 播面
播面 RocketMQ Broker 的主从架构(Master/Slave)是如何同步数据的?
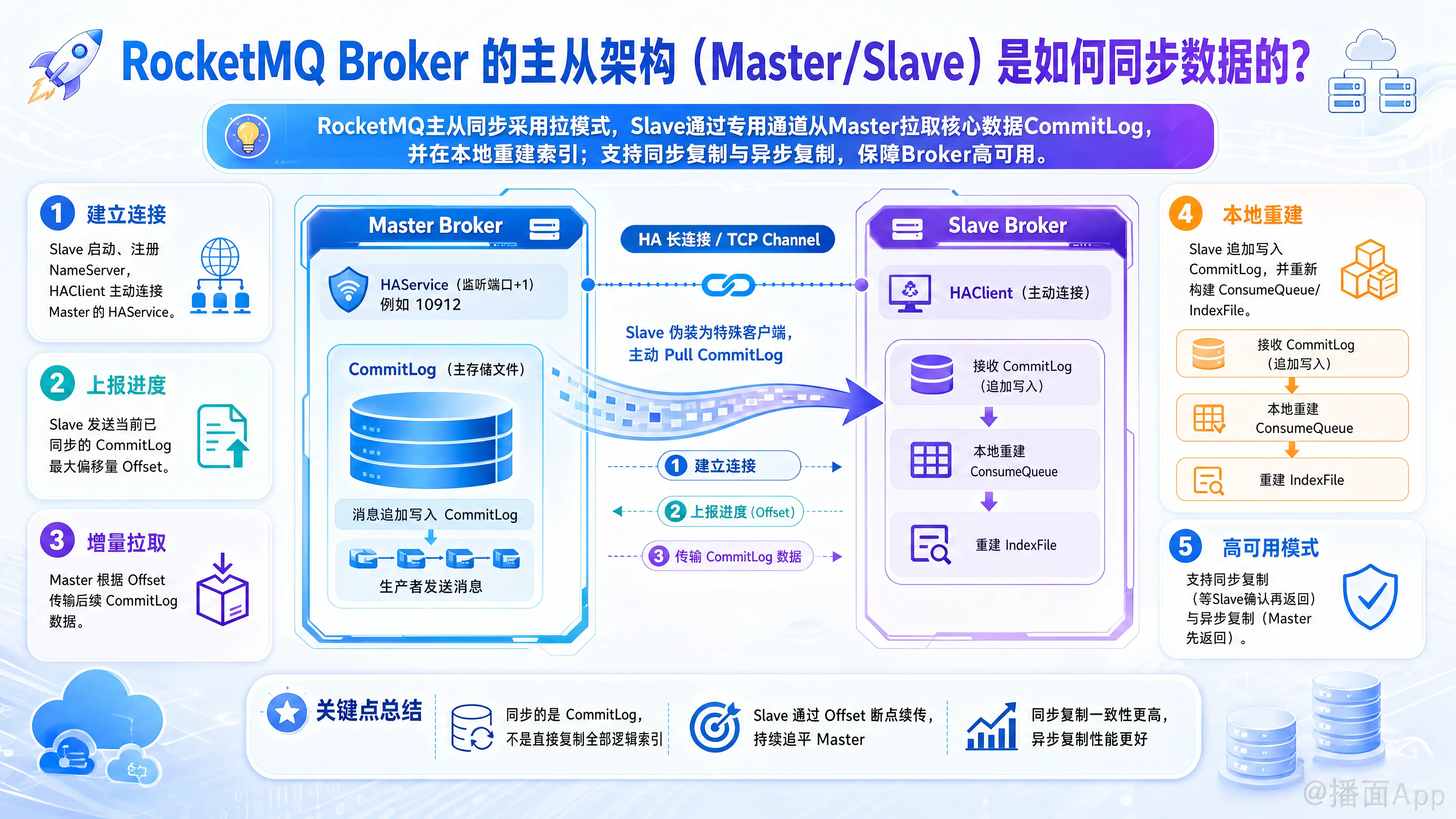
RocketMQ主从同步采用拉模式,Slave通过专用通道从Master拉取核心数据CommitLog,并在本地重建索引。提供同步和异步复制模式,以实现Broker高可用。
我们来详细解析一下 RocketMQ Broker 主从架构(Master/Slave)的数据同步机制。

核心思想:基于 CommitLog 的主从复制
RocketMQ 的主从同步核心思想非常清晰:Slave Broker 伪装成一个特殊的客户端,主动从 Master Broker 拉取(Pull)数据。
这个过程同步的主要数据是 CommitLog 文件,它是 RocketMQ 中存储所有消息的物理文件。只要 Master 和 Slave 的 CommitLog 文件保持一致,那么 Slave 就可以通过重新解析 CommitLog 来构建出与 Master 完全相同的其他逻辑数据,如 ConsumeQueue 和 IndexFile。
数据同步的详细流程
这个过程可以分解为以下几个关键步骤:
1. 建立连接(HA Connection)
- 启动与注册:当一个 Slave Broker 启动时,它会像 Master 一样向 NameServer 注册。在注册信息中,它会明确自己的角色是 Slave,并带上自己的 BrokerId(非 0,Master 的 BrokerId 为 0)以及所属 Master 的地址。
- 建立主从连接:Slave 启动后,内部会有一个名为
HAService的服务。该服务会启动一个客户端(HAClient),主动连接到其配置的 Master Broker 的HAService端口(默认为Master监听端口 + 1,例如 10912)。 - 长连接通道:一旦连接成功,Master 和 Slave 之间就建立了一个专门用于数据同步的长连接 TCP 通道,我们称之为 HA Channel。
2. 发起数据拉取请求
- 报告自身进度:连接建立后,Slave 会立即向 Master 发送第一个数据拉取请求。这个请求中最重要的信息是 Slave 当前
CommitLog文件中已同步的最大物理偏移量(maxPhyOffset)。- 如果 Slave 是第一次启动,这个偏移量就是 0。
- 如果 Slave 是重启,它会读取本地
CommitLog的大小,将该值作为起始偏移量。
- 持续拉取循环:这个请求-响应的过程会形成一个持续不断的循环,确保数据近乎实时地同步。
3. Master 处理请求并返回数据
- 定位数据:Master 的
HAService收到 Slave 的请求后,获取到 Slave 请求的offset。 - 读取数据:Master 会从自己的
CommitLog文件中,从该offset开始向后读取一段数据(例如,默认一次最多读取 32KB)。 - 数据打包:Master 将读取到的
CommitLog数据块,连同这段数据的起始偏移量和总长度,打包成一个响应包。 - 发送数据:通过 HA Channel 将这个响应包发送给 Slave。
- 等待下一次请求:如果 Master 发现 Slave 请求的
offset已经追上了自己的最新进度(即没有新消息了),Master 会挂起(hold)这个请求,等待新的消息写入后,再将新消息返回给 Slave,这是一种高效的 长轮询(Long Polling)机制,避免了 Slave 无效的空轮询。
4. Slave 处理数据并更新进度
- 接收数据:Slave 的
HAClient接收到 Master 发来的数据包。 - 解析并写入:Slave 解析数据包,提取出
CommitLog数据,并将其顺序追加到自己的CommitLog文件中。 - 更新本地偏移量:写入成功后,Slave 更新自己内存中记录的
maxPhyOffset。 - 发起下一次请求:Slave 立即使用这个新的
maxPhyOffset作为请求参数,向 Master 发起下一次数据拉取请求。
通过这个 “Slave请求 -> Master响应 -> Slave写入 -> Slave再请求” 的闭环,Slave 不断地从 Master 拉取增量数据,从而使自己的 CommitLog 与 Master 保持同步。
同步了哪些数据?
核心数据:CommitLog
- 这是主从同步的唯一通道传输的核心业务数据。所有 Topic 的消息都混合存储在
CommitLog中。
- 这是主从同步的唯一通道传输的核心业务数据。所有 Topic 的消息都混合存储在
元数据(Metadata)
- 除了消息实体,Broker 的正常运行还需要很多元数据,例如 Topic 配置、消费组配置、消费进度(Consumer Offset)等。
- 这些元数据的同步不通过 HA Channel。而是 Master Broker 在收到配置变更或定时任务触发时,通过一个普通的 RPC 请求,将
topics.json,subscriptionGroup.json,consumerOffset.json等配置文件的内容同步给所有关联的 Slave。这确保了主从在配置层面也是一致的。
自构建数据:ConsumeQueue 和 IndexFile
- 这两个文件是消息的“索引”,用于加速消费和查询。
- 它们不会通过网络从 Master 同步到 Slave。
- Slave 上有一个独立的线程(
ReputMessageService),它会实时地扫描本地CommitLog中新增的数据,然后像 Master 一样,在本地重新构建ConsumeQueue和IndexFile。 - 这种设计的巨大好处是简化了同步逻辑,主从同步只用关心单一的、顺序写的
CommitLog文件,大大降低了复杂性和出错的概率。
两种同步模式
RocketMQ 提供了两种主从同步模式,以平衡数据可靠性和消息发送性能。这主要影响 Producer 发送消息的流程。
1. 同步复制 (Synchronous Replication - SYNC_MASTER)
这是默认和推荐的模式,提供最高的数据可靠性。
- 流程:
- Producer 发送消息到 Master Broker。
- Master 将消息写入自己的
CommitLog。 - Master 等待,直到消息通过 HA Channel 成功同步到至少一个 Slave Broker。
- Slave 返回确认信息给 Master。
- Master 收到 Slave 的确认后,才向 Producer 返回 "发送成功" 的响应。
- 优点:数据零丢失。即使 Master 在返回成功后立即宕机,消息也已经在 Slave 上有备份,可以保证不丢失。
- 缺点:增加了消息发送的延迟(RT),因为需要等待一次主从网络交互。
2. 异步复制 (Asynchronous Replication - ASYNC_MASTER)
这种模式下,性能更高,但存在丢失少量数据的风险。
- 流程:
- Producer 发送消息到 Master Broker。
- Master 将消息写入自己的
CommitLog后,立即向 Producer 返回 "发送成功" 的响应。 - Master 在后台异步地将消息推送给 Slave。
- 优点:消息发送延迟低,吞吐量更高。
- 缺点:如果 Master 在返回成功后、但消息还未同步到 Slave 之前突然宕机(例如磁盘损坏、断电),那么这部分消息就会永久丢失。
总结
| 特性 | 描述 |
|---|---|
| 同步模型 | 拉模式(Pull Model):Slave 主动向 Master 拉取数据。 |
| 核心通道 | HA Channel:一个专用于数据复制的长连接。 |
| 同步内容 | 主要同步 CommitLog 文件。 |
| 索引构建 | ConsumeQueue 和 IndexFile 在 Slave 端本地重建,不通过网络传输。 |
| 元数据同步 | Topic、消费组等配置信息通过独立的 RPC 进行同步。 |
| 复制模式 | 提供同步复制和异步复制两种模式,用于在可靠性和性能之间做权衡。 |
| 设计目标 | 实现 Broker 的高可用(High Availability),当 Master 宕机时,Slave 可以无缝(或少量数据丢失)接替工作。 |