 播面
播面 遇到 HBase 读性能突然下降,或者某个 RegionServer 负载极高时,应当如何排查原因?
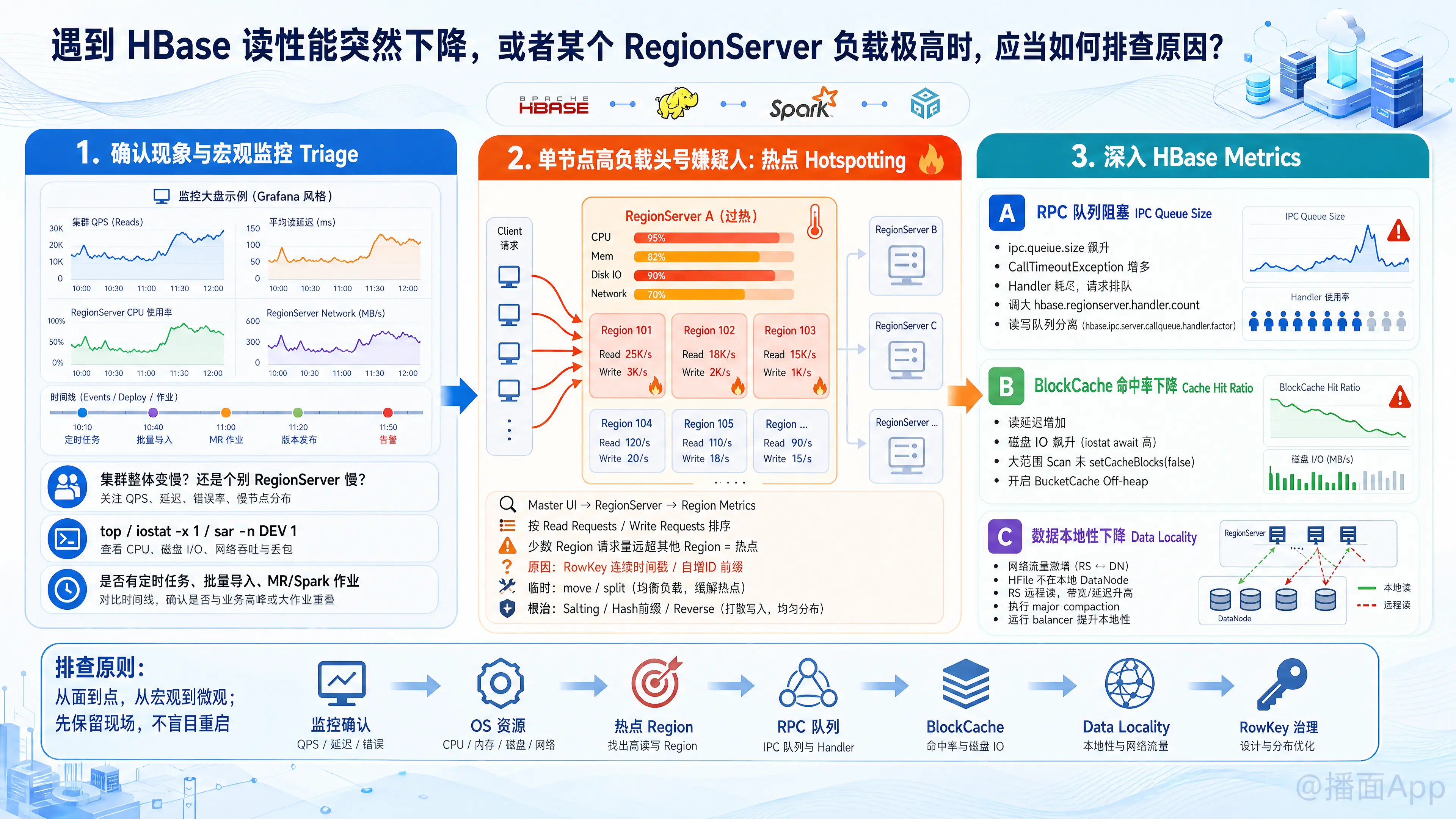
遇到 HBase 读性能突然下降,或者某个 RegionServer (RS) 负载极高时,通常意味着系统出现了资源瓶颈、数据倾斜(热点)或者不合理的客户端请求。
排查这类问题需要遵循“从面到点、从宏观到微观”的原则。以下是标准排查步骤和常见原因分析:
第一步:确认现象与宏观监控把控 (Triage)
首先不要盲目重启,先保留现场并查看监控大盘(Grafana / Cloudera Manager / HBase Master UI):
- 确认范围:是整个集群读变慢,还是只有个别 RegionServer 慢?
- OS 资源检查:登录问题 RS 节点,检查 CPU (
top)、磁盘 I/O (iostat -x 1)、网络 (sar -n DEV 1) 和内存使用情况。 - 关键时间点:性能下降是什么时候开始的?当时是否有定时任务启动(如大批量导入、离线 MR/Spark 任务)?
第二步:排查单节点高负载的“头号嫌疑人” —— 热点 (Hotspotting)
如果只有某一个 RegionServer 负载极高,90% 的概率是发生了数据热点。
- 排查方法:
- 打开 HBase Master UI,点击进入该高负载的 RegionServer 页面。
- 查看 Region Metrics 列表,按
Read Requests(读请求数)或Write Requests(写请求数)排序。 - 如果发现某一个或少数几个 Region 的请求量远超其他 Region,即确认是热点。
- 根本原因:
- RowKey 设计存在缺陷(例如:使用连续时间戳或顺序自增 ID 作为前缀),导致大量并发请求全部打向同一个 Region。
- 临时解决:通过 HBase Shell 强制将该热点 Region
move到其他空闲节点,或者手动split该 Region。 - 彻底解决:重新设计 RowKey(加盐 Salting、哈希 Hash 前缀、反转 Reverse)。
第三步:深入 HBase 内部指标排查 (HBase Metrics)
如果排除了单点热点问题,或者集群整体变慢,需要排查以下 HBase 核心机制:
1. RPC 队列阻塞 (IPC Queue Size)
- 现象:
ipc.queue.size飙升,客户端出现大量的CallTimeoutException。 - 原因:RegionServer 的处理线程(Handler)被耗尽。可能是因为个别慢查询(Bad Query)占用了所有线程,导致正常查询排队。
- 对策:检查
hbase.regionserver.handler.count(默认 30 通常偏小,高并发读可调大至 100-200)。分离读写队列(配置hbase.ipc.server.callqueue.handler.factor等参数)。
2. BlockCache 命中率下降 (Cache Hit Ratio)
- 现象:读延迟增加,磁盘 I/O 飙升。HBase UI 中 BlockCache 命中率急剧下降。
- 原因:
- 某个业务进行了超大范围的 Scan 操作(且未设置
setCacheBlocks(false)),导致缓存被迅速刷出(Cache Churn)。 - BlockCache 容量设置过小。
- 某个业务进行了超大范围的 Scan 操作(且未设置
- 对策:找出恶意 Scan 的客户端并限制;如果是大内存机器,建议开启 BucketCache (Off-heap) 减少 GC 压力并增大缓存。
3. 数据本地性下降 (Data Locality)
- 现象:RegionServer 负载高,网络流入流出流量激增,读请求变慢。
- 原因:HFile 不在本地 DataNode 上,RS 需要通过网络跨节点读取数据。通常发生在刚做完 Region 负载均衡(Balancer)或节点宕机恢复后。
- 对策:执行 Major Compaction 可以将数据重新本地化,但这需要在低峰期进行。
4. 合并风暴 (Compaction Storm)
- 现象:磁盘 I/O 长时间 100%,CPU iowait 极高,
compactionQueueLength监控指标飙升。 - 原因:集群同时触发了大量 Major Compaction,或者 Minor Compaction 跟不上写入速度导致 StoreFile 过多(StoreFile 越多,读放大越严重,读性能越差)。
- 对策:关闭自动 Major Compaction(
hbase.hregion.majorcompaction设为 0),改用外部 Cron 脚本在深夜低峰期手动触发。
第四步:JVM 与底层 OS 排查
如果 HBase 层面的指标看不出明显异常,可能是底层环境出了问题:
1. Full GC 停顿 (Stop-The-World)
- 排查:查看 RegionServer 的 GC 日志,或者监控中的 JVM 停顿时间。如果发生长达数秒的 Full GC,所有读写请求都会被挂起。
- 原因:内存泄漏、BlockCache 碎片过多、或者一次性拉取过多数据导致老年代被撑爆。
- 对策:使用 G1GC 垃圾回收器;控制单次 Scan 的缓存大小(
setCaching);使用堆外内存(Off-heap BlockCache)。
2. CPU 热点线程分析
- 如果 CPU 极高,可以通过以下命令抓取真凶:
top -H -p <RegionServer_PID>找到占用 CPU 最高的线程 ID (TID)。- 将 TID 转换为 16 进制:
printf "%x\n" <TID>。 jstack <RegionServer_PID> | grep <16进制TID> -A 20。
- 这样可以明确看到 CPU 是在做 GC、还是在做过滤(Filter)、还是在网络序列化。
3. 硬件故障(坏盘/网络丢包)
- 检查
dmesg -T看看是否有磁盘坏道报错。 - 如果某个节点上的所有操作都很慢(包括 Hadoop HDFS 层面的读写),可能是遇到了坏盘或慢盘(Slow Disk),此时需要踢掉该节点。
第五步:审查客户端请求 (Client-Side Check)
很多时候,RS 负载高是由业务代码发起了不合理的请求导致的:
- 缺少 Bloom Filter:读请求如果是 Get 或点查,如果没有配置 Bloom Filter,会导致大量不必要的 HFile 扫描。检查表结构,确保
BLOOMFILTER => 'ROW'或'ROWCOL'。 - 超级全表扫描:客户端发起了全表 Scan,且没有设置 StartRow 和 StopRow,同时还使用了复杂的 Filter。Filter 是在 RegionServer 端计算的,会极大地消耗 RS 的 CPU。
- 单行数据过大:存在几十 MB 甚至上 GB 的单个 Cell(例如存了图片或视频),读取时瞬间打爆网络和内存。
总结排查思路图(Checklist)
- 查热点:UI 看 Region 读写数 -> 若集中在某一点 -> 解决 RowKey 设计。
- 查线程/队列:看 IPC Queue 大小 -> 若爆满 -> 查慢查询、增大 Handler数。
- 查缓存/I/O:看 BlockCache 命中率与 I/O -> 若命中率低/IO高 -> 查大 Scan 破坏缓存、检查数据本地性。
- 查文件:看 StoreFile 数量 -> 若极多 -> 读放大严重 -> 需执行 Compaction。
- 查 JVM:看 GC 日志 -> 若有长时间 STW -> 调优 JVM、查大内存占用查询。