 播面
播面 Kafka 为什么采用分区(Partition)的设计?
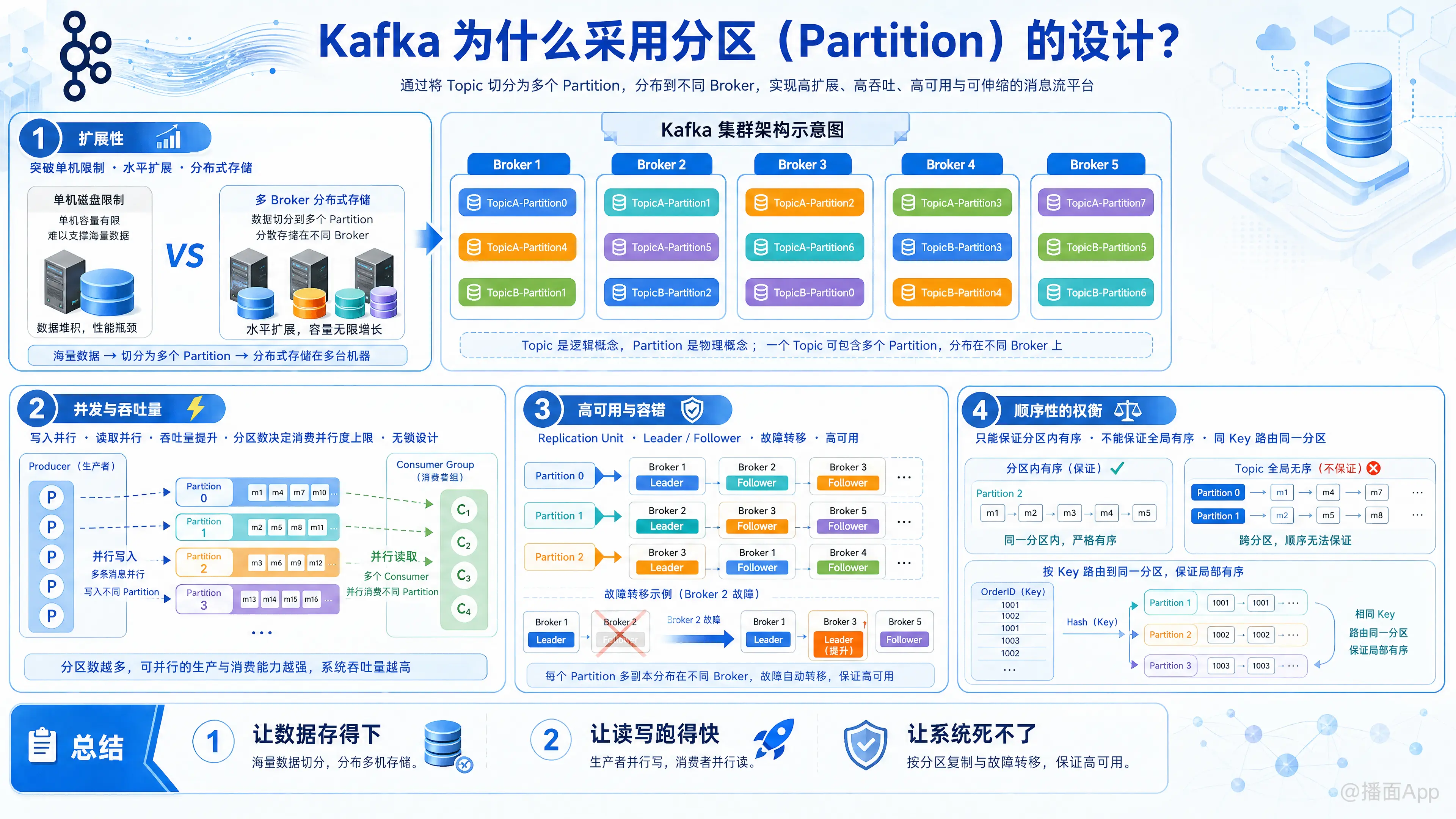
Kafka 采用分区(Partition)的设计,核心目的可以总结为三个关键词:扩展性(Scalability)、并发/吞吐量(Concurrency/Throughput) 和 可用性(Availability)。
以下是详细的深度解析:
1. 扩展性(存储层面的水平扩展)
Kafka 中的 Topic(主题)是一个逻辑概念,而 Partition(分区)是物理概念。
- 突破单机限制: 如果一个 Topic 只有一份数据(不分区),那么这个 Topic 的大小受限于单个 Broker(服务器)的磁盘容量。但在大数据场景下,一个 Topic 可能包含 TB 甚至 PB 级的数据,单台机器根本存不下。
- 分布式存储: 通过引入分区,Kafka 可以将一个巨大的 Topic 切分成多个 Partition,并将这些 Partition 分散存储在集群中的不同 Broker 上。这意味着 Topic 的容量不再受限于单台机器,可以通过增加 Broker 数量来无限水平扩展存储能力。
2. 提高并发与吞吐量(计算层面的并行处理)
这是分区设计最直接的性能优势。
- 写入并行(Producer): 生产者可以并行地向同一个 Topic 的不同 Partition 发送消息。多个 Partition 分布在不同机器上,意味着写入负载被均衡到了整个集群,而不是集中在某一台机器的 I/O 上。
- 读取并行(Consumer): 这是 Kafka 高吞吐的关键。Kafka 引入了 消费者组(Consumer Group) 的概念:
- 并行消费: 在同一个消费者组内,一个 Partition 只能被一个消费者消费,但一个消费者可以消费多个 Partition。
- 性能线性提升: 如果一个 Topic 有 10 个分区,理论上你可以启动 10 个消费者实例进行并行消费。分区的数量决定了消费端并行度的上限。
- 无锁设计: 由于每个 Partition 内部是有序的,且只被一个消费者独占消费,Kafka 避免了复杂的分布式锁机制,极大提升了处理速度。
3. 实现高可用与故障容错(Replication Unit)
分区是 Kafka 进行数据复制(Replication)的基本单位。
- Leader 与 Follower: 每个 Partition 都有多个副本(Replica)。其中一个是 Leader,负责读写;其余是 Follower,负责同步数据。
- 故障转移: 如果某个 Broker 宕机,只有该 Broker 上作为 Leader 的 Partition 会受到影响。Kafka 控制器会迅速在其他存活的 Broker 上将对应的 Follower 提升为新的 Leader。
- 粒度合适: 如果以 Topic 为单位进行复制,一旦故障,恢复成本极高。以 Partition 为单位,可以将恢复流量分散到集群各处,实现精细化的容灾。
4. 消息顺序性的权衡
分区设计带来了一个重要的副作用(或者说设计取舍):Kafka 只能保证分区内的消息有序,不能保证 Topic 全局有序。
- 为什么不追求全局有序? 要实现全局有序,就必须让所有消息排队通过单一通道(单分区),这会使得系统吞吐量瞬间下降为单机性能,违背了分布式系统的初衷。
- 解决方案: 业务如果需要顺序(例如订单状态流转:创建->支付->发货),可以将消息的 Key 设置为 OrderID。Kafka 会利用 Hash 算法将相同 Key 的消息始终发送到同一个 Partition,从而保证局部有序。
总结
Kafka 采用分区设计是为了:
- 让数据存得下: 将海量数据切分,分布在多台机器上。
- 让读写跑得快: 允许多个生产者并行写,多个消费者并行读,极大提升吞吐量。
- 让系统死不了: 以分区为单位进行副本复制和故障转移,保证高可用。