 播面
播面 在Flink实际生产应用中,都遇到了哪些 checkpoint 反压的情况,又是如何解决的?
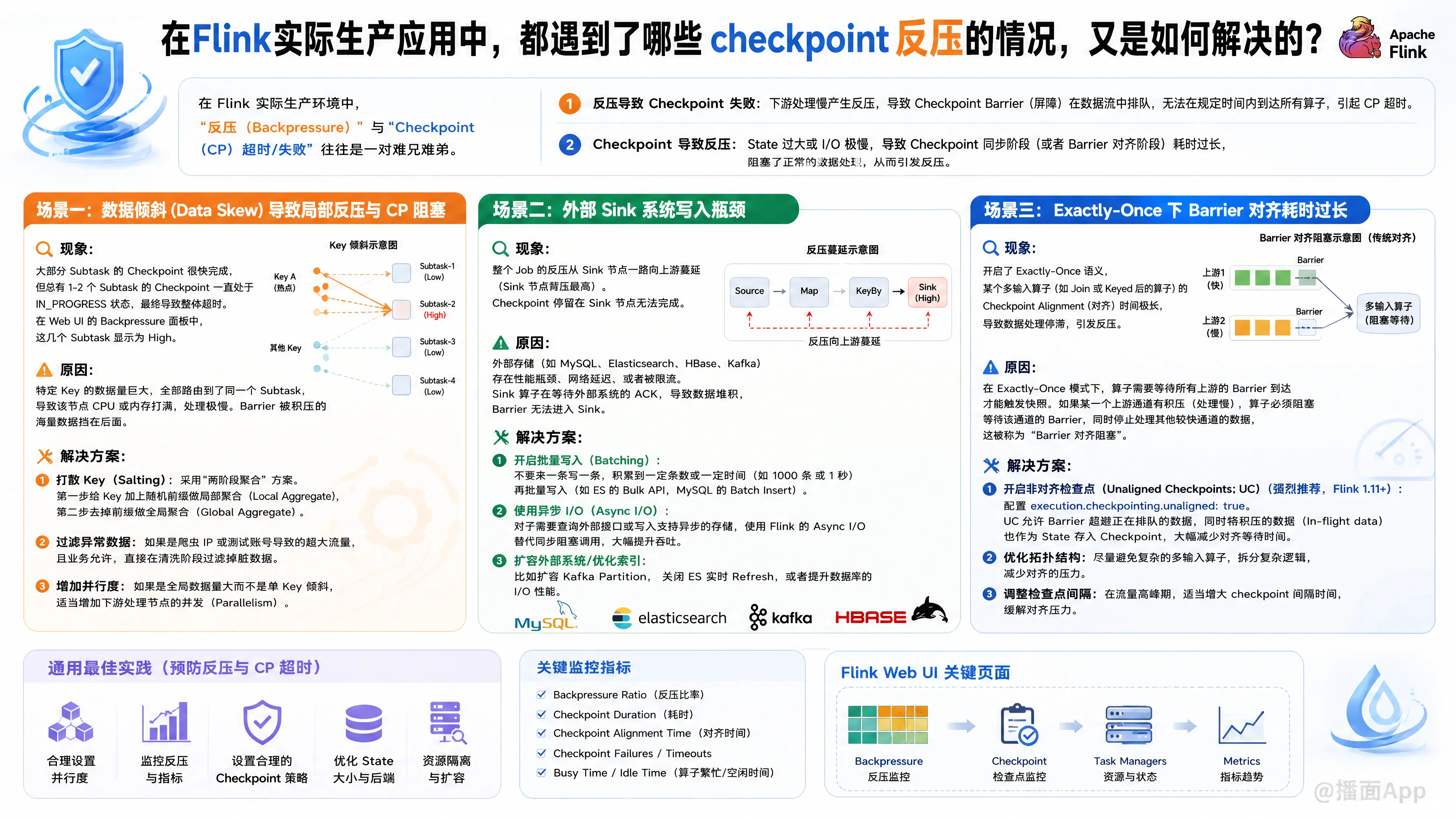
在 Flink 实际生产环境中,“反压(Backpressure)”与“Checkpoint(CP)超时/失败”往往是一对难兄难弟。
通常有两种互为因果的情况:
- 反压导致 Checkpoint 失败:下游处理慢产生反压,导致 Checkpoint Barrier(屏障)在数据流中排队,无法在规定时间内到达所有算子,引起 CP 超时。
- Checkpoint 导致反压:State 过大或 I/O 极慢,导致 Checkpoint 同步阶段(或者 Barrier 对齐阶段)耗时过长,阻塞了正常的数据处理,从而引发反压。
以下是生产环境中最常见的几种 Checkpoint 与反压交织的场景及其解决思路:
场景一:数据倾斜 (Data Skew) 导致局部反压与 CP 阻塞
现象:
大部分 Subtask 的 Checkpoint 很快完成,但总有 1-2 个 Subtask 的 Checkpoint 一直处于 IN_PROGRESS 状态,最终导致整体超时。在 Web UI 的 Backpressure 面板中,这几个 Subtask 显示为 High。
原因:
特定 Key 的数据量巨大,全部路由到了同一个 Subtask,导致该节点 CPU 或内存打满,处理极慢。Barrier 被积压的海量数据挡在后面。
解决方案:
- 打散 Key(Salting):对于 GroupBy/KeyBy 倾斜,采用“两阶段聚合”方案。第一步给 Key 加上随机前缀做局部聚合(Local Aggregate),第二步去掉前缀做全局聚合(Global Aggregate)。
- 过滤异常数据:如果是爬虫 IP 或测试账号导致的超大流量,且业务允许,直接在清洗阶段过滤掉脏数据。
- 增加并行度:如果是全局数据量大而不是单 Key 倾斜,适当增加下游处理节点的并发(Parallelism)。
场景二:外部 Sink 系统写入瓶颈
现象:
整个 Job 的反压从 Sink 节点一路向上游蔓延(Sink 节点背压最高)。Checkpoint 停留在 Sink 节点无法完成。
原因:
外部存储(如 MySQL、Elasticsearch、HBase、Kafka)存在性能瓶颈、网络延迟、或者被限流。Sink 算子在等待外部系统的 ACK,导致数据堆积,Barrier 无法进入 Sink。
解决方案:
- 开启批量写入(Batching):不要来一条写一条,积累到一定条数或一定时间(如 1000条 或 1秒)再批量写入(如 ES 的 Bulk API,MySQL 的 Batch Insert)。
- 使用异步 I/O(Async I/O):对于需要查询外部接口或写入支持异步的存储,使用 Flink 的 Async I/O 替代同步阻塞调用,大幅提升吞吐。
- 扩容外部系统/优化索引:比如扩容 Kafka Partition,关闭 ES 实时 Refresh,或者提升数据库的 I/O 性能。
场景三:Exactly-Once 下 Barrier 对齐耗时过长
现象:
开启了 Exactly-Once 语义,某个多输入算子(如 Join 或 Keyed 后的算子)的 Checkpoint Alignment(对齐)时间极长,导致数据处理停滞,引发反压。
原因:
在 Exactly-Once 模式下,算子需要等待所有上游的 Barrier 到达才能触发快照。如果某一个上游通道有积压(处理慢),算子必须阻塞等待该通道的 Barrier,同时停止处理其他较快通道的数据,这被称为“Barrier 对齐阻塞”。
解决方案:
- 开启非对齐检查点(Unaligned Checkpoints, UC)(强烈推荐,Flink 1.11+):
配置execution.checkpointing.unaligned: true。UC 允许 Barrier 超越正在排队的数据,同时将积压的数据(In-flight data)也作为 State 存入 Checkpoint。这彻底解决了反压导致 CP 失败的问题。 - 开启 Buffer Debloating(缓冲去胀)(Flink 1.14+):
配合 UC 使用,动态调整网络 Buffer 大小,减少网络层积压的数据量,从而减小 UC 保存的数据量。 - 降级为 At-Least-Once:如果业务允许少量重复数据,将 CP 语义改为 At-Least-Once,不需要 Barrier 对齐。
场景四:大状态(State)与 RocksDB I/O 瓶颈
现象:
无明显数据堆积,但每次 Checkpoint 发生时,系统 CPU 飙升,出现周期性反压(毛刺)。同步快照时间(Sync Duration)或者异步上传时间(Async Duration)特别长。
原因:
状态极其庞大(几十 GB 甚至 TB 级)。如果使用 RocksDB,可能磁盘 I/O 跟不上(尤其是机械硬盘),或者频繁触发 RockDB 的 Compaction 占用大量 CPU 和 I/O,阻塞了主处理线程。
解决方案:
- 开启增量 Checkpoint:确保
state.backend.incremental: true,只上传差异状态。 - 使用本地恢复(Local Recovery):配置
state.backend.local-recovery: true。在本地保留一份 State 副本,Task 恢复时优先从本地读,极大地减轻远程 DFS(如 HDFS/S3)的压力和网络开销。 - 更换 SSD 磁盘:RocksDB 对磁盘 I/O 极其敏感,生产环境跑 RocksDB 必须挂载 SSD(NVMe 最佳)。
- 调整 RocksDB 参数:调整
state.backend.rocksdb.memory.managed: true,适当调大 RocksDB 的 WriteBuffer 和 BlockCache。 - 开启 Changelog State Backend(Flink 1.15+):引入通用的增量 Checkpoint 机制,通过将状态变更先写入 Changelog,极大缩短同步阶段耗时。
场景五:频繁的 GC(垃圾回收)导致 STW
现象:
任务不定期出现反压,Checkpoint 经常在某个 Subtask 上莫名其妙超时。查看 TaskManager 日志发现大量的 Full GC 或频繁的 Young GC,甚至 OOM。
原因:
用户代码中创建了大量短生命周期的大对象,或者使用了大窗口(Window)在触发时产生内存暴涨,导致 JVM 发生 Stop-The-World (STW)。由于线程被挂起,无法处理数据和转发 Barrier。
解决方案:
- 优化数据结构与代码:避免在 Map/Process 函数中频繁 new 大对象(如大集合),尽量复用对象。
- 内存结构调整:如果使用 HeapStateBackend 且状态较大,果断切换到 RocksDB(将状态放到堆外托管内存,不受 JVM GC 影响)。
- 优化 Window 触发计算:避免在窗口结束时一次性全量计算(ProcessWindowFunction)。尽量结合
ReduceFunction或AggregateFunction进行增量预聚合。 - 调整 JVM 参数:适当调大 TaskManager Heap 内存,更换垃圾回收器(如使用 G1 GC)。
场景六:复杂算子的同步阻塞调用
现象:
某个 Map/FlatMap 算子产生严重反压,Barrier 无法通过。
原因:
在用户代码中调用了外部 HTTP 接口、执行了复杂的正则匹配、或者进行了耗时的解压缩/加解密操作,且是单线程同步阻塞调用。
解决方案:
- 对于外部请求:必须改用 Async I/O。
- 对于耗时计算:如果 CPU 是瓶颈,只能通过增加并行度(扩容)来解决,或者优化自身的计算逻辑(比如预编译正则表达式,避免每次重复编译)。
总结:生产环境排查套路
在遇到 Flink 反压和 Checkpoint 失败时,我们一般遵循以下排查流程:
- 定位反压源头:打开 Flink Web UI -> 找到反压为 High 的算子。注意,红色的往往是受害者,真正的瓶颈是反压红色节点后面的那个正常的节点(或者红色节点的最末端)。
- 看 Checkpoint 详情:看是在哪个算子、哪个 Subtask 卡住。看
Sync Duration(同步耗时,看本地I/O和状态大小)还是Alignment Duration(对齐耗时,看数据倾斜和反压)。 - 检查外部环境:看机器 CPU、磁盘 I/O、网络监控,看外部 Sink 系统监控(是否有慢查询、锁等待)。
- 看火焰图/Thread Dump:Flink UI 开启 FlameGraph,看 CPU 到底耗在哪个函数上(是 GC,是正则,还是等待外部网络锁)。
终极“银弹”:在现代 Flink(1.14+)生产中,如果是纯粹因为数据洪峰反压导致的 CP 失败,开启 非对齐检查点(Unaligned Checkpoint)+ 缓冲去胀(Buffer Debloating) 通常能立竿见影地解决 80% 以上的问题。