 播面
播面 讲讲HBase 客户端的连接复用(Connection)和线程安全机制,为什么不建议频繁创建 Connection?
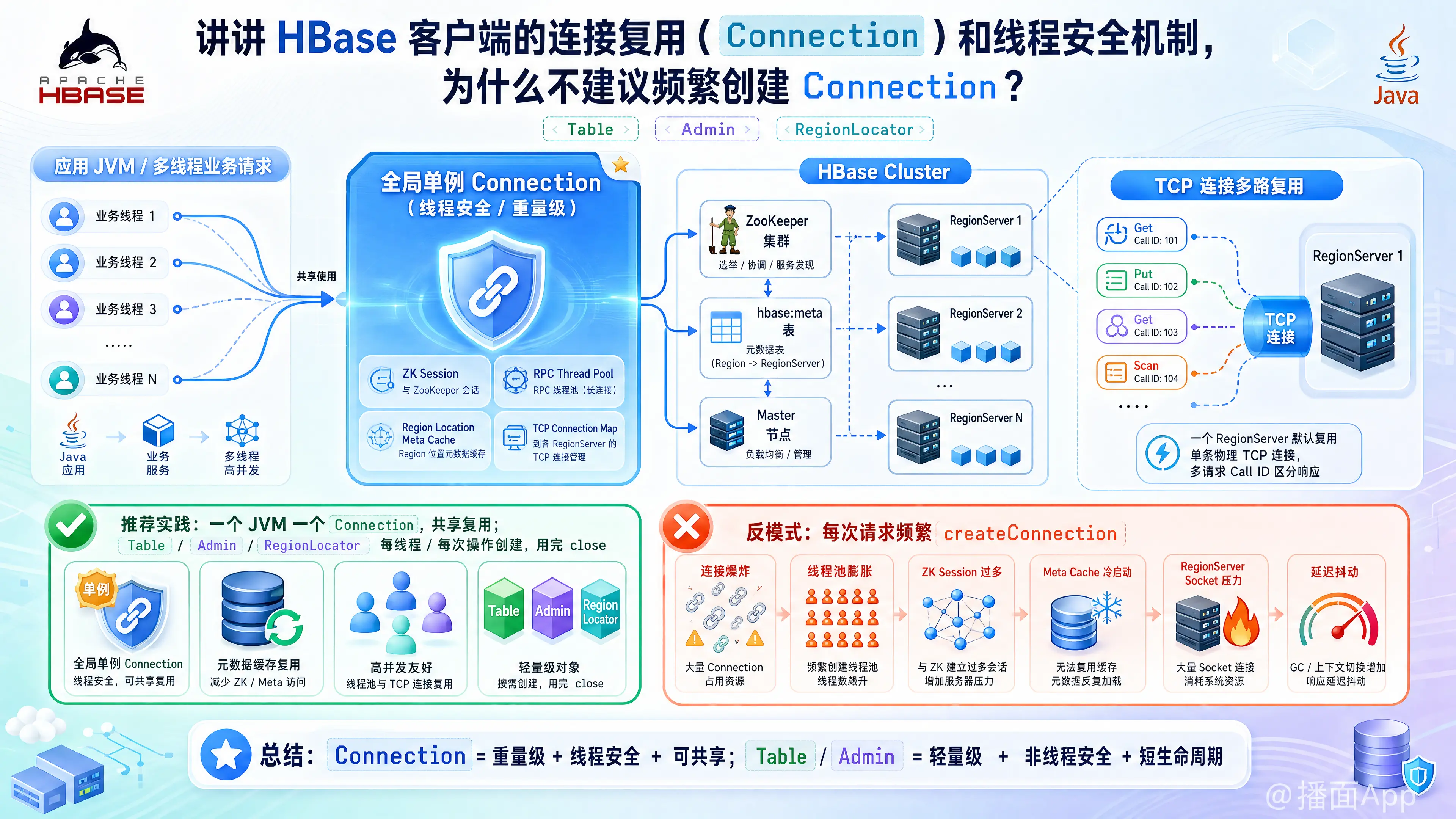
在 HBase(特别是 1.0.0 版本及以后)的 Java API 中,Connection 的设计理念与传统的关系型数据库(如 JDBC)有很大不同。
理解 HBase 的 连接复用机制 和 线程安全模型,是开发高性能、高稳定性 HBase 应用的关键。
以下是详细的原理解析以及为什么绝对不建议频繁创建 Connection。
一、 HBase 客户端的线程安全机制
HBase API 明确划分了“重量级/线程安全”和“轻量级/非线程安全”的对象。
1. Connection(重量级,线程安全)
- 定位:
Connection代表了客户端与整个 HBase 集群的连接。它不仅包含了网络连接,还封装了集群的元数据缓存、Zookeeper 连接和处理 RPC 调用的线程池。 - 线程安全性:绝对线程安全。它被设计为在多个线程之间共享。在一个 JVM 进程中,针对同一个 HBase 集群,通常只需要一个全局的
Connection实例(单例模式)。
2. Table / Admin / RegionLocator(轻量级,非线程安全)
- 定位:这些对象是执行具体操作(增删改查、DDL、路由查找)的句柄(Handle)。
- 线程安全性:非线程安全。它们被设计为每个线程或每次操作单独创建,用完即毁。
- 获取方式:通过
Connection.getTable(TableName)等方法获取。因为它们非常轻量级,获取的开销极低。
二、 HBase 的连接复用机制 (Connection Reuse)
HBase 客户端底层的连接复用机制主要体现在两个层面:TCP 连接多路复用 和 元数据缓存复用。
1. RPC 层面的 TCP 连接多路复用 (Multiplexing)
很多开发者误以为一个 Connection 对象对应一个底层 TCP 连接。实际上,Connection 内部维护了一个连接池(或连接映射表)。
- 当多个线程通过同一个
Connection访问同一个 RegionServer 时,HBase 客户端在底层默认只会建立一个物理 TCP 连接。 - 所有的并发请求(Get, Put 等)都会在这个单一的 TCP 连接上进行多路复用(类似 HTTP/2 的机制),通过请求 ID(Call ID)来区分不同的 RPC 响应。
- 这种设计极大地节省了 RegionServer 的 Socket 资源,避免了“线程爆炸”或“连接爆炸”。
2. 元数据缓存复用 (Meta Cache)
- HBase 读写数据前,需要知道数据分布在哪个 RegionServer 上(即
hbase:meta表的信息)。 Connection内部维护了一份 Region Location 缓存。- 所有共享此
Connection的线程都可以复用这份缓存,避免了每次读写都去请求 Zookeeper 和 Meta 表。
三、 为什么不建议频繁创建 Connection?
将 Connection 放在方法内部频繁创建(例如每次 HTTP 请求来都 new 一个),是 HBase 开发中最经典的 反模式(Anti-Pattern)。这会导致灾难性的后果,原因如下:
1. 创建开销极大(Heavyweight)
调用 ConnectionFactory.createConnection(conf) 时,客户端在后台会做大量极其耗时的操作:
- 连接 Zookeeper:建立 ZK session,读取集群的 Master 地址和 Meta 表所在的 RegionServer。
- 创建线程池:为了处理异步任务、批量请求(Batch),会初始化多个内部线程池。
- 初始化对象:创建复杂的配置对象、RPC 调度器等。
- 如果频繁创建,会消耗大量的 CPU 和网络 I/O,导致你的业务延迟急剧飙升。
2. 缓存失效(冷启动效应)
- 新创建的
Connection,其内部的 Region 元数据缓存是空的。 - 这意味着它的第一次读写操作,必须先经历
Client -> ZK -> Meta Region -> Target Region的完整路由过程。频繁创建相当于让系统永远处于“冷启动”状态,完全丧失了 HBase 的高性能特性。
3. 资源泄漏与耗尽 (Resource Exhaustion)
- Socket 泄漏:每次创建
Connection都会与 ZK 和 RS 建立新的 TCP 连接,如果不及时或不正确地关闭,极易耗尽客户端和服务器端的句柄(Too many open files)。 - Zookeeper 压力骤增:频繁的 ZK 连接和断开会导致 Zookeeper 集群负载过高,甚至引发 HBase 集群的不稳定。
- OOM / GC 压力:
Connection内部包含大量对象和线程池,频繁创建和销毁会导致 JVM 频繁触发 Full GC,甚至内存溢出。
四、 最佳实践与代码示例
在 HBase 1.0+ 的标准实践中,应该遵循:Connection 全局单例,Table 线程局部(用完即关)。
正确的做法(单例 + Try-with-resources)
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import java.io.IOException;
public class HBaseClientUtil {
// 1. 全局唯一的 Connection
private static volatile Connection connection = null;
private HBaseClientUtil() {}
// 2. 懒汉式单例(双重检查锁)初始化 Connection
public static Connection getConnection() {
if (connection == null) {
synchronized (HBaseClientUtil.class) {
if (connection == null) {
try {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "zk1,zk2,zk3");
// 建立连接,整个 JVM 生命周期只执行一次
connection = ConnectionFactory.createConnection(conf);
} catch (IOException e) {
throw new RuntimeException("Failed to create HBase connection", e);
}
}
}
}
return connection;
}
// 3. 具体的业务方法
public void putData(String tableName, Put put) {
Connection conn = getConnection();
// 4. 使用 try-with-resources 自动关闭 Table
// 获取 Table 是轻量级的,不会建立真实的物理连接
try (Table table = conn.getTable(TableName.valueOf(tableName))) {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
// 注意:table.close() 会被自动调用。
// table.close() 只是释放这个 Table 实例占用的本地内存/Buffer,
// 绝对不会关闭底层的 TCP 连接,也不会关闭 Connection。
}
}总结
- 把 HBase 的
Connection想象成 Java 中的 线程池 (ThreadPoolExecutor) 或 JDBC 中的 连接池 (DataSource),而不是单个 JDBC 连接。你肯定不会在每次执行 SQL 时都去创建一个连接池。 Table和Admin才是供你在单次操作中挥霍的轻量级对象,但用完记得调用close()以清理内存缓冲区。