 播面
播面 PageHelper分页插件的原理
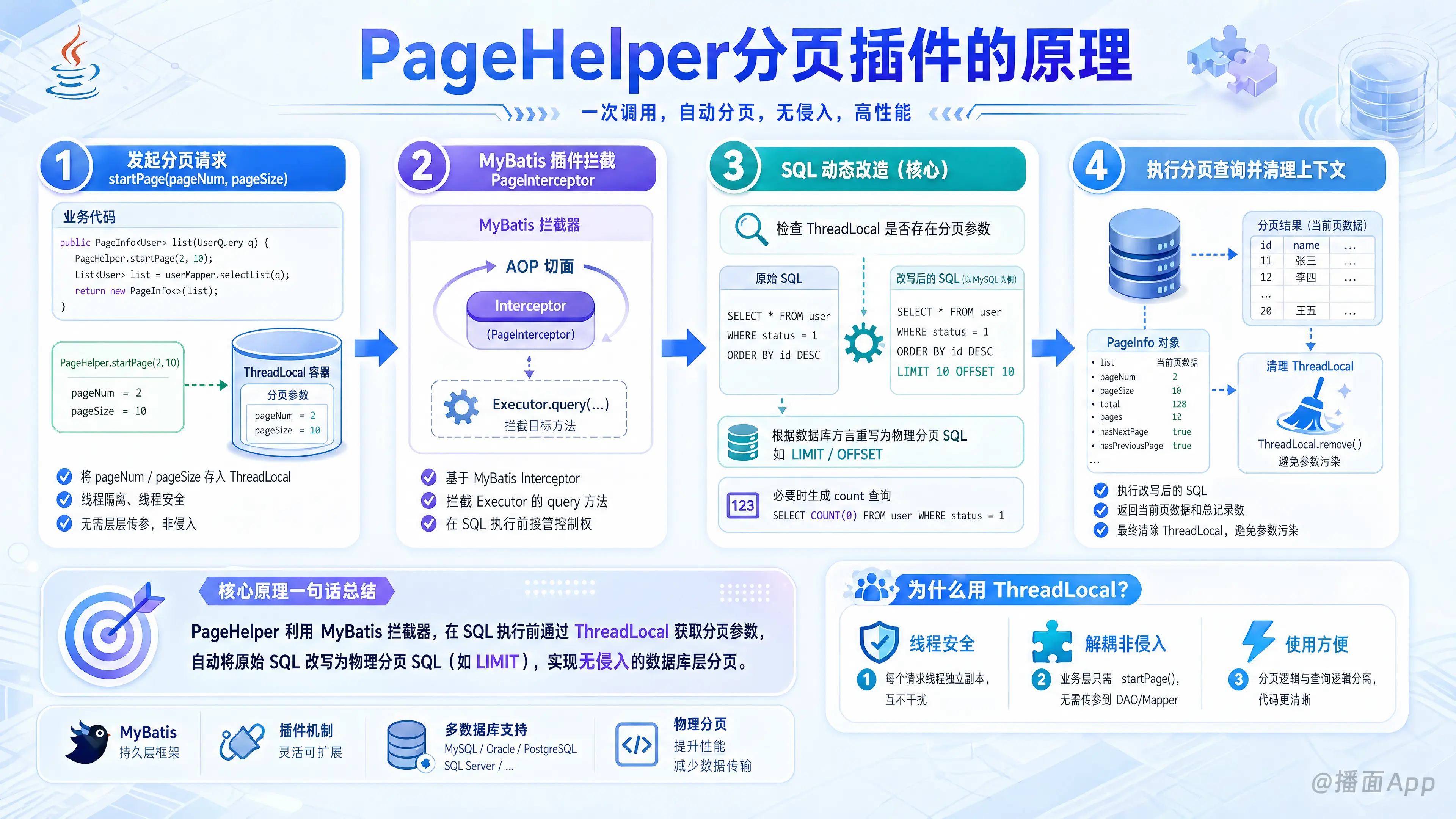
PageHelper利用MyBatis拦截器,在SQL执行前通过ThreadLocal获取分页参数,自动将原始SQL改写为物理分页SQL(如LIMIT),实现无侵入的数据库层分页。
我们来详细剖析一下 PageHelper 分页插件的原理。
一句话概括其核心原理就是:利用 MyBatis 提供的插件(Interceptor)接口,通过 AOP(面向切面编程)的思想,在 SQL 语句执行前进行拦截,动态地重写 SQL 语句,为其添加物理分页逻辑,从而实现数据库层面的分页查询。
下面我们分步拆解这个过程,让你彻底理解它的工作流程。
核心流程详解
整个分页过程可以分为以下几个关键步骤:
步骤一:发起分页请求 (PageHelper.startPage())
当我们在业务代码中调用 PageHelper.startPage(pageNum, pageSize) 时,PageHelper 并没有立即去做任何数据库操作。它做了一件非常重要的事情:
- 将分页参数(页码
pageNum和每页数量pageSize)存入一个ThreadLocal变量中。
为什么使用 ThreadLocal?ThreadLocal 是 Java 提供的一种线程级别的变量,每个线程都有自己独立的副本,互不干扰。这带来了两个巨大的好处:
- 线程安全:在多线程环境下(如 Web 服务器),每个用户的请求都是一个独立的线程。使用
ThreadLocal可以确保 A 线程的分页参数不会被 B 线程的分页参数覆盖。 - 代码解耦/非侵入性:我们只需要在执行 Mapper 查询前调用一次
startPage()即可,无需将分页参数(pageNum,pageSize)一路传递到 DAO/Mapper 层。这让我们的业务代码和分页逻辑完全分离,非常优雅。
步骤二:MyBatis 插件拦截 (PageInterceptor)
PageHelper 的核心是一个实现了 MyBatis Interceptor 接口的类,通常是 PageInterceptor。这个拦截器会配置在 MyBatis 的配置文件中,告诉 MyBatis:“请在执行某些特定操作时,先通知我。”
PageHelper 主要拦截的是 MyBatis 核心组件 Executor 的 query 方法。Executor 是 MyBatis 中负责执行 SQL 语句的真正执行者。
// PageInterceptor 上的注解,声明了要拦截的目标和方法
@Intercepts({
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class, RowBounds.class, ResultHandler.class})
})
public class PageInterceptor implements Interceptor {
// ...
}当我们的业务代码调用 Mapper 接口的方法时(例如 userMapper.selectAll()),MyBatis 最终会调用 Executor 的 query 方法。此时,PageInterceptor 的 intercept 方法就会被触发,控制权暂时交给了 PageHelper。
步骤三:SQL 的动态改造(核心)
在 intercept 方法内部,PageHelper 开始执行真正的分页逻辑:
检查
ThreadLocal:首先,它会检查当前线程的ThreadLocal中是否存在分页参数。- 如果不存在:说明这个查询不需要分页,直接放行,执行原始的 SQL,不做任何处理。
- 如果存在:说明需要分页,开始执行下面的步骤。
获取原始 SQL:从
MappedStatement对象中获取到开发者在 XML 文件中写的原始 SQL 语句(例如SELECT * FROM user WHERE status = 1)。生成 Count 查询 SQL:PageHelper 会智能地将原始的查询 SQL 转换为一条计算总记录数的
COUNT(*)SQL。例如,将SELECT * FROM user WHERE status = 1 ORDER BY create_time转换为SELECT COUNT(*) FROM user WHERE status = 1。然后执行这条 count SQL,获取总记录数total。生成物理分页 SQL:这是最关键的一步。PageHelper 会根据配置的数据库“方言”(Dialect),将原始 SQL 拼接成对应数据库的物理分页 SQL。
- MySQL:
SELECT * FROM user WHERE status = 1 LIMIT ?, ? - Oracle:
SELECT * FROM ( SELECT tmp_page.*, ROWNUM rn FROM ( 原SQL ) tmp_page WHERE ROWNUM <= ? ) WHERE rn > ? - PostgreSQL:
SELECT * FROM user WHERE status = 1 OFFSET ? LIMIT ? - ...等等
- MySQL:
替换原始 SQL 并执行:PageHelper 将改造后的物理分页 SQL 替换掉原始的 SQL,然后让 MyBatis 继续执行。这时,数据库收到的已经是带有分页功能的 SQL 了,所以它只会查询并返回那一页的数据(例如 10 条),而不是全部数据。这大大提升了性能。
步骤四:结果封装 (Page 对象)
MyBatis 执行完被改造后的分页 SQL 后,会返回一个结果集 List<E>。PageHelper 的拦截器会拿到这个结果集。
但它返回给调用者的并不是一个简单的 List。它会创建一个自定义的 Page<E> 对象(这个类本身继承自 ArrayList,所以它本质上还是一个 List),然后:
- 将查询到的当页数据放入
Page对象中。 - 将之前查询到的总记录数
total也设置到Page对象中。 - 同时,
Page对象内部还会根据total、pageNum、pageSize计算出总页数pages、当前页码pageNum等其它分页相关的信息。
所以,Mapper 方法的最终返回值虽然在签名上是 List<User>,但实际运行时它的类型是 Page<User>,这个对象包含了分页的所有信息。
步骤五:清理 ThreadLocal
在 intercept 方法的 finally 块中,PageHelper 会调用 PageHelper.clearPage() 方法,清空 ThreadLocal 中的分页参数。
为什么要清理?
因为 ThreadLocal 的生命周期与线程相同。如果不清理,当这个线程被线程池复用去执行下一个查询时,上一次的分页参数还在,就会导致下一个无关的查询也被错误地分页了。这是一个非常重要的安全措施。
流程总结图
业务代码 PageHelper 内部 MyBatis 核心 数据库
| | | |
1. PageHelper.startPage(1, 10) ---> 将分页参数(1, 10)存入 ThreadLocal
| |
2. userMapper.selectAll()
| |
+--------------------------------------------> | |
| |
3. PageInterceptor 拦截 Executor.query()
|
4. 从 ThreadLocal 获取分页参数
|
5. 生成并执行 Count SQL ---------------------------------------------------------------------------> SELECT COUNT(*) FROM user
| | |
|<----------------------------------------------------------------------------------------- 返回 total=105
|
6. 根据 "方言" 改造原始 SQL
(SELECT * FROM user -> SELECT * FROM user LIMIT 0, 10)
|
7. 用新 SQL 执行查询 -----------------------------> Executor.query(新SQL) ------------------> SELECT * FROM user LIMIT 0, 10
| |
|<------------------------------------------ 返回 10 条记录 (List<User>)
|<-----------------------------------------------
|
8. 将 List<User> 和 total 封装成 Page<User> 对象
|
9. 在 finally 块中清理 ThreadLocal
|
|<--------------------------------------------+
10. 得到 Page<User> 对象
(内含10条数据和分页信息)为什么通常使用 PageInfo?
虽然 Mapper 返回的是 Page 对象,但我们通常会用 PageInfo 再包装一层:PageInfo<User> pageInfo = new PageInfo<>(userList);。
Page对象:是分页查询结果的核心,它继承了List,主要存储数据和核心分页参数。PageInfo对象:是一个为视图层(前端)展示而设计的 DTO (Data Transfer Object)。它从Page对象中提取信息,并提供了更丰富、更易于使用的属性,如isFirstPage,isLastPage,hasNextPage,hasPreviousPage,navigatepageNums(导航页码数组,如[1, 2, 3, 4, 5]) 等。这使得前端在渲染分页导航条时非常方便。
这就是 PageHelper 从调用到返回结果的完整工作原理。它通过一种非常巧妙且对业务代码零侵入的方式,实现了强大的物理分页功能。