 播面
播面 MySQL中有哪些常见的索引类型?
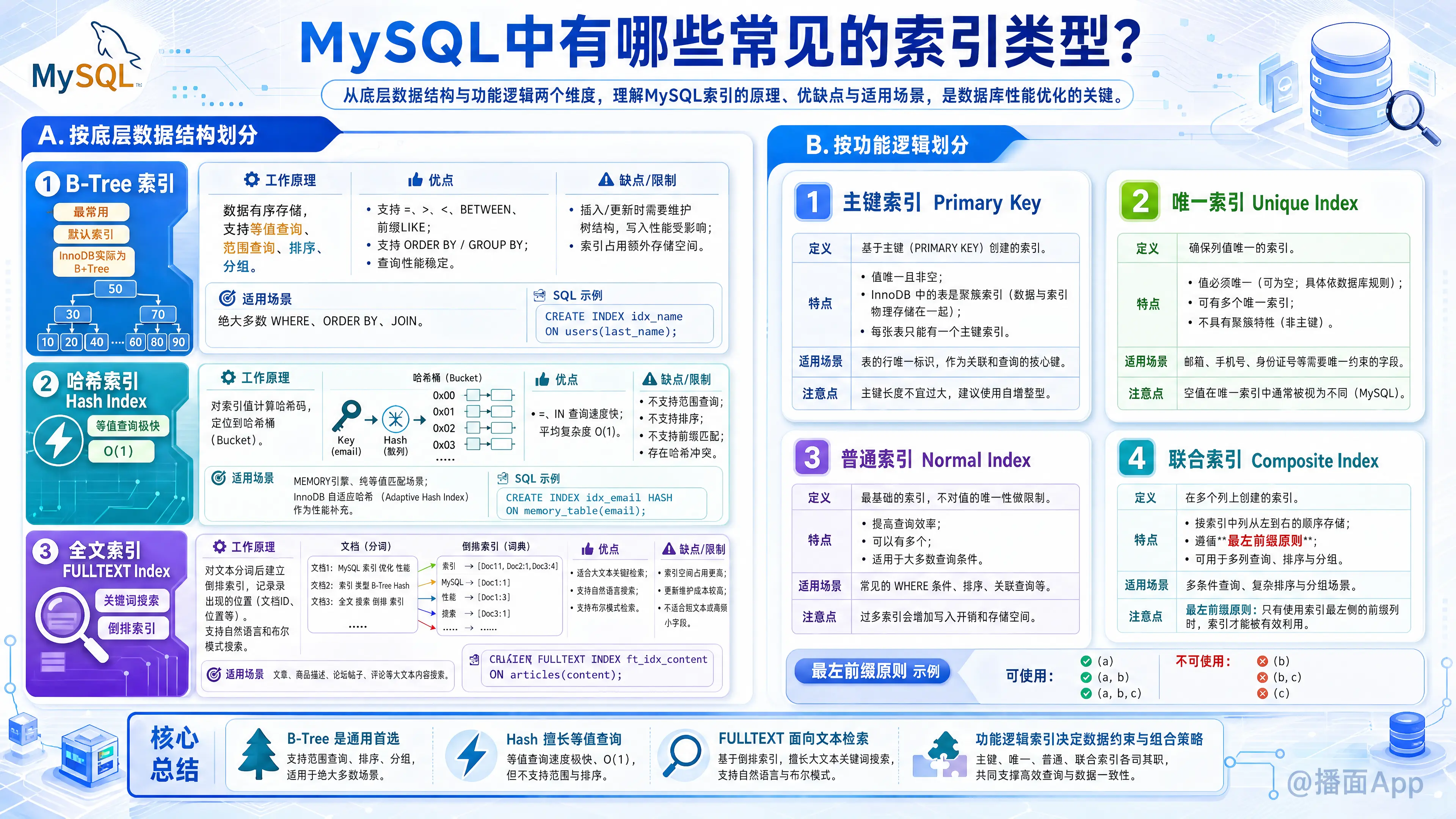
本文介绍了MySQL常见的索引类型。主要从底层数据结构(如B-Tree、哈希)和功能逻辑(如主键、唯一索引)两个维度进行划分,并阐述了各类索引的原理、优缺点及适用场景,是数据库性能优化的关键。
在MySQL中,索引是提高数据库查询性能的关键。了解不同类型的索引及其适用场景,对于数据库设计和优化至关重要。
我们可以从两个维度来理解MySQL的索引:按底层数据结构划分和按功能逻辑划分。
一、按底层数据结构划分
这是最核心的分类,决定了索引如何工作以及其性能特点。
1. B-Tree 索引 (B树索引)
这是MySQL中最常用、也是默认的索引类型。几乎所有的存储引擎(如 InnoDB 和 MyISAM)都支持B-Tree索引。
- 工作原理:B-Tree(实际上在InnoDB中是B+Tree)中的数据是有序存储的。这使得它不仅能处理等值查询(
=),还能高效地处理范围查询(>、<、BETWEEN、LIKE '前缀%')和排序(ORDER BY)。 - 优点:
- 支持等值查询、范围查询。
- 支持排序和分组(
ORDER BY,GROUP BY)。 - 查询效率相对稳定。
- 适用场景:绝大多数情况下的首选。适用于各种
WHERE条件、ORDER BY和JOIN操作。 - 示例:sql
CREATE INDEX idx_name ON users(last_name);
2. 哈希索引 (Hash Index)
哈希索引基于哈希表实现,只有精确匹配索引所有列的查询才有效。
- 工作原理:对索引列的值计算一个哈希码,并将哈希码和指向数据行的指针存入哈希表中。查询时,再次计算哈希码,直接定位到数据行,因此速度非常快。
- 优点:
- 对于等值查询(
=或IN)速度极快,时间复杂度为 O(1)。
- 对于等值查询(
- 缺点:
- 不支持范围查询:因为哈希后的值是无序的。
- 不支持排序:无法利用索引进行
ORDER BY操作。 - 不支持前缀匹配:无法用于
LIKE 'abc%'。 - 哈希冲突可能导致性能下降。
- 适用场景:主要用于
MEMORY存储引擎。InnoDB也有一种“自适应哈希索引”,是其内部自动优化的,用户无法直接创建。适合只有等值查询的场景。 - 示例:sql
-- 只有MEMORY引擎支持显式创建HASH索引 CREATE TABLE memory_table ( id INT, email VARCHAR(100) ) ENGINE = MEMORY; CREATE INDEX idx_email HASH ON memory_table(email);
3. 全文索引 (FULLTEXT Index)
用于在大量文本内容中进行关键词搜索,而不是简单的等值或范围比较。
- 工作原理:它会对文本内容进行分词,并创建一个“倒排索引”,记录每个词出现在哪些文档中。这使得它能快速响应“包含某个词”的查询。
- 优点:
- 可以高效地在
CHAR,VARCHAR,TEXT类型的列中搜索关键词。 - 支持自然语言搜索和布尔搜索模式。
- 可以高效地在
- 缺点:
- 比B-Tree索引占用更多空间。
- 更新数据时维护索引的成本较高。
- 适用场景:文章内容搜索、产品描述搜索、论坛帖子搜索等。
- 使用方式:必须配合
MATCH() ... AGAINST()语法使用。 - 示例:sql
CREATE FULLTEXT INDEX ft_idx_content ON articles(title, body); -- 查询 SELECT * FROM articles WHERE MATCH(title, body) AGAINST('database performance');
4. 空间索引 (SPATIAL Index)
用于地理空间数据类型(如 GEOMETRY, POINT 等),可以高效地进行地理位置相关的查询。
- 工作原理:通常使用 R-Tree 数据结构来索引空间数据。
- 适用场景:地图应用、LBS(基于位置的服务)应用,如“查找我附近1公里内的餐厅”。
- 示例:sql
-- 假设 stores 表有一个 location 字段,类型为 GEOMETRY CREATE SPATIAL INDEX sp_idx_location ON stores(location);
二、按功能逻辑划分
这是从应用层面上的分类,它们通常是基于B-Tree索引实现的,但附加了不同的约束和功能。
1. 主键索引 (Primary Key)
一种特殊的唯一索引,用于唯一标识表中的每一行。
- 特点:
- 值必须唯一 (
UNIQUE)。 - 值不能为空 (
NOT NULL)。 - 一张表只能有一个主键。
- 值必须唯一 (
- InnoDB中的特殊性:在InnoDB中,主键索引是聚簇索引(Clustered Index),这意味着表数据是按照主键的顺序物理存储的。所有其他非主键索引(二级索引)都会存储主键的值作为指针。
2. 唯一索引 (Unique Index)
确保索引列中的所有值都是唯一的,但允许有多个 NULL 值。
- 特点:
- 保证了数据的唯一性。
- 可以有
NULL值。
- 示例:sql
CREATE UNIQUE INDEX idx_unique_email ON users(email);
3. 普通索引 (Normal Index / Non-Unique Index)
最基本的索引类型,没有任何限制,仅仅是为了加速查询。
- 特点:
- 允许列值重复。
- 允许
NULL值。
- 示例:sql
CREATE INDEX idx_lastname ON users(last_name);
4. 组合索引 (Composite / Multi-column Index)
在多个列上创建的索引。
- 特点:
- 遵循“最左前缀原则”。例如,在
(col1, col2, col3)上创建了索引,那么查询条件为(col1)、(col1, col2)、(col1, col2, col3)时都能使用该索引,但如果查询条件只有(col2)或(col2, col3),则无法使用该索引。
- 遵循“最左前缀原则”。例如,在
- 适用场景:当查询条件经常涉及多个列时,创建组合索引通常比创建多个单列索引更高效。
- 示例:sql
CREATE INDEX idx_name_age ON users(last_name, first_name, age);
总结表格
| 索引类型 | 底层结构/逻辑 | 主要特点 | 适用场景 |
|---|---|---|---|
| B-Tree 索引 | 数据结构 | 数据有序,支持等值、范围查询和排序 | 绝大多数场景,默认选择 |
| 哈希索引 | 数据结构 | 仅支持等值查询,速度极快 | MEMORY引擎,或等值查询为主的场景 |
| 全文索引 | 数据结构 | 用于文本内容关键词搜索,使用MATCH...AGAINST |
文章、博客、产品描述等大段文本搜索 |
| 空间索引 | 数据结构 | 用于地理空间数据查询 | LBS应用、地图相关功能 |
| 主键索引 | 逻辑 | UNIQUE + NOT NULL,InnoDB中为聚簇索引 |
唯一标识表中的每一行 |
| 唯一索引 | 逻辑 | 保证列值唯一,允许NULL |
用户名、邮箱等需要保持唯一性的字段 |
| 普通索引 | 逻辑 | 无特殊限制,仅用于加速查询 | 普通的查询加速场景 |
| 组合索引 | 逻辑 | 多个列上的索引,遵循最左前缀原则 | 多个字段经常同时出现在WHERE或ORDER BY中 |
了解这些索引类型,并根据你的业务查询特点选择合适的索引,是MySQL性能优化的第一步也是最重要的一步。