 播面
播面 Flink CDC 底层是如何通过“基于 GTID 的心跳机制”来实现源端 Binlog 位点高可用与准确续传的[5]?
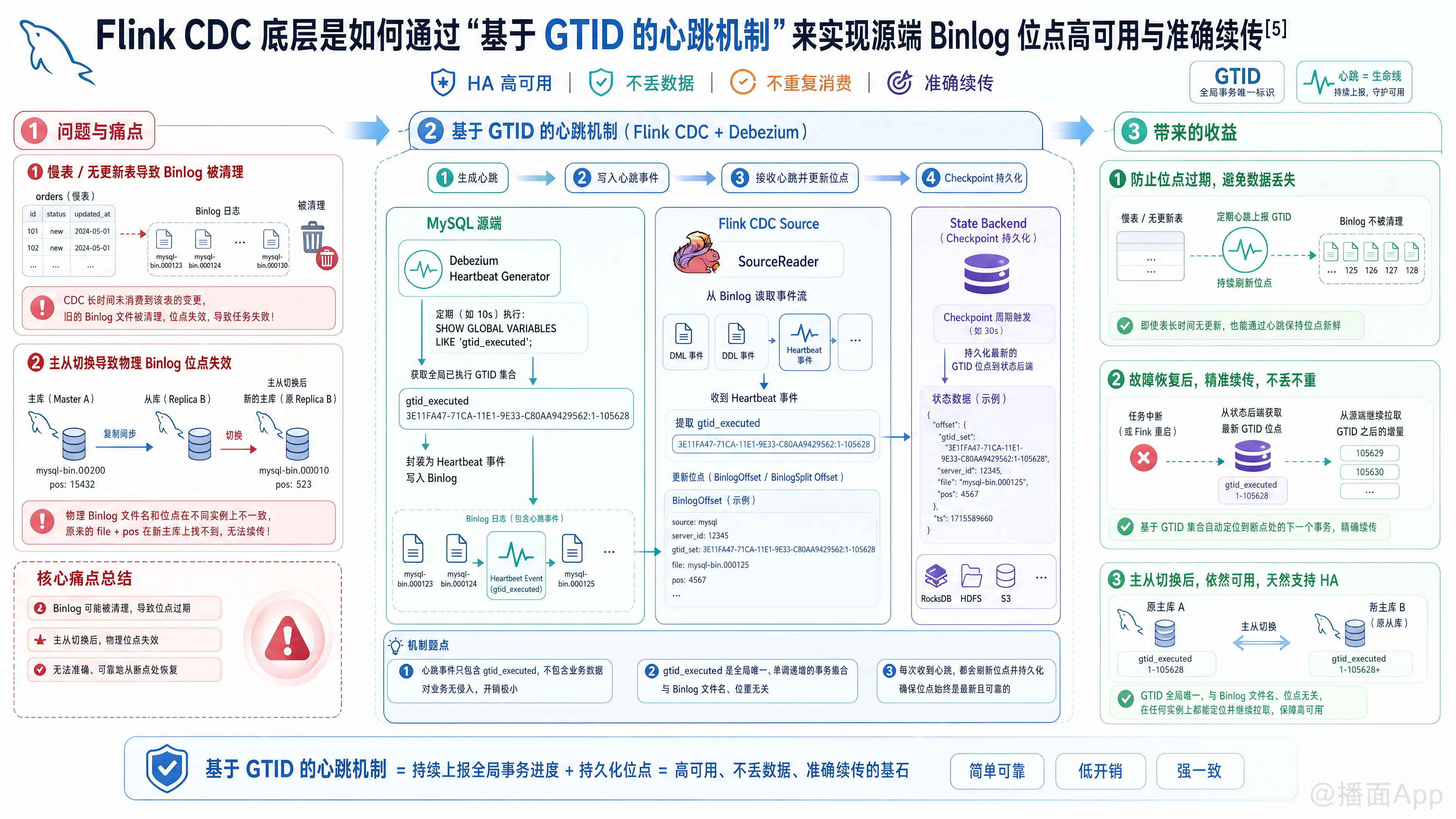
在 Flink CDC 中,“基于 GTID 的心跳机制”是保障增量数据同步在高可用(HA)场景下不丢不重、平滑容灾以及在慢表(更新频率低)场景下成功断点续传的一项底层核心技术。
要理解其底层逻辑,我们需要先分析它所解决的痛点,然后解构其工作机制和保障高可用及续传的原理。
一、 它解决什么痛点?
“慢表/无更新表”导致的位点过期(Binlog Purge):
在生产环境中,如果 Flink CDC 监控的某些表长时间没有数据更新(如配置表),MySQL 的 Binlog 就不会产生这些表的变更记录。但由于其他未监控表的频繁写入,MySQL 全局的 Binlog 文件仍会不断滚动并被系统定期清理(Purge)。- 后果:如果 Flink CDC 状态中保存的位点(GTID)一直停留在数天前慢表的最后一次更新位置,一旦任务重启,Flink 会尝试从该古老的 GTID 处开始读取。此时该位点对应的 Binlog 物理文件早已被 MySQL 清理,任务便会报“Binlog 已被清理”或“GTID 找不到”的异常,导致无法断点续传,只能进行代价高昂的无状态重建。
主从切换(HA)后物理位点失效:
如果仅依靠传统的Binlog文件名 + Position寻址,当 MySQL 发生主备切换时,新主库的 Binlog 文件名和物理偏移量往往与旧库完全不一致,导致 Flink CDC 无法直接迁移续传。
二、 底层心跳机制的设计与工作原理
为了解决上述问题,Flink CDC(底层依赖 Debezium)引入了基于 GTID(全局事务标识符)的心跳机制。
1. 心跳事件的周期性生成
Flink CDC 启动后,在增量读取阶段,内部的心跳发射器(Heartbeat Generator)会按照用户配置的间隔(默认 30 秒,由 heartbeat.interval 控制)定期在后台生成虚拟的心跳事件(Heartbeat Event)。
2. 实时捕获全局最新 GTID 集合
当心跳事件触发时,即便被监控的物理表没有发生任何 INSERT/UPDATE,心跳线程也会通过当前的复制连接向 MySQL 发送轻量级请求,查询当前 MySQL 实例全局最新已执行的 GTID 集合(即 gtid_executed 变量值)。
3. 内存位点推进与 Flink 状态更新
- Flink CDC 的
SourceReader接收到这个心跳事件后,会将该事件携带的最新的全局 GTID 集合提取出来,直接更新内存中维护的BinlogSplit的偏移量(BinlogOffset)。 - 随后,在 Flink 下一次触发全局 Checkpoint 时,这个被心跳强行推高至最新位置的 GTID 集合状态,就会被持久化写入 Flink 的状态后端(State Backend)。
三、 它是如何保障“高可用”与“准确续传”的?
1. 规避位点过期,保障断点续传(解决慢表问题)
通过心跳机制,Flink 状态中保存的位点不再死板地停留在“被监控表最后一次更新的时间点”,而是实时向右对齐到 MySQL 全局最新提交的 GTID。
- 续传效果:当任务停止数天后重新拉起时,Flink CDC 从状态中取出的 GTID 位点是“当前数据库最新的 GTID”(该 GTID 对应的事务一定存在于最新的物理 Binlog 文件中,或者已被标记为完全执行完毕)。Flink 无需再去回溯已经被清理的历史 Binlog,从而保证了断点续传的 100% 成功率。
2. 无缝兼容主备切换,实现真正的高可用(HA)
GTID(Global Transaction Identifier)在整个 MySQL 复制集群中是全局唯一且幂等的,它不依赖于任何单台服务器上的物理文件名。
- 高可用效果:当主库 A 挂掉,从库 B 被提升为新主库时,新主库 B 依然拥有相同的已经执行完毕的 GTID 集合。
- Flink CDC 发生重连并连向新主库 B 时,会将 Checkpoint 中恢复出的、由心跳机制保持最新的 GTID 集合发送给新主库。新主库 B 会直接对比该 GTID 集合,准确过滤出 Flink 尚未消费的、仅在新主库上产生的最新事务,从而实现无缝跨实例续传,杜绝了主备切换期间的数据丢失或重复。