 播面
播面 MyBatis的二级缓存是如何工作的?
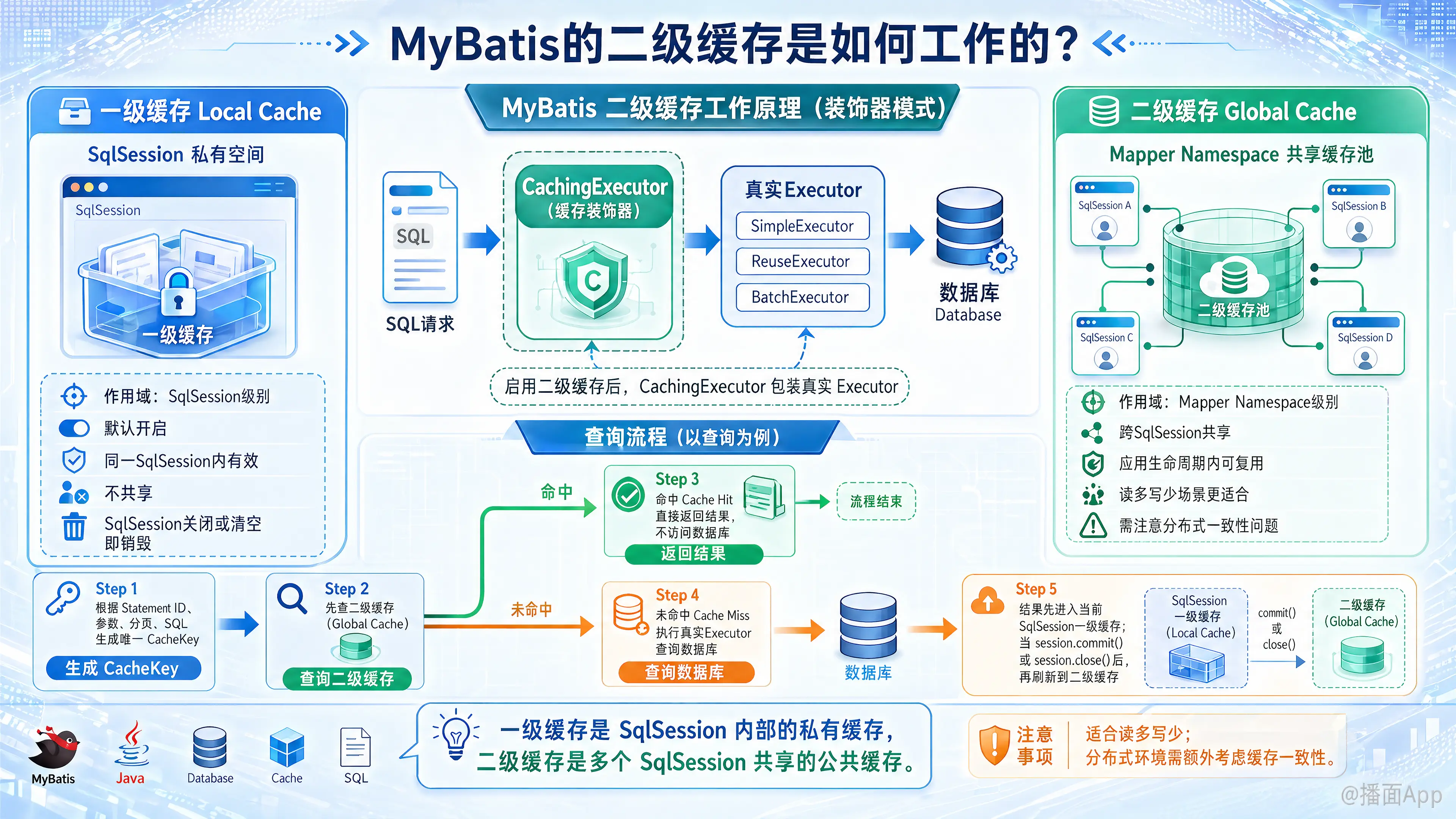
MyBatis二级缓存是Mapper级别的共享缓存,跨SqlSession生效。它在会话关闭或提交后将数据存入,适合读多写少场景,但需注意分布式环境下的一致性问题。
我们来详细、清晰地剖析一下MyBatis的二级缓存是如何工作的。
一、 什么是MyBatis二级缓存?
首先,要理解二级缓存,我们需要先对比一下一级缓存。
一级缓存(Local Cache):
- 作用域:
SqlSession级别。它是默认开启且无法关闭的。 - 生命周期:与
SqlSession的生命周期相同。当SqlSession被创建时,一个新的一级缓存被创建;当SqlSession被关闭或清空时,它里面的一级缓存也随之销毁。 - 工作方式:在同一个
SqlSession中,执行完全相同的SQL查询(相同的Statement ID、相同的参数等),第一次查询会从数据库获取数据并放入缓存,后续的查询会直接从这个缓存中获取,不再请求数据库。 - 共享性:一级缓存是不共享的。不同的
SqlSession实例之间,它们的一级缓存是相互隔离的。
- 作用域:
二级缓存(Global Cache):
- 作用域:
Mapper Namespace级别,也就是一个Mapper映射文件。 - 生命周期:与应用程序的生命周期相同。一旦数据被缓存,它可以被该
Namespace下的所有SqlSession共享。 - 工作方式:当一个
SqlSession提交了事务(session.commit())或者关闭了(session.close())之后,它的一级缓存中的数据才会被刷新到二级缓存中。这样,其他新的SqlSession就可以访问到这些被缓存的数据。 - 共享性:二级缓存是跨
SqlSession共享的。
- 作用域:
一句话总结:一级缓存是SqlSession内部的“私有缓存”,二级缓存是多个SqlSession可以共享的“公共缓存”。
二、 二级缓存的工作原理
MyBatis的二级缓存工作流程可以用经典的装饰器模式(Decorator Pattern)来解释。
Executor 体系结构:
MyBatis的核心操作由Executor接口执行。它有几个实现类:SimpleExecutor: 每执行一次update或select,就开启一个Statement对象,用完立刻关闭。ReuseExecutor: 重复使用Statement对象。BatchExecutor: 批量执行SQL。
CachingExecutor 的介入:
当你启用了二级缓存后,MyBatis会创建一个CachingExecutor实例。这个CachingExecutor会包装(装饰)一个真实的Executor(比如SimpleExecutor)。因此,执行流程变成了:
SQL请求->CachingExecutor->SimpleExecutor->数据库查询流程(Cache Hit / Cache Miss):
当一个查询请求到来时:- 步骤 1: 查询二级缓存
CachingExecutor首先会根据查询请求(包括Statement ID、参数、分页信息、SQL语句等)生成一个唯一的CacheKey。 - 步骤 2: 判断缓存命中
CachingExecutor会用这个CacheKey去二级缓存中查找数据。- 缓存命中(Cache Hit):如果找到了对应的数据,它会直接将数据返回给调用者,不会再执行后续的
SimpleExecutor,也不再查询数据库。 - 缓存未命中(Cache Miss):如果没有找到数据,请求会继续传递给被它包装的
SimpleExecutor。
- 缓存命中(Cache Hit):如果找到了对应的数据,它会直接将数据返回给调用者,不会再执行后续的
- 步骤 3: 查询数据库并缓存结果
SimpleExecutor会像往常一样去查询数据库,获取结果。 - 步骤 4: 结果存入一级缓存
查询到的结果首先会被放入一级缓存(SqlSession级别)。 - 步骤 5: 将结果推送到二级缓存
当SqlSession关闭(session.close())或提交(session.commit())时,CachingExecutor会检查一级缓存中的数据,并将这些数据刷新(放入)到二级缓存中。这一步是关键,它使得数据能够被其他SqlSession访问。
- 步骤 1: 查询二级缓存
更新/插入/删除操作(缓存刷新):
当执行insert、update或delete操作时,为了保证数据的一致性,CachingExecutor会清空(flush)该Namespace下的所有二级缓存条目。这是默认行为,可以通过在statement标签上设置flushCache="false"来改变,但通常不建议这么做。
三、 如何开启和配置二级缓存
开启二级缓存需要满足以下几个条件:
全局开启缓存:
在mybatis-config.xml中,确保cacheEnabled设置为true(这是默认值)。xml<settings> <setting name="cacheEnabled" value="true"/> </settings>在Mapper XML中声明缓存:
在需要开启二级缓存的Mapper映射文件(如UserMapper.xml)中,添加<cache/>标签。xml<mapper namespace="com.example.mapper.UserMapper"> <!-- 开启该namespace的二级缓存 --> <cache/> <select id="getUserById" resultType="com.example.model.User"> SELECT * FROM users WHERE id = #{id} </select> <!-- ...其他语句 --> </mapper>实体类必须序列化:
所有需要被二级缓存的POJO(实体类)都必须实现java.io.Serializable接口。
原因:二级缓存的数据可能存储在内存、硬盘或者像Redis这样的分布式缓存中。序列化是将Java对象转换为字节流的过程,这样才能在不同的存储介质中进行读写和传输。即使是默认的内存缓存,为了实现readOnly=false(返回一个对象的拷贝而非引用),也需要通过序列化和反序列化来创建副本。javaimport java.io.Serializable; public class User implements Serializable { private static final long serialVersionUID = 1L; // 建议添加 private Integer id; private String name; // ... getters and setters }SqlSession必须关闭或提交:
查询操作所在的SqlSession必须被commit()或close(),其一级缓存中的数据才会被刷新到二级缓存。javatry (SqlSession session = sqlSessionFactory.openSession()) { UserMapper mapper = session.getMapper(UserMapper.class); User user = mapper.getUserById(1); // ... } // try-with-resources 会自动调用 session.close() // 此时,user对象才会被放入二级缓存
四、 <cache/> 标签的详细配置
<cache/>标签提供了丰富的属性来定制缓存策略:
<cache
eviction="LRU" <!-- 驱逐策略,默认LRU (最近最少使用) -->
flushInterval="60000" <!-- 刷新间隔,单位毫秒。不设置则无间隔 -->
size="1024" <!-- 缓存对象数量,默认1024 -->
readOnly="false" <!-- 是否只读。默认为false -->
blocking="false" <!-- 是否阻塞,默认为false -->
/>eviction: 缓存驱逐策略。LRU(Least Recently Used) - 最近最少使用(默认)。FIFO(First In First Out) - 先进先出。SOFT- 软引用,基于垃圾回收器状态和软引用规则。WEAK- 弱引用,更积极地被垃圾回收。
flushInterval: 自动刷新缓存的时间间隔,单位毫秒。如果设置了,缓存会每隔指定时间被清空一次。size: 缓存中最多可以存储的对象数量。readOnly:true(只读):缓存会直接返回对象的引用。这样做性能更高,但不安全,因为多个调用者可能会修改同一个对象,导致数据混乱。false(读写,默认):缓存会返回对象的拷贝(通过序列化和反序列化实现)。这样做更安全,但性能开销稍大。
五、 使用场景和注意事项
适合使用的场景:
- 读多写少的数据,如系统配置、字典数据、国家地区列表等。
- 数据变化频率低,对实时性要求不高的数据。
- 查询结果集不会过大,否则会占用大量内存。
注意事项(坑):
- 脏读问题:二级缓存是基于
Namespace的。如果多个Namespace操作同一张表,一个Namespace的更新操作只会清空自己的缓存,而不会清空其他Namespace的缓存,这可能导致脏读。- 解决方案:使用
<cache-ref>标签,让多个Namespace共享同一个缓存配置和实例。
xml<!-- 在 OrderMapper.xml 中 --> <cache-ref namespace="com.example.mapper.UserMapper"/> - 解决方案:使用
- 分布式环境下的数据不一致:MyBatis自带的二级缓存是基于JVM本地内存的。在分布式或集群环境下,每个应用节点都有自己的二级缓存,一个节点的更新无法通知其他节点,会导致数据不一致。
- 解决方案:集成第三方的分布式缓存框架,如Redis、Ehcache等。这需要自定义实现MyBatis的
Cache接口。社区已经有很多成熟的集成方案(如mybatis-redis)。
- 解决方案:集成第三方的分布式缓存框架,如Redis、Ehcache等。这需要自定义实现MyBatis的
- 配置复杂性:需要仔细规划哪些Mapper需要开启缓存,以及它们之间的依赖关系,避免因缓存刷新不及时导致的数据问题。
总结
MyBatis二级缓存是一个强大的性能优化工具,但它是一把双刃剑。正确理解其Namespace级别作用域、跨SqlSession共享的特性,以及事务提交/关闭时才生效的机制至关重要。在使用时,必须充分评估业务场景,特别是在复杂和分布式环境下,要警惕其可能带来的数据一致性问题。