 播面
播面 RabbitMQ消除队列存在大量积压应该如何处理?
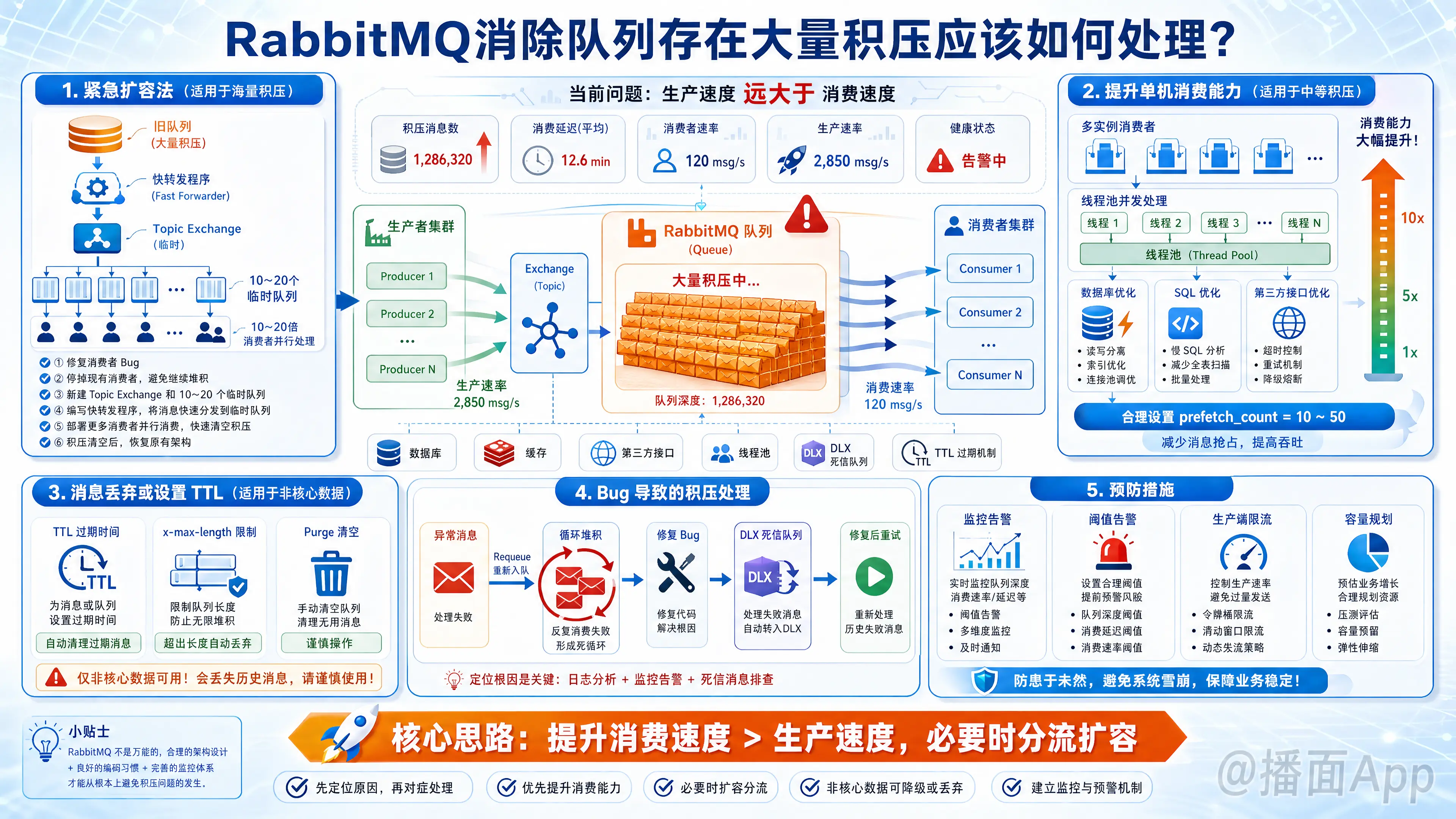
解决RabbitMQ积压的核心是提升消费速度。可通过增加消费者实例、开启多线程消费、优化业务逻辑、临时建立新队列分流扩容,或在非关键场景下丢弃数据来处理。
RabbitMQ 消息积压通常是由于生产速度远大于消费速度,或者消费者出现故障/Bug导致的。针对不同程度的积压和业务场景,可以采取以下几种处理方案:
1. 紧急扩容法(适用于海量积压)
当积压量非常大(如百万级),单纯增加消费者可能不够,或者由于队列自身的锁竞争导致瓶颈,需要采用临时分流的策略。
- 原理:将原来的“慢消费”逻辑改为“快转发”逻辑,通过新建多个临时队列并行处理。
- 步骤:
- 修复消费者:确保消费者逻辑没有 Bug,能够正常运行。
- 停掉现有消费者:暂时停止原有的消费者程序。
- 新建临时队列:新建一个 Topic Exchange 和 10~20 个临时队列(例如
temp_queue_1到temp_queue_10)。 - 编写分发程序:写一个临时的消费者程序(转发器),它不处理业务逻辑,只负责从原积压队列读取消息,并轮询写入这 10~20 个临时队列中(这一步速度极快)。
- 部署临时消费者:部署 10~20 倍数量的消费者实例,分别订阅这些临时队列,进行真正的业务逻辑消费。
- 恢复:等积压消费完毕后,恢复原有的架构。
2. 提升单机消费能力(适用于中等积压)
如果积压不是特别严重,可以通过优化现有消费者来解决。
- 增加消费者实例:在服务器资源允许的情况下,直接横向扩展,部署更多的消费者进程。
- 开启多线程消费:在单个消费者进程内部,使用线程池并行处理消息(注意线程安全问题)。
- 优化业务逻辑:
- 减少数据库交互次数(如使用批量插入/更新)。
- 优化 SQL 语句或索引。
- 减少对第三方接口的同步调用(或增加超时控制)。
- 调整
prefetch_count:合理设置 QoS(服务质量),避免一次拉取太多消息阻塞内存,也不要一次拉取一条导致网络频繁交互。通常设置为 10-50 左右视业务耗时而定。
3. 消息丢弃或设置 TTL(适用于非核心数据)
如果积压的消息是非核心数据(如日志、非必要的通知),且业务允许部分丢失,可以采用“断臂求生”的策略。
- 设置消息 TTL(过期时间):让积压过久的消息自动过期丢弃。
- 限制队列长度:设置
x-max-length,超过长度的消息自动挤出或丢弃。 - 直接 Purge:在管理后台直接清空队列(慎用,数据会全部丢失)。
4. 针对 Bug 导致的积压
如果是因为消费者程序 Bug 导致抛出异常,消息不断重回队列(Requeue)造成的死循环积压:
- 处理:立即修复 Bug 并发布更新。
- 死信队列(DLX):如果短期无法修复,应配置死信队列。将处理失败的消息因无法消费转移到死信队列中存储起来,待 Bug 修复后,再编写程序从死信队列中读出并重新处理。
5. 预防措施
- 监控报警:建立完善的监控(如 Prometheus + Grafana),当队列积压超过阈值时第一时间报警。
- 生产端限流:如果消费端实在处理不过来,可以在生产端做限流保护,避免系统雪崩。