 播面
播面 讲讲 HBase 的HLog 的滚动(Roll)和失效机制
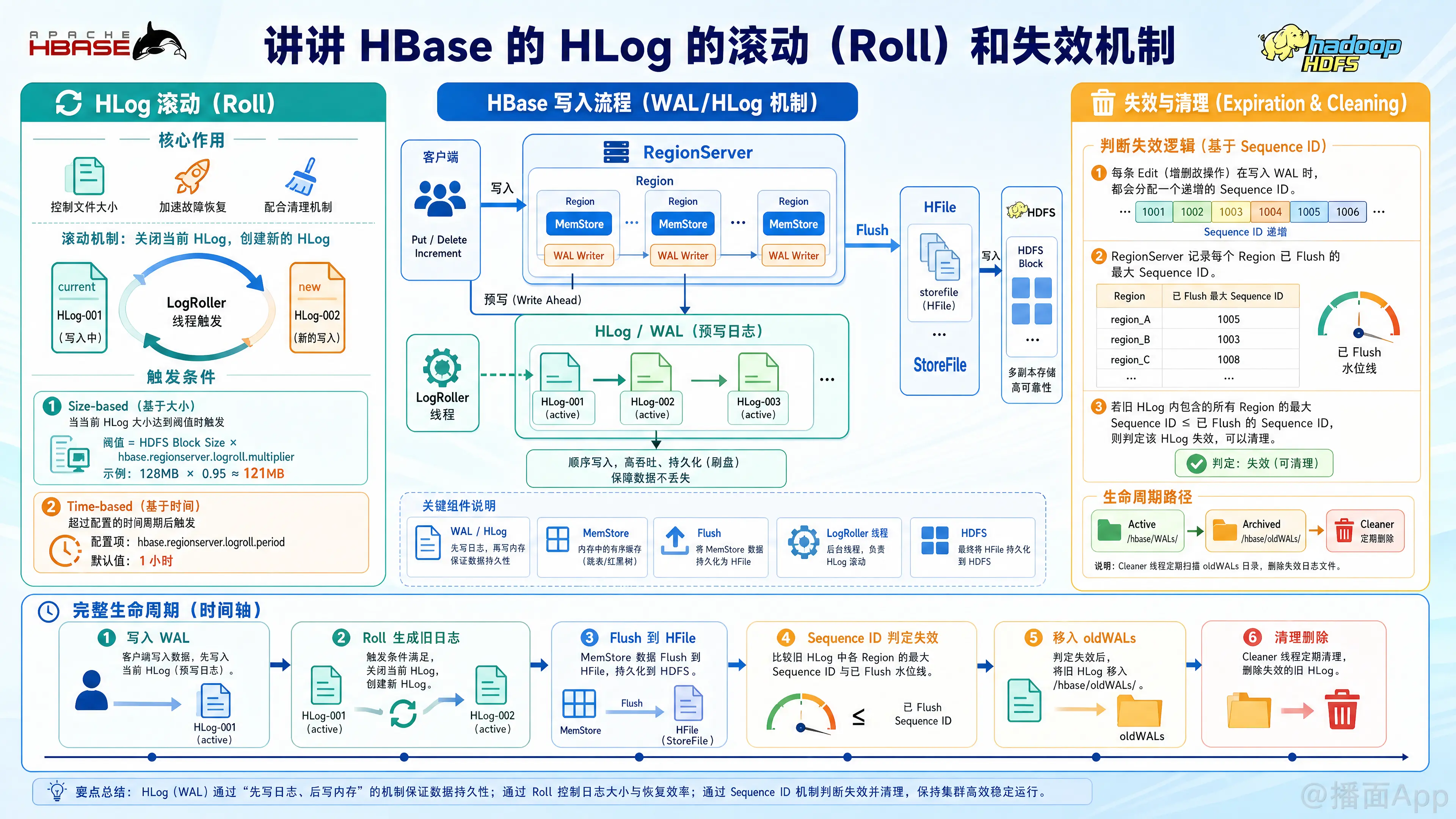
在 HBase 中,HLog(在较新的版本中通常称为 WAL, Write-Ahead Log,即预写日志)是保障数据高可用和容错的核心组件。当客户端写入数据时,数据会先写入 HLog,然后再写入内存(MemStore)。如果 RegionServer 宕机,HBase 可以通过回放 HLog 中的数据来恢复尚未持久化到磁盘的数据。
为了防止 HLog 文件无限增大导致磁盘写满或恢复时耗时过长,HBase 设计了 滚动(Roll) 和 失效清理(Expiration/Cleaning) 机制。
以下是这两个机制的详细原理解析:
一、 HLog 的滚动机制(Roll)
滚动(Roll) 是指 HBase 停止向当前的 HLog 文件写入数据,关闭该文件,并创建一个新的 HLog 文件继续接收后续写入请求的过程。
1. 为什么需要滚动?
- 控制文件大小: 避免单个 HLog 文件过大,影响 HDFS 的读写效率。
- 加速故障恢复: 如果单个日志文件过大,RegionServer 宕机后回放日志的时间会非常漫长。
- 配合清理机制: 只有处于关闭状态的旧 HLog 文件,才有可能被判定为“失效”并最终被清理。
2. 触发滚动的条件
HBase 后台有一个专属线程 LogRoller 定期检查是否需要滚动 HLog,触发条件主要有以下两种:
基于文件大小(Size-based):
当当前的 HLog 文件大小达到设定阈值时,触发滚动。
阈值计算公式:HDFS Block Size*hbase.regionserver.logroll.multiplier
注:HDFS Block 默认通常是 128MB,multiplier 默认是 0.95。即当文件大小达到 Block 大小的 95% 时(约 121MB),就会触发滚动。这是为了尽量保证一个 HLog 文件存放在一个 HDFS Block 内,减少跨节点读取。基于时间周期(Time-based):
为了防止某个 HLog 文件因为写入量极少而长时间不关闭,HBase 设定了最大时间周期。
相关配置:hbase.regionserver.logroll.period(默认值是 1 小时)。即无论文件多小,每隔 1 小时都会强制生成一个新的 HLog。
二、 HLog 的失效与清理机制(Expiration & Cleaning)
滚动产生的旧 HLog 不能永远保留。失效机制的核心逻辑是:判断旧 HLog 中的数据是否已经安全地落盘(Flush 到 HFile 中)。如果已经全部落盘,这个 HLog 就“失效”了,可以被清理。
1. 如何判断 HLog 失效?(Sequence ID 机制)
这是 HBase HLog 管理中最精妙的部分:
- 每次往 HBase 写入一条数据,Region 都会为这条数据分配一个递增的序列号(Sequence ID)。HLog 中记录的每条 Edit 都有这个 ID。
- HBase 会在内存中记录每个 Region 当前已经 Flush 到磁盘的最大的 Sequence ID。
- 对于一个已经关闭的 HLog 文件,HBase 会检查它里面包含的所有 Region 数据。如果这个 HLog 中所有 Region 的最大 Sequence ID,都小于或等于这些 Region 当前已经 Flush 到磁盘的 Sequence ID,那就说明这个 HLog 里的所有数据都已经持久化到 HFile 中了。此时,即使机器宕机,也不需要这个 HLog 来恢复数据了,该 HLog 即被判定为失效。
2. HLog 的生命周期与清理流程
失效的 HLog 不会被立刻物理删除,而是经历以下流转过程:
- Active 状态(
/hbase/WALs/目录下):
正在写入的,或者虽然已经 Roll(关闭)但里面的数据尚未完全 Flush 落盘的 HLog。 - 归档状态(
/hbase/oldWALs/目录下):
当 HLog 被判定为失效后,它会被从WALs目录移动到oldWALs目录。
为什么不直接删除? 因为 HBase 的其他功能(如主从复制 Replication 或 快照 Snapshot)可能还需要读取这些日志。 - 彻底删除(物理删除):
HMaster 节点上有一个后台线程LogCleaner,它会定期(默认每分钟)扫描oldWALs目录,并询问多个“清理插件(Cleaner Delegates)”:- ReplicationLogCleaner: 检查这个日志是否已经被同步到备集群?如果还没有,保留。
- SnapshotLogCleaner: 检查是否有 Snapshot 正在引用这个日志?如果有,保留。
- TimeToLiveLogCleaner: 检查该文件在
oldWALs里的停留时间是否超过了 TTL 配置(hbase.master.logcleaner.ttl,默认 10 分钟)。
如果所有插件都放行,且超过了 TTL,LogCleaner就会将该 HLog 文件从 HDFS 上物理删除。
三、 滚动与失效机制的联动(写入阻塞问题)
理解了 Roll 和 清理机制,还需要了解它们是如何影响性能的。这里有一个经典的 HBase 性能瓶颈场景:
- 配置
hbase.regionserver.maxlogs: 这个配置定义了一个 RegionServer 上最多能保留的未失效的 HLog 文件数量(默认值通常是 32)。 - 触发强制 Flush(阻塞写): 如果写入速度极快,HLog 不断 Roll 产生新文件,但是 MemStore 里的数据还没来得及 Flush 到磁盘,导致旧 HLog 无法失效。当未失效的 HLog 数量达到
maxlogs限制时,HBase 会阻塞客户端的所有写入。 - 自救动作: 此时,HBase 会强制挑选那些包含最旧未落盘数据的 MemStore 进行 Flush 操作。只有当 Flush 完成,旧的 HLog 被判定失效并移走后,HLog 数量降到限制以下,客户端的写入阻塞才会解除。
总结
- HLog 滚动(Roll): 解决的是“文件太大”和“写太久”的问题,基于文件大小和时间周期触发,将当前日志切分关闭,生成新日志。
- HLog 失效(Expiration): 解决的是“何时可以丢弃历史日志”的问题,基于 Sequence ID 判断数据是否已完全 Flush 落盘。落盘后的 HLog 会被放入
oldWALs目录,等待LogCleaner结合 Replication、TTL 等条件进行最终的物理回收。