 播面
播面 在大批量写入 HBase数据前,为什么要对表进行“预分区(Pre-splitting)”?如何进行合理的预分区?
在大批量写入 HBase 数据前,进行预分区(Pre-splitting)是 HBase 性能调优中最核心、最基础的操作之一。
以下将详细解答“为什么需要预分区”以及“如何进行合理的预分区”。
一、 为什么要对表进行“预分区”?
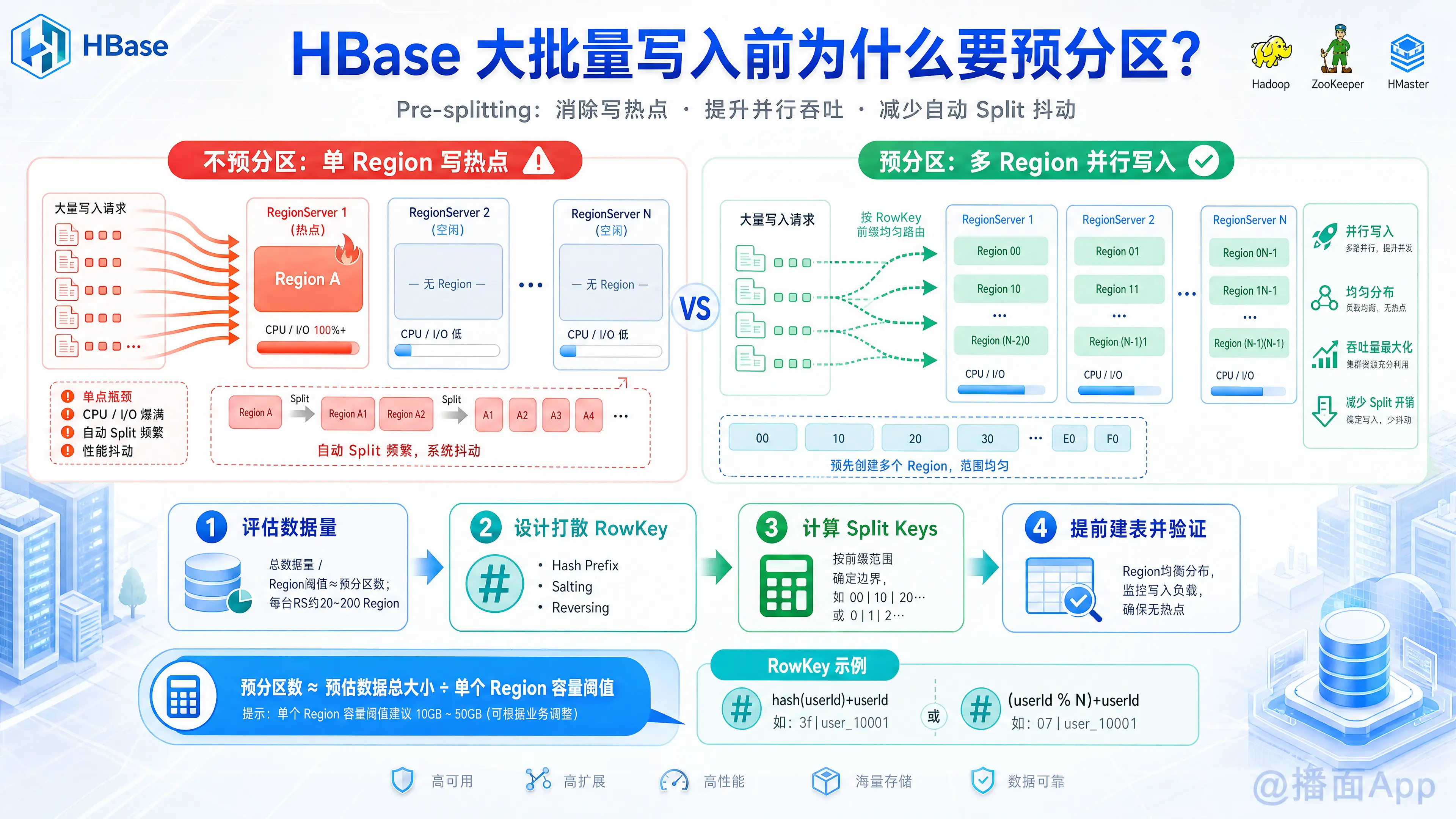
默认情况下,当你在 HBase 中创建一张新表时,这张表初始只有一个 Region。这个 Region 会被分配到集群中的某一台 RegionServer 上。如果在这种默认状态下大批量写入数据,会导致以下严重问题:
- 写热点(Write Hotspot)问题
因为初始只有一个 Region,所有的并发写入请求都会集中打到这唯一的一台 RegionServer 上。这会导致该节点的 CPU、内存、网络和磁盘 I/O 瞬间爆满,而集群中其他的 RegionServer 却处于空闲状态,集群的分布式计算和存储能力完全没有发挥出来。 - 频繁的自动 Split 导致性能抖动
随着数据不断写入,这个单一的 Region 体积会不断增大。当达到配置的阈值(如 10GB)时,HBase 会自动触发 Region Split(分裂),将 1 个 Region 拆分为 2 个。- 分裂过程需要消耗大量 I/O 和 CPU 资源。
- 分裂瞬间,该 Region 会短暂下线(不可写)。
- 在大批量写入时,这种“1变2、2变4、4变8”的自动分裂会极其频繁地发生,严重拖慢整体写入速度。
- Region 分布不均
依赖 HBase 自动分裂和负载均衡,需要花费较长的时间才能将分裂后的 Region 均匀调度到各个节点上。在数据完全打散之前,写入性能始终处于次优状态。
总结: 预分区就是提前将表划分为多个 Region,并均匀分配到集群的所有节点上。这样,数据一进入 HBase 就能被多台机器并行处理,彻底消除单点瓶颈,最大化写入吞吐量,并免去了自动分裂带来的额外开销。
二、 如何进行合理的预分区?
合理的预分区不是随便切分几块就行,它必须与RowKey 的设计紧密结合。如果 RowKey 是单调递增的(如时间戳),即使做了预分区,数据依然会集中写到最后一个 Region,预分区将毫无意义。
进行合理预分区的完整步骤如下:
1. 评估数据量与 Region 数量
- Region 数量不宜过多也不宜过少。
- 过少: 并发度不够。
- 过多: 会消耗大量 RegionServer 内存(每个 Region 都有 MemStore),且增加 ZooKeeper 和 HMaster 的管理负担。
- 经验公式:
预估数据总大小 / 单个 Region 容量阈值(默认 10GB) = 预分区数。 - 集群维度: 一般建议每个 RegionServer 上管理 20 ~ 200 个 Region 为宜。假设集群有 10 台机器,预分区数可以设置在 50 ~ 200 之间。
2. 设计打散的 RowKey(核心前提)
为了让数据均匀落入预先分好的 Region 中,RowKey 必须具备“随机性”或“均匀分布”的特性。常用的方法有:
- 哈希前缀(Hash Prefix): 对原始 RowKey 求 MD5 或 CRC32,取前几位作为 RowKey 前缀。(如
MD5(userid) + userid) - 加盐(Salting): 在 RowKey 前加上一个随机数或取模后的数字。(如
(userid % 100) + userid) - 反转(Reversing): 如果 RowKey 前面部分高度相似(如手机号
138xxxx),后面部分随机,可以将 RowKey 反转。(如手机号反转4321...831)
3. 确定 Split Keys(分区键边界)
根据你的 RowKey 设计,计算出分区的边界值。
案例 A:采用 16 进制 Hash 前缀
如果 RowKey 前缀是 0-9, a-f 的 16 进制字符,想要预分 16 个区,那么边界就是 1, 2, 3, ... , e, f。
- Region 1:
[ -∞ , 1 ) - Region 2:
[ 1 , 2 )
... - Region 16:
[ f , +∞ )
案例 B:采用 000-099 的数字加盐
想要预分 100 个区,边界就是 001, 002, 003, ... , 099。
4. 执行预分区(实施方法)
在确定了 Split Keys 之后,可以通过以下几种方式在建表时实施预分区:
方法一:HBase Shell 直接指定(适用于分区数较少)
# 创建表,列族为 info,指定 3 个边界,分为 4 个 Region
hbase> create 'my_table', 'info', SPLITS => ['10', '20', '30']方法二:HBase Shell 读取文件(适用于分区数较多,最常用)
- 创建一个文本文件
splits.txt,每一行写一个 Split Key:
01
02
03
...
99- 在 Shell 中执行建表命令:
hbase> create 'my_table', 'info', SPLITS_FILE => '/path/to/splits.txt'方法三:使用 HBase 内置算法(最简单,适用于 Hash 类型的 RowKey)
HBase 提供了内置的切分算法,如 HexStringSplit(16进制字符串切分)、DecimalStringSplit(10进制数字切分)和 UniformSplit(字节完全均匀切分)。
# 使用 16 进制切分算法,直接预分 16 个 Region
hbase> create 'my_table', 'info', {NUMREGIONS => 16, SPLITALGO => 'HexStringSplit'}方法四:Java API 代码实现
如果是通过 Java 代码自动建表,可以传入一个 byte[][] 类型的 splitKeys 数组:
Configuration conf = HBaseConfiguration.create();
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("my_table");
TableDescriptorBuilder tableDescriptorBuilder = TableDescriptorBuilder.newBuilder(tableName);
ColumnFamilyDescriptorBuilder cfBuilder = ColumnFamilyDescriptorBuilder.newBuilder(Bytes.toBytes("info"));
tableDescriptorBuilder.setColumnFamily(cfBuilder.build());
// 定义分区边界
byte[][] splitKeys = {
Bytes.toBytes("10"),
Bytes.toBytes("20"),
Bytes.toBytes("30")
};
// 建表并指定分区
admin.createTable(tableDescriptorBuilder.build(), splitKeys);总结
大批量写入 HBase 前,“好的 RowKey 设计 + 准确的预分区” 是解决写入性能问题的“黄金搭档”。预分区解决了集群资源调度的物理框架,而 RowKey 设计保证了数据能够均匀地流入这个框架中,两者缺一不可。