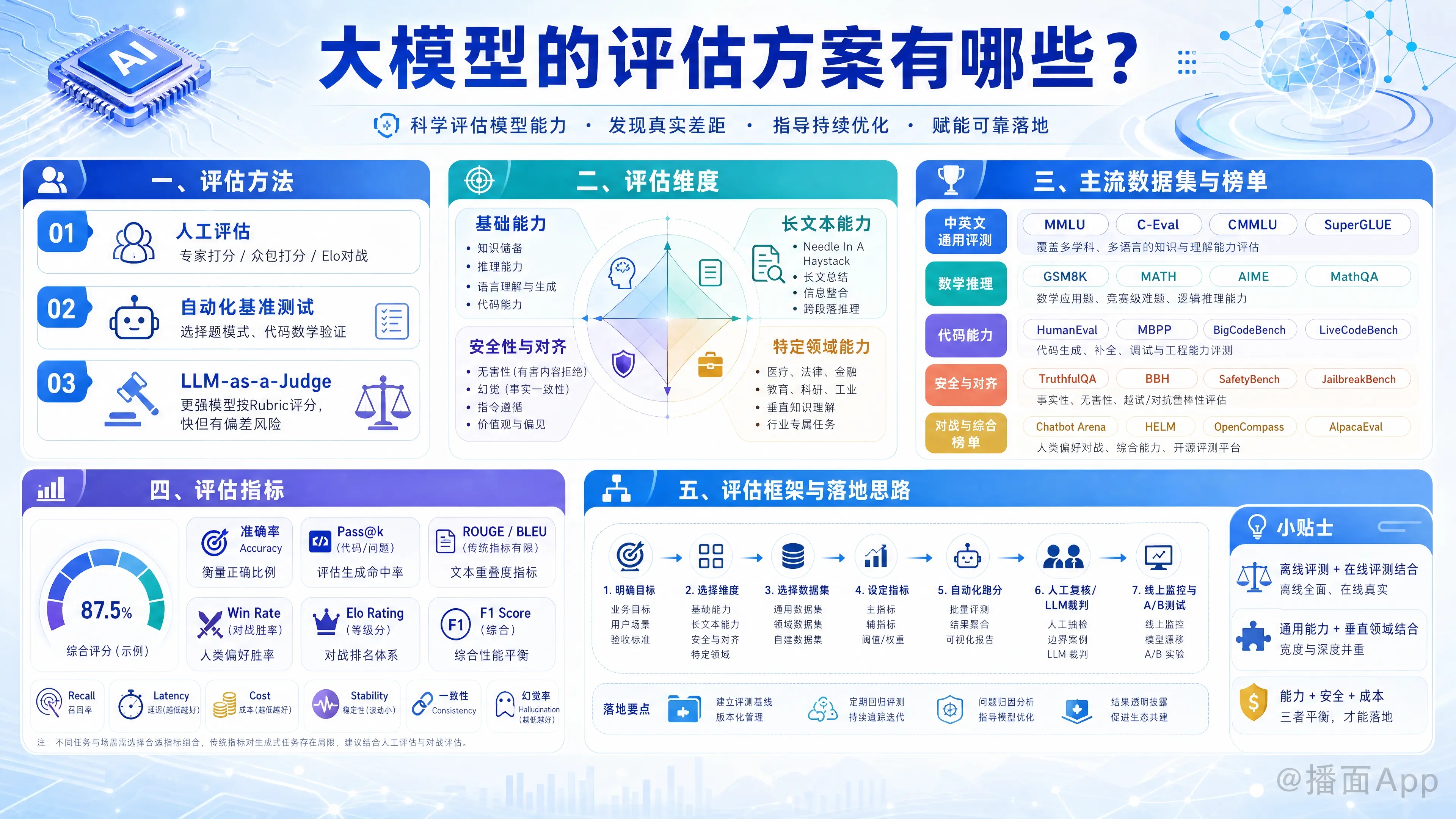
大模型的评估(LLM Evaluation)是一个非常复杂且快速发展的领域。由于大模型具备生成性、多任务和不可预测性,传统的单一指标(如准确率)往往无法全面衡量其能力。
目前主流的大模型评估方案通常从评估方法、评估维度、数据集/榜单、评估指标以及评估框架这几个方面来构建。
以下是详细的评估方案梳理:
一、 评估方法 (Evaluation Methods)
根据“谁来评”和“怎么评”,主要分为以下三类:
1. 人工评估 (Human Evaluation)
这是最准确但也最昂贵、最慢的方法。通常用于对齐(Alignment)阶段或最终验收。
- 专家打分: 由领域专家(如医生、程序员)针对特定问题评估回答的准确性。
- 众包打分: 普通用户对回答的流畅度、相关性进行打分。
- Elo 对战 (Side-by-Side, SBS): 类似于 LMSYS Chatbot Arena。让模型 A 和模型 B 回答同一个问题,人类选择更好的一个,通过 Elo 积分系统排名。
2. 自动化基准测试 (Automated Benchmarks)
利用标准化的数据集进行测试,主要用于评估基础模型(Base Model)的能力。
- 选择题模式: 计算模型选择正确选项的概率或准确率(如 MMLU)。
- 代码/数学验证: 运行模型生成的代码或验证数学推导结果(如 HumanEval, GSM8K)。
3. 模型评估模型 (LLM-as-a-Judge)
利用更强的模型(如 GPT-4)来评估较小或较弱模型的输出。
- 原理: 给 GPT-4 一个评分标准(Rubric),让它给目标模型的回答打分(1-10分)或解释优劣。
- 优点: 比人工快且便宜,比传统指标(BLEU)更懂语义。
- 缺点: 存在“偏好偏差”(Self-preference),即模型可能更喜欢类似自己风格的回答。
二、 评估维度 (Evaluation Dimensions)
评估方案通常会覆盖以下核心能力:
基础能力 (Capabilities):
- 知识储备: 常识、世界知识、专业领域知识(MMLU, C-Eval)。
- 推理能力: 逻辑推理、数学解题、思维链(GSM8K, MATH)。
- 语言理解与生成: 阅读理解、摘要、翻译、创作。
- 代码能力: 代码生成、Debug、翻译(HumanEval, MBPP)。
长文本能力 (Long Context):
- 大海捞针 (Needle In A Haystack): 在极长的文本中插入关键信息,看模型能否提取。
- 长文总结: 对几万字的书籍或报告进行总结。
安全性与对齐 (Safety & Alignment):
- 无害性: 是否输出暴力、色情、歧视内容。
- 幻觉 (Hallucination): 模型是否一本正经地胡说八道(TruthfulQA)。
- 指令遵循 (Instruction Following): 是否严格按照用户的格式要求输出(如“只输出JSON”)。
特定领域 (Domain Specific):
- 医疗、法律、金融等垂直领域的专业评估。
三、 主流数据集与榜单 (Datasets & Leaderboards)
构建评估方案时,通常会组合使用以下数据集:
1. 综合能力
- MMLU (Massive Multitask Language Understanding): 英文主流榜单,涵盖 STEM、人文、社科等 57 个学科。
- C-Eval / CMMLU: 针对中文大模型的综合性考试评测集。
- SuperGLUE: 传统的 NLP 任务集合(推理、阅读理解等)。
2. 推理与数学
- GSM8K: 小学水平的数学应用题(测试多步推理)。
- MATH: 难度较高的竞赛级数学题。
- ARC (AI2 Reasoning Challenge): 科学问答推理。
3. 代码能力
- HumanEval (OpenAI): Python 编程任务,评估 Pass@1 (一次通过率)。
- MBPP: 基础 Python 编程问题。
4. 对话与指令遵循
- MT-Bench: 模拟多轮对话,涵盖写作、角色扮演、推理等,通常用 GPT-4 打分。
- AlpacaEval: 评估指令跟随能力的自动化榜单。
5. 知名榜单 (Leaderboards)
- HuggingFace Open LLM Leaderboard: 开源模型最权威的榜单。
- LMSYS Chatbot Arena: 基于人类投票的竞技场,公认最反映真实体验。
- OpenCompass (司南): 上海人工智能实验室推出的全方位评测榜单。
四、 评估指标 (Metrics)
在具体的计算中,使用什么指标?
基于规则/字符的指标 (Traditional Metrics):
- BLEU / ROUGE: 比较生成文本与参考文本的重合度(n-gram)。主要用于翻译和摘要,对聊天机器人评估意义不大。
- Exact Match (EM): 精确匹配,答案必须完全一致(常用于数学或简答)。
基于语义/嵌入的指标 (Embedding-based):
- BERTScore: 利用 BERT 的向量计算生成文本与参考文本的语义相似度。
基于概率的指标 (Probabilistic):
- Perplexity (PPL, 困惑度): 衡量模型对文本的预测能力。PPL 越低,模型生成的文本越自然。常用于预训练阶段评估。
特定任务指标:
- Pass@k: 在代码生成中,生成 k 个样本,只要有一个通过测试用例即视为成功。
五、 评估框架/工具 (Evaluation Frameworks)
如果企业或开发者要自己搭建评估流程,通常使用以下开源工具:
- EleutherAI LM Evaluation Harness:
- 行业标准工具,支持 200+ 数据集,HuggingFace 榜单背后的工具。
- OpenCompass (司南):
- 支持中英文双语,覆盖维度全,适合国内模型评估。
- Stanford HELM (Holistic Evaluation of Language Models):
- 斯坦福大学推出的全面评估框架,不仅看准确率,还看公平性、偏见、毒性等。
- DeepEval / Ragas:
- 专门用于 RAG (检索增强生成) 系统的评估框架(评估检索准确度和生成相关度)。
总结:如何制定一个评估方案?
如果你需要评估一个大模型,建议采取分层策略:
- 第一层(基座能力): 跑自动化测试(MMLU, GSM8K, HumanEval),看硬指标。
- 第二层(对话能力): 使用 MT-Bench 或 LLM-as-a-Judge,评估多轮对话和指令遵循。
- 第三层(业务场景): 构建私有测试集(Golden Dataset),包含企业内部的真实业务问题,进行人工验收或 RAG 效果评估。
- 第四层(安全红队): 进行 Red Teaming 测试,确保没有安全漏洞。