 播面
播面 讲讲Doris 的数据版本控制(Version)?
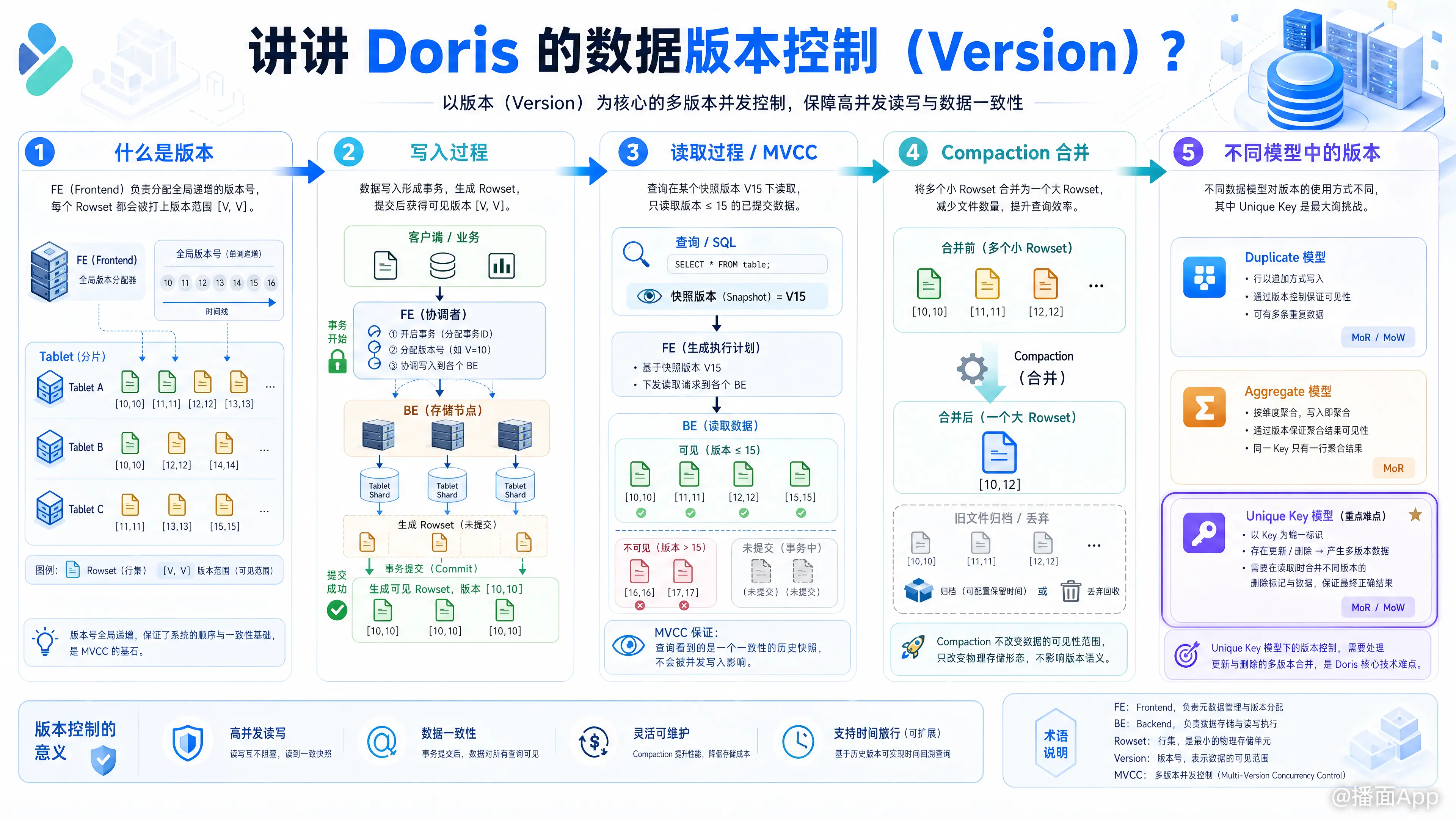
Apache Doris 的数据版本控制(Data Versioning)是其底层存储架构的核心机制之一。它不仅决定了数据如何写入和读取,还支撑了 Doris 的 MVCC(多版本并发控制)、事务的 ACID 特性以及高效的数据更新与合并(Compaction)。
下面为你详细拆解 Doris 的数据版本控制机制:
1. 什么是版本(Version)?
在 Doris 中,版本是对数据变更(导入、更新、删除)的逻辑抽象。
- 版本号生成:版本号是一个单调递增的整数。每次导入任务(Load/Insert)在提交时,Doris 的 FE(Frontend)节点都会为受影响的 Tablet(数据分片)分配一个递增的版本号。
- 版本与 Rowset 的对应关系:在 BE(Backend)存储节点上,每次成功的写入都会生成一个新的数据文件集合,称为 Rowset。每一个 Rowset 都会绑定一个版本范围,用
[start_version, end_version]表示。
2. 版本的生命周期(从写入到读取)
A. 写入过程(单行版本 [V, V])
- 用户发起一次导入任务(如 Flink 写入或 Stream Load)。
- FE 开启一个事务(Transaction)。
- BE 将数据写入本地磁盘,生成一个 Rowset。此时这个 Rowset 的版本是不确定的。
- 导入完成,FE 提交事务,并为该批次数据分配一个具体的可见版本号(假设为
V10)。 - BE 将该 Rowset 的版本标记为
[10, 10]。这代表这个文件只包含了版本 10 的数据。
B. 读取过程(MVCC 与可见性)
Doris 支持 MVCC(多版本并发控制),这意味着读写不互斥。
- 当用户发起查询时,FE 会确定当前该表/分区的最大连续可见版本号(假设为
V15)。 - FE 将查询请求和版本号
V15发送给 BE。 - BE 在读取数据时,只会读取版本号 的 Rowset。
- 如果此时后台有新的事务提交产生了
[16, 16],或者有未提交的事务,查询都会直接忽略它们。这保证了查询的快照隔离性(Snapshot Isolation)。
C. 合并过程(Compaction 与版本范围)
如果每次写入都产生一个 [V, V] 的小文件,查询时就需要扫描大量文件,性能会急剧下降。因此 Doris 会在后台进行 Compaction(数据压缩合并)。
- 假设当前有三个连续的 Rowset:
[10, 10]、[11, 11]、[12, 12]。 - 后台 Compaction 线程会将这三个 Rowset 读取出来,进行排序、合并(如果是聚合模型则进行预聚合),生成一个新的大的 Rowset。
- 这个新的 Rowset 的版本会被标记为
[10, 12]。 - 合并完成后,旧的三个单版本 Rowset 会被标记为废弃并在稍后被物理删除。
- 查询时的匹配逻辑:查询
V15时,BE 发现[10, 12]这个区间被完全包含在 15 以内,就会直接读取这个大文件。
3. 版本控制在不同数据模型中的表现
Doris 有三种主要的数据模型,版本机制在其中的作用略有不同:
① 明细模型 (Duplicate) 和 聚合模型 (Aggregate)
- 新版本的数据直接追加。
- 对于 Aggregate 模型,Compaction 过程中会将不同版本中具有相同 Key 的数据进行聚合计算(如 SUM、MAX),从而减少数据量。
② 唯一键模型 (Unique Key) —— 版本控制的核心难点
在 Unique Key 模型中,Doris 需要保证相同 Key 的数据只有最新的一条有效。Doris 提供了两种基于版本的实现方式:
- Merge-on-Read (MoR - 读时合并):
- 新老版本数据同时存在磁盘上(比如版本 10 有 Key_A,版本 15 也写入了 Key_A)。
- 查询时,BE 会把版本 10 和版本 15 的数据都读出来,在内存中比较版本号,只保留版本号最大的数据返回给用户。
- 特点:写入极快,但查询由于要合并大量历史版本,性能会有损耗。
- Merge-on-Write (MoW - 写时合并,Doris 1.2+ 默认):
- 为了加速查询,Doris 引入了 Delete Bitmap(删除位图)。
- 当写入新版本(如 V15)的 Key_A 时,系统会去查找 Key_A 以前在哪个版本(假设在 V10)。
- 系统会在 V15 对应的数据结构中,在 V10 的 Delete Bitmap 里把 Key_A 对应的行标记为“已删除”。
- 查询时,不需要在内存中动态比较版本了,直接根据 Delete Bitmap 过滤掉旧版本数据即可。
- 特点:牺牲了一点点写入性能(因为要查历史版本),换取了极致的查询性能。
4. 常见的版本相关问题与调优
在实际使用 Doris 时,开发者最常遇到的问题就是版本堆积(Too Many Versions)。
- 报错现象:写入失败,报错
errCode = 2, detailMessage = too many versions. tablet_id: xxx...(通常也被称为 -235 错误)。 - 根本原因:用户的写入频率过高(例如每秒用 Flink 写几十次,或者代码里用
INSERT INTO ... VALUES一条一条插),导致产生了大量[V, V]的小文件。后台的 Compaction 线程合并速度赶不上新版本的生成速度,为了保护系统不崩溃(打开过多文件句柄导致 OOM 或 IO 阻塞),Doris 强行拒绝了新的写入。 - 解决/调优方案:
- 降低写入频率,增大批次:这是最根本的解决办法。将 Flink 的 Sink 攒批时间(
sink.buffer-flush.interval)调整到 10 秒或更大。 - 调整 Compaction 参数:如果硬件资源充足,可以在 BE 配置(
be.conf)中增加 Compaction 的线程数,加快合并速度(如增加compaction_task_num_per_disk)。 - 合理设计表结构:避免单表的分区和分桶数量过多。因为版本是基于 Tablet(分片)维度的,分片越多,产生的小文件就呈现乘数级增长。
- 降低写入频率,增大批次:这是最根本的解决办法。将 Flink 的 Sink 攒批时间(
总结
Doris 的数据版本控制(Version)是一个将 写入事务、底层存储文件(Rowset)、后台合并(Compaction)和多版本并发控制(MVCC) 串联起来的核心枢纽。理解了 [start_version, end_version] 的概念,就能深刻理解 Doris 是如何实现高并发读取和高效数据更新的。