 播面
播面 为什么在海量数据导入时推荐使用 Bulk Load?
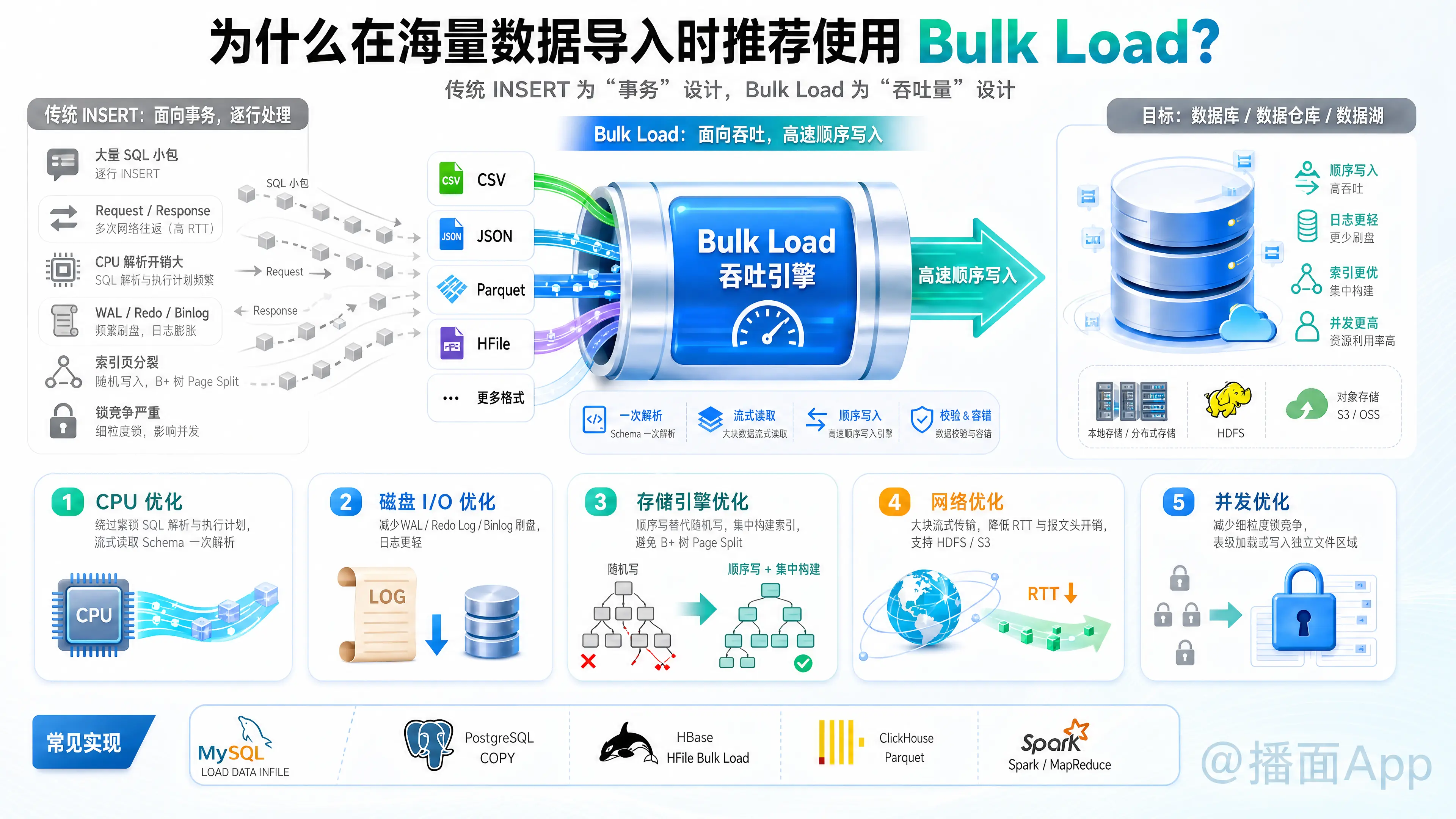
在海量数据导入的场景下,推荐使用 Bulk Load(批量/底层数据加载) 而不是传统的单条或小批量 INSERT,根本原因在于 性能上的巨大差异。Bulk Load 的速度通常是传统 INSERT 的十倍甚至上百倍。
这其中的核心逻辑是:传统 INSERT 是为“事务”设计的,而 Bulk Load 是为“吞吐量”设计的。
以下是推荐使用 Bulk Load 的详细原因分析:
1. 绕过繁琐的 SQL 解析与执行引擎(CPU 优化)
- 传统 INSERT: 数据库需要对每一条
INSERT语句进行:词法分析 -> 语法分析 -> 语义检查(字段类型匹配等) -> 生成执行计划 -> 执行。这在海量数据下会消耗大量的 CPU 资源。 - Bulk Load: 通常直接提供 CSV、JSON 或特定二进制格式的文件,数据库只需解析一次元数据(Schema),然后直接以流式(Stream)读取和转换数据,极大地节省了 CPU 开销。
2. 大幅减少事务日志(WAL/Redo Log)的开销(磁盘 I/O 优化)
- 传统 INSERT: 为了保证 ACID 特性(特别是防崩溃恢复),每一条或每一批数据的插入,数据库都必须先写入预写日志(WAL、Redo Log、Binlog 等),然后再写入数据文件。这会产生大量同步的随机磁盘 I/O。
- Bulk Load: 许多数据库在 Bulk Load 模式下会禁用或极大地简化日志记录。例如,它可能会直接将数据写入磁盘生成底层数据文件,然后在最后只记录一条“文件已合并”的元数据日志。没有了密集的日志刷盘瓶颈,I/O 速度大幅提升。
3. 顺序写替代随机写,避免索引频繁分裂(存储引擎优化)
- 传统 INSERT: 插入数据时,数据库不仅要写数据,还要实时更新索引(如 B+ 树)。海量无序数据的插入会导致 B+ 树频繁发生页分裂(Page Split),产生大量的随机写和内存开销。
- Bulk Load:
- 在关系型数据库中,Bulk Load 通常会先将数据在内存中排序,或者先禁用索引,等数据全部顺序写入完成后,再重新集中构建索引。集中构建索引是顺序读写,比逐条更新快得多。
- 在 Big Data 系统(如 HBase、ClickHouse)中,Bulk Load 是在外部(如 Spark/MapReduce 计算集群)直接生成数据库底层认识的数据文件(如 HFile、Parquet),然后通过文件系统的
mv命令直接挂载到数据库中,完全没有任何写入放大。
4. 极大地减少网络通信开销(网络优化)
- 传统 INSERT: 如果是单条或小批量插入,客户端与服务端之间需要进行无数次的 Request 和 Response 交互。网络延迟(RTT)会不断累加,成为致命瓶颈。
- Bulk Load: 数据被打包成巨大的块,或者直接读取本地/分布式文件系统(如 HDFS、S3)上的大文件。网络通信是以大吞吐量的流传输进行的,网络报文的头部开销和往返延迟被降到最低。
5. 降低锁冲突(并发优化)
- 传统 INSERT: 在高并发写入时,为了维护数据一致性,数据库会频繁申请和释放行锁、页锁甚至表锁,导致大量的死锁检测和线程阻塞。
- Bulk Load: 通常会采用表级排他锁(加载时不允许其他写操作),或者直接写入全新的独立文件区域(类似 LSM-Tree 的 SSTable),完全避开了细粒度的锁竞争。
常见的 Bulk Load 实现案例
不同数据库对 Bulk Load 有不同的称呼和实现方式,但底层思想一致:
- MySQL: 使用
LOAD DATA INFILE,比INSERT快 20 倍以上。 - PostgreSQL: 使用
COPY命令。 - HBase (大数据代表): 传统的
putAPI 会导致 RegionServer 内存(MemStore)打满、触发频繁的 Minor Compaction。而 HBase 的 BulkLoad 机制是:用 Spark 直接生成底层 HFile 格式的文件,然后调用LoadIncrementalHFiles将文件直接“贴”到 HDFS 的相应目录中。这使得 HBase 导入百亿级数据只需几十分钟。 - Elasticsearch: 提供
_bulkAPI,减少网络请求,并在内部优化 Lucene 索引段的合并过程。 - 数据仓库 (如 Snowflake, ClickHouse): 极度依赖 Bulk Load 导入 Parquet/CSV 文件,而非标准 INSERT。
使用 Bulk Load 的注意事项(副作用)
虽然 Bulk Load 速度极快,但在使用时也需要注意它牺牲了部分特性:
- 触发器和约束失效: 为了追求极致速度,很多数据库的 Bulk Load 不会触发 Trigger(触发器),也可能跳过外键约束(Foreign Key)检查。
- 原子性风险: 如果导入过程中断,部分数据库可能无法回滚已经写入的数据,需要手动清理。
- 影响在线服务: Bulk Load 会长时间占用极高的 CPU 和磁盘 I/O 宽带,可能导致同时进行的查询(SELECT)响应变慢。通常建议在业务低峰期执行,或在备库执行。
总结:
在海量数据导入时,传统 INSERT 就像是用小推车一车一车地运沙子(每次都要过安检、盖章、排队),而 Bulk Load 就像是直接把载满沙子的整条货轮停靠在码头直接卸货。用吞吐量换取细粒度的控制,就是 Bulk Load 被强烈推荐的原因。