 播面
播面 什么是 Region 合并(Merge)?在什么场景下需要对 Region 进行手动合并?
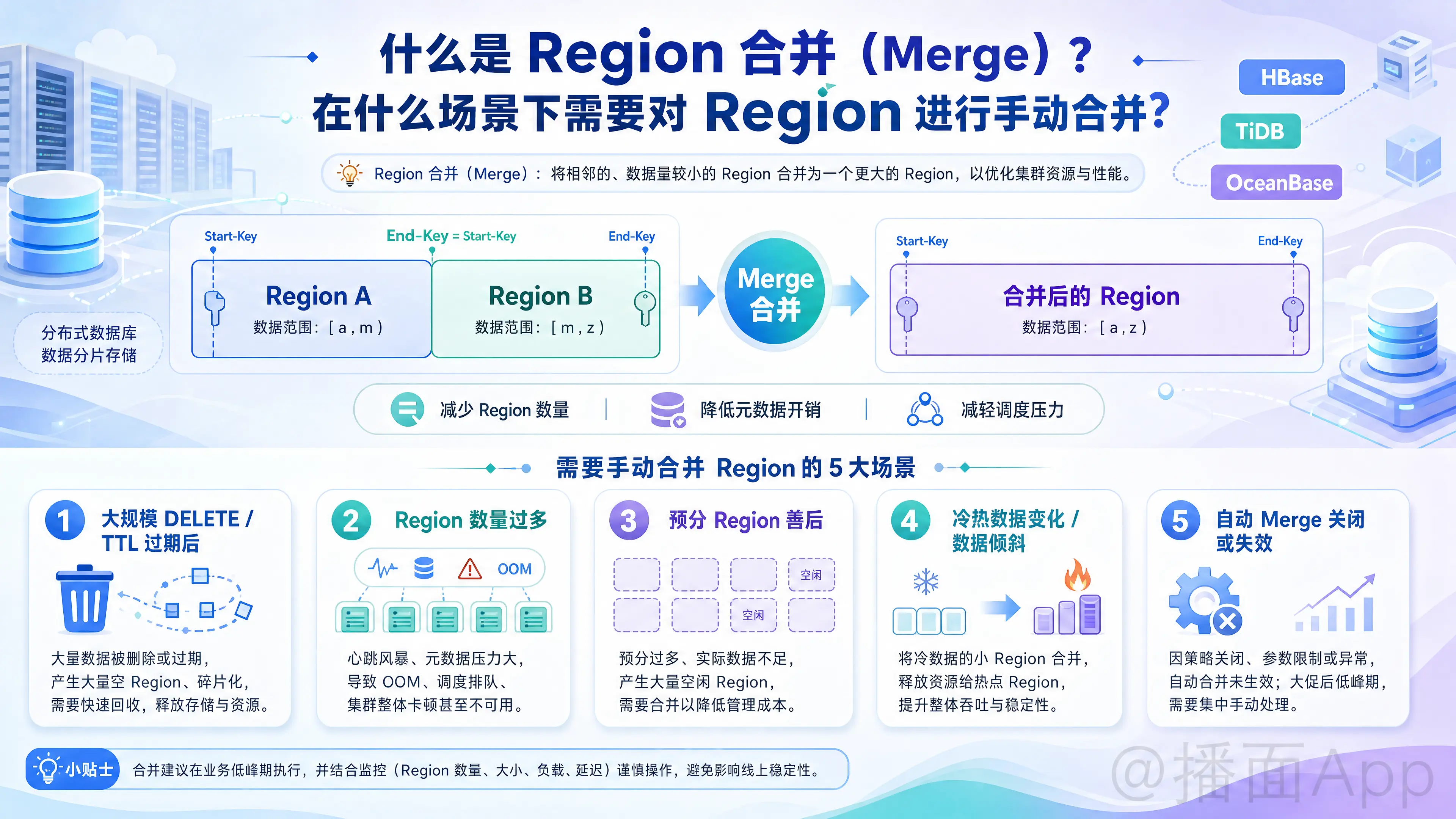
在分布式数据库(如 HBase、TiDB、OceanBase 等)中,Region 是数据分布、负载均衡和容灾的基本单位。它通常代表了一段连续的数据范围(通过 Start-Key 和 End-Key 界定)。
以下是关于 Region 合并(Merge) 以及 手动合并场景 的详细解析:
一、 什么是 Region 合并(Merge)?
Region 合并 是指将两个(或多个,通常是两个相邻的)较小的、数据量较少的 Region,合并成一个新的、较大的 Region 的过程。
- 工作原理:数据库系统会修改元数据,将两个相邻 Region 的边界(如 Region A 的 End-Key 和 Region B 的 Start-Key)打通,使其成为一个包含这两个数据范围的新 Region。底层的物理数据文件也会在后续的 Compaction(压缩/清理)过程中逐渐合并。
- 目的:与 Region 分裂(Split)相反,Region 合并的主要目的是减少系统中 Region 的总数量,降低系统的元数据管理开销和调度压力。
二、 在什么场景下需要对 Region 进行手动合并?
现代分布式数据库通常都具备自动 Region 合并的功能(当 Region 的大小或 Key 的数量低于某个阈值时自动触发)。但在以下特定场景下,DBA(数据库管理员)或开发者需要介入,进行手动 Region 合并:
1. 大规模数据删除后(数据清理/TTL过期)
- 场景描述:当执行了大量的
DELETE操作,或者大量数据因为 TTL(Time To Live)过期被清理后,原本填满的 Region 会变得非常空旷(称为“碎片化”或“空 Region”)。 - 为何手动:虽然系统有自动合并机制,但如果空 Region 数量极其巨大,自动合并的速度可能跟不上,或者为了防止影响线上业务,自动合并的速率被限制得极低。手动合并可以快速回收这些空 Region,降低集群压力。
2. Region 数量过多导致集群元数据压力过大(集群卡顿)
- 场景描述:由于长期的运行或不合理的分裂,集群中积累了海量的 Region(例如 HBase 中的 RegionServer 管理了成千上万个 Region,或者 TiDB 的 PD 节点需要处理海量 Region 的心跳)。
- 为何手动:每个 Region 都会产生心跳汇报、占用内存、消耗调度资源。当 Region 数量超过集群的承受能力时,会导致节点 OOM(内存溢出)、心跳风暴或元数据节点(如 PD/HMaster)响应迟缓。此时需要通过脚本或命令批量手动合并小 Region 以“抢救”集群性能。
3. 不合理的“预分 Region(Pre-splitting)”善后
- 场景描述:在建表初期,为了应对预期的高并发写入,DBA 可能会对表进行激进的预分 Region 操作(例如建表时直接切分出 1000 个 Region)。
- 为何手动:如果业务上线后,实际写入的数据量远未达到预期,或者某些数据段根本没有数据写入,就会留下大量长期空闲的 Region。为了避免浪费资源,需要手动将这些没用上的 Region 合并掉。
4. 解决特定分布的“数据倾斜”
- 场景描述:随着业务演进,某些旧数据区间的访问量和数据量急剧下降,而新数据区间的访问量极大。
- 为何手动:为了让节点能够腾出更多的 CPU 和内存去处理热点数据,需要把冷数据区间的多个小 Region 强制合并,从而释放调度资源,优化整体的负载均衡。
5. 自动合并机制失效或被故意关闭时
- 场景描述:在某些高频读写的大促期间,为了极致的性能,DBA 可能会主动关闭自动 Merge 和 Split 功能,以防止底层 I/O 抖动。
- 为何手动:大促结束后,系统积累了大量不合理的 Region,此时 DBA 会在业务低峰期通过手动触发的方式,集中处理这些需要合并的 Region。此外,如果遇到自动合并的 Bug 导致合并卡死,也需要人工介入清理状态并手动合并。
💡 补充提示:手动合并的注意事项
- 必须相邻:通常情况下,只有在逻辑范围上相邻的两个 Region 才能被合并。
- 资源消耗:Region 合并(尤其是底层数据文件的重写)会消耗大量的 CPU、内存和磁盘 I/O。因此,手动合并应当在业务低峰期进行,并控制并发度,以免造成线上业务延迟。