 播面
播面 讲讲Flink-CDC无锁快照算法中“Binlog 剪枝(Binlog Pruning)”或者“去重逻辑”的具体执行过程。
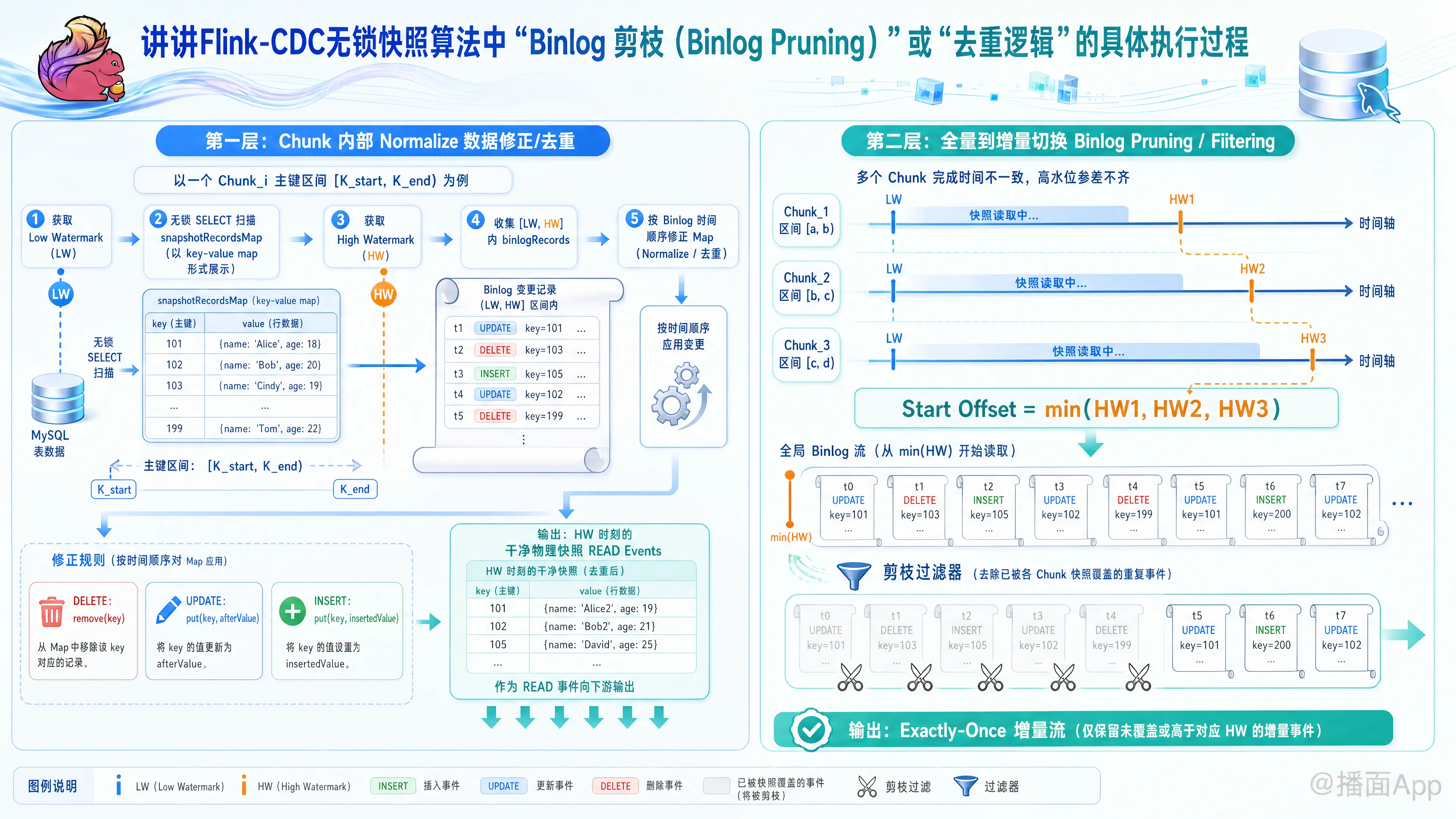
在 Flink CDC 的无锁算法中,为了在不锁表的前提下实现数据的“精确一次(Exactly-Once)”消费,框架设计了两层极其关键的去重与过滤机制。这两层机制通常被称为单 Chunk 内部的“数据修正/去重(Normalize)”,以及全量向增量切换时的“Binlog 剪枝/过滤(Binlog Pruning)”。
以下是这两个过程的底层具体执行步骤:
第一层:单 Chunk 内部的“数据修正与去重(Normalize)”
在全量快照阶段,多并发的 Reader 异步、无锁地读取各个主键区间(Chunk)的存量数据。由于在执行 SELECT 期间业务仍在不断写入,Reader 读取到的快照数据可能是“脏”的。此时需要利用该 Chunk 范围内的局部 Binlog 进行数据修正。
1. 水位线锚定与数据收集
对于任意一个分片 (主键区间 ),其执行步骤如下:
- 第一步:向数据库发起轻量级查询,获取当前的最新 Binlog 位点,记录为低水位线(Low Watermark, )。
- 第二步:执行普通的无锁
SELECT语句,扫描该主键区间内的所有物理记录,这些数据临时缓存在内存的snapshotRecordsMap中(以主键为 Key,整行数据为 Value)。 - 第三步:再次查询最新 Binlog 位点,记录为高水位线(High Watermark, )。
- 第四步:在此期间,后台线程会持续收集该 Chunk 主键区间内在 期间产生的所有 Binlog 变更记录(
binlogRecords)。
2. 内存中的数据修正算法(Deduplication & Normalize)
在收集齐上述数据后,Flink CDC 会调用内部的修正逻辑(如源码中的 RecordUtils#normalizedSplitRecords),对 snapshotRecordsMap 进行按时间顺序(Binlog 产生顺序)的对齐和去重:
- 遍历区间 内的所有
binlogRecords:- 遇到删除事件(DELETE):
提取该事件的主键,直接从内存的snapshotRecordsMap中执行remove(key)。这确保了在SELECT期间被物理删除的行,不会出现在最终输出中。 - 遇到更新事件(UPDATE):
提取该更新事件的最新值(After 镜像),在内存中执行put(key, updatedValue),覆盖掉之前SELECT读到的旧快照值。 - 遇到创建事件(INSERT):
执行put(key, insertedValue),将新行插入或覆盖到内存 Map 中。
- 遇到删除事件(DELETE):
- 合并输出:
在遍历完所有 之间的 Binlog 后,snapshotRecordsMap中留下的数据,就是该 Chunk 在 (高水位)这一精确时刻的干净物理快照。
最后,Flink CDC 将这些修正后的数据作为READ类型的事件,伴随着水位线标记一同发射给下游。
第二层:全量向增量切换时的“Binlog 剪枝与过滤(Binlog Pruning)”
当所有 Chunk 的全量快照阶段结束,任务需要收拢为单并发、持续消费全局 Binlog 的增量阶段。此时,由于各个 Chunk 读取完毕的时间不一致,它们的 位点也是参差不齐的。
1. 寻找最小起步位点(防止丢数据)
- 假设有 3 个 Chunk,各自对应的 分别为 、、。
- 增量阶段的
BinlogSplitReader在启动时,必须选择 作为读取全局 Binlog 的起始偏移量。 - 问题产生:如果从最老的 开始读,对于那些完成较晚、高水位线更新的 Chunk(例如 ),在 到 之间的 Binlog 变更已经在全量阶段被该 Chunk 的“第一层修正”合并过一次了。如果不加控制,这部分重合区间的数据就会被重复下发,造成数据重复。
2. 精准的 Binlog 剪枝(Pruning)执行流程
为了解决这一重叠区间的重复消费问题,Flink CDC 在增量阶段通过 Binlog 剪枝 将冗余数据在 Source 内部彻底过滤掉:
全局 Binlog 轴 ─────────────────────────────────────────────────────────>
│ (min(HW) 起步点)
▼
[ 已合并的 Binlog 区间 ] ───> 触发 Binlog 剪枝 (Discard)
│
├─────── 过滤逻辑:Offset <= HW_chunk ?
│
▼
[ 未合并的全新 Binlog ] ───> 允许下发 (Emit)
│ (HW_chunk 之后点)- 分片边界信息传递:
在全量阶段结束后,SplitEnumerator会将所有已完成的 Chunk 的主键物理区间和对应的高水位线 汇总,打包并保存在最新的MySqlBinlogSplit的元数据中,传递给增量阶段的BinlogSplitReader。 - 实时数据比对:
当增量 Reader 从 处开始消费全局 Binlog 遇到一条变更事件(Event)时:- 第一步:主键归属判断:读取该变更事件的主键,判断它落在哪一个已完成的 Chunk 主键区间内(例如,该 Key 属于 的范围)。
- 第二步:位点高度对比:获取该主键对应的 的高水位线 。
- 第三步:剪枝过滤(Binlog Pruning):
- 如果该 Binlog 事件的物理偏移量(Offset) 该 Chunk 的高水位线():
说明这个变更事件在全量阶段已经被第一层的内存修正算法吸收并下发过了。Flink CDC 直接将该 Binlog 事件抛弃(Pruned/Discarded)。 - 如果该 Binlog 事件的物理偏移量(Offset) 该 Chunk 的高水位线():
说明这是一个全新的变更。Flink CDC 放行该事件,并将其序列化下发给下游。
- 如果该 Binlog 事件的物理偏移量(Offset) 该 Chunk 的高水位线():
总结
Flink CDC 正是通过这套双层去重设计,在全量阶段利用 内存 Map 覆盖修正 实现了单 Chunk 内部的无锁一致性;并在全增量切换阶段,利用 Binlog 剪枝(通过主键区间匹配 Chunk 的 进行物理 Offset 过滤) 解决了重合区间的重复消费,最终在无任何数据库锁的前提下,保障了全链路 Exactly-Once 的极速流转。