 播面
播面 MyBatis一级缓存的工作原理和生命周期
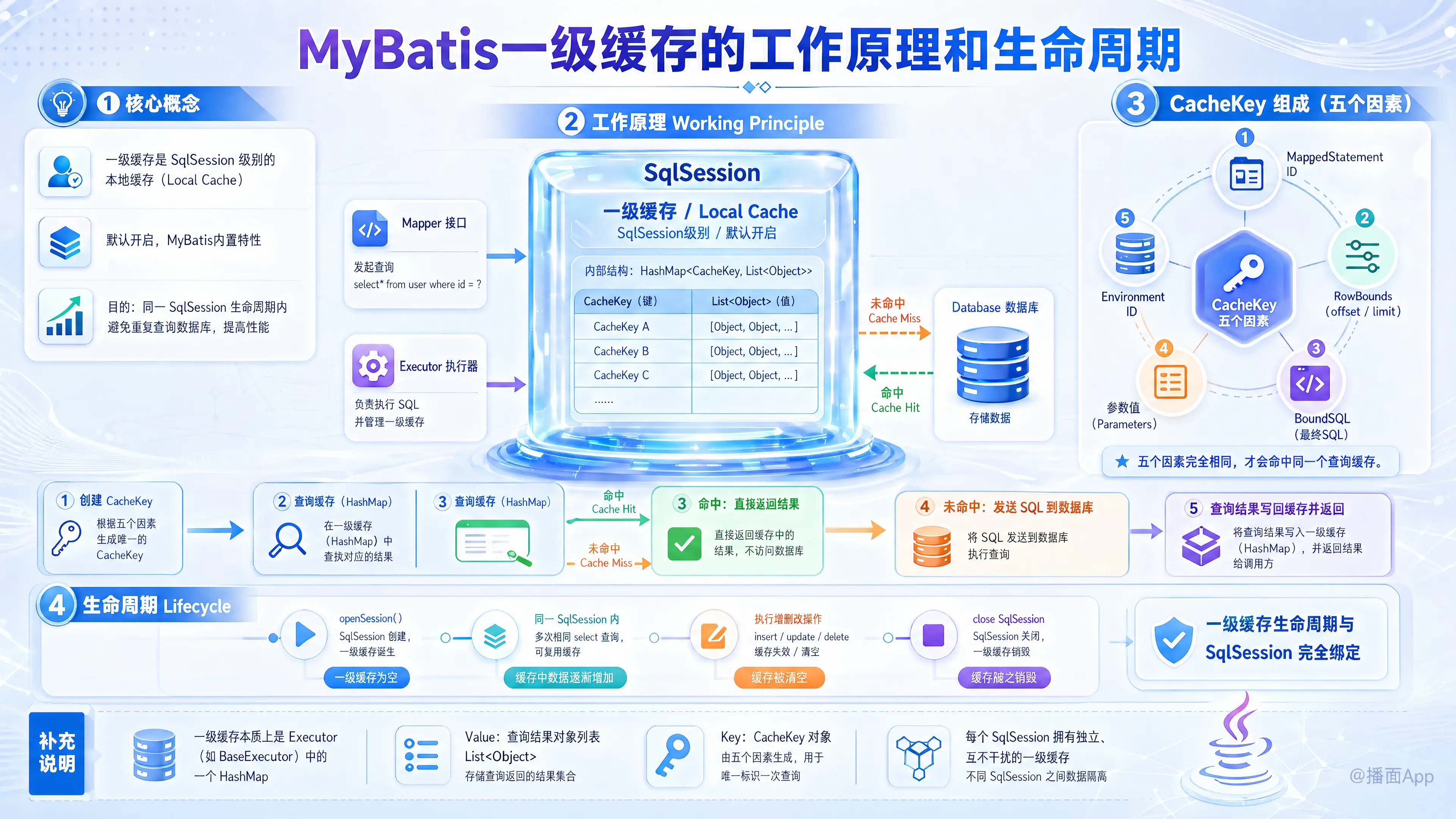
MyBatis 一级缓存是 SqlSession 级别的本地缓存,默认开启。在同一 SqlSession 生命周期内,它能缓存查询结果,避免重复访问数据库。执行增删改操作或关闭 SqlSession 时,缓存会失效。
我们来详细解析一下 MyBatis 的一级缓存(L1 Cache)的工作原理和生命周期。
核心概念
首先,我们需要明确几个核心概念:
- 一级缓存是 SqlSession 级别的缓存:它也被称为本地缓存(Local Cache)。
- 默认开启:一级缓存是 MyBatis 内置的特性,默认就是开启的,而且无法被关闭。
- 目的:在同一个
SqlSession的生命周期内,对相同的查询请求,避免重复查询数据库,从而提高性能。
一、工作原理 (Working Principle)
MyBatis 的一级缓存本质上是一个 HashMap,存储在 SqlSession 的一个实现类(如 DefaultSqlSession)内部,具体来说是在 Executor(执行器,如 BaseExecutor)中。
1. 缓存的 Key 和 Value
- Value:查询返回的结果对象列表(
List<Object>)。 - Key:
CacheKey对象。这是一个非常关键的对象,它唯一地标识了一个查询。MyBatis 会根据以下五个因素来计算生成一个CacheKey:- MappedStatement ID:即 Mapper 接口中的方法的全限定名(如
com.example.UserMapper.selectById)。 - RowBounds:分页参数(offset 和 limit)。
- BoundSQL:最终执行的 SQL 语句。
- 传入的参数:执行查询时传递给方法的参数值。
- Environment ID:MyBatis 的环境配置 ID。
- MappedStatement ID:即 Mapper 接口中的方法的全限定名(如
只要这五个因素完全相同,MyBatis 就会认为这是同一个查询,生成的 CacheKey 也是相同的。
2. 工作流程
当一个 SqlSession 执行一个查询(select)操作时,其内部流程如下:
- 创建
CacheKey:MyBatis 根据当前执行的查询语句、参数等信息,创建一个唯一的CacheKey。 - 查询缓存:使用这个
CacheKey去SqlSession内部的本地缓存(一个HashMap)中查找对应的结果。- 缓存命中 (Cache Hit):如果缓存中存在这个
CacheKey,MyBatis 会直接从缓存中取出对应的结果(Value),并立即返回给调用者。此时,不会再向数据库发送 SQL 请求。 - 缓存未命中 (Cache Miss):如果缓存中不存在这个
CacheKey,MyBatis 会执行常规的数据库查询流程。
- 缓存命中 (Cache Hit):如果缓存中存在这个
- 查询数据库:向数据库发送 SQL 请求。
- 存储结果:将从数据库查询到的结果存入本地缓存中,Key 就是第一步生成的
CacheKey,Value 就是查询结果。 - 返回结果:将查询结果返回给调用者。
二、生命周期 (Lifecycle)
一级缓存的生命周期与 SqlSession 的生命周期是完全绑定的。
1. 缓存的创建 (Birth)
- 当
SqlSessionFactory.openSession()被调用时,一个新的SqlSession对象被创建。 - 与此同时,这个
SqlSession内部的一级缓存也被创建出来。
每个 SqlSession 对象都拥有一个独立、互不干扰的一级缓存。
java
// 当执行这行代码时,一个新的 SqlSession 和它的一级缓存就诞生了
SqlSession sqlSession1 = sqlSessionFactory.openSession();
SqlSession sqlSession2 = sqlSessionFactory.openSession();
// sqlSession1 和 sqlSession2 拥有各自独立的一级缓存2. 缓存的存活 (Life)
- 只要
SqlSession对象没有被关闭(close()),它内部的一级缓存就一直存在。 - 在此期间,所有通过这个
sqlSession实例执行的查询都可能会使用到这个缓存。
java
try (SqlSession sqlSession = sqlSessionFactory.openSession()) {
UserMapper mapper = sqlSession.getMapper(UserMapper.class);
// 第一次查询,缓存未命中,会查询数据库
// 查询结果会被放入一级缓存
User user1 = mapper.selectById(1);
System.out.println("第一次查询: " + user1);
// 第二次用完全相同的参数查询
// 缓存命中,直接从一级缓存返回结果,不会再发SQL
User user2 = mapper.selectById(1);
System.out.println("第二次查询: " + user2);
// user1 和 user2 是同一个 Java 对象实例
System.out.println(user1 == user2); // 输出 true
}3. 缓存的销毁/清空 (Death/Clear)
一级缓存并不是永远有效的,在以下几种情况下,它会被清空或销毁:
SqlSession关闭:- 当调用
sqlSession.close()方法时,SqlSession会被销毁,其内部的一级缓存也随之被销毁。这是最常见的缓存生命周期结束的方式。
- 当调用
执行写操作 (CUD):
- 当执行任何
insert,update,delete操作时,MyBatis 会认为数据库中的数据已经发生了变化。 - 为了保证数据的一致性,避免读到“脏数据”(过时的缓存数据),MyBatis 会自动清空当前
SqlSession中的一级缓存。 - 这是 MyBatis 的一个安全机制,确保了缓存的有效性。
javatry (SqlSession sqlSession = sqlSessionFactory.openSession()) { UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user1 = mapper.selectById(1); // 查询数据库,并缓存结果 // 执行一次更新操作 User updateUser = new User(); updateUser.setId(1); updateUser.setName("New Name"); mapper.updateUser(updateUser); sqlSession.commit(); // 提交事务(commit本身也会清空缓存) // 再次查询 // 因为之前的 update 操作清空了缓存,这里会再次查询数据库 User user2 = mapper.selectById(1); }- 当执行任何
手动清空缓存:
- 可以调用
sqlSession.clearCache()方法来手动清空当前SqlSession的一级缓存。
- 可以调用
事务提交/回滚:
- 调用
sqlSession.commit()或sqlSession.rollback()时,通常也会清空一级缓存,以确保数据一致性。
- 调用
localCacheScope配置:- MyBatis 有一个全局配置
localCacheScope,它有两个值:SESSION(默认值): 缓存范围是整个会话。在SqlSession关闭前,缓存都有效(除非被动清空)。STATEMENT: 缓存范围仅限于单条语句的执行。每执行完一条select语句,缓存就会被清空。这相当于变相地禁用了一级缓存。
- 配置方式(在
mybatis-config.xml中):
xml<settings> <setting name="localCacheScope" value="STATEMENT"/> </settings>- MyBatis 有一个全局配置
总结与注意事项
- 生命周期:一级缓存随
SqlSession的创建而生,随SqlSession的关闭而死。 - 作用域:一级缓存是
SqlSession内部的,不同SqlSession之间的一级缓存是隔离的。这意味着在一个请求中创建的SqlSession的缓存,在另一个请求中创建的SqlSession是无法访问的。 - 失效场景:执行 CUD 操作、手动调用
clearCache()、commit()或close()都会导致一级缓存被清空。 - 与二级缓存的关系:当同时开启一级和二级缓存时,查询的顺序是:一级缓存 -> 二级缓存 -> 数据库。只有一级缓存未命中时,才会去查找二级缓存。
- 适用场景:一级缓存非常适合在同一个业务事务中,需要多次查询相同数据的场景,可以有效减少数据库交互次数。例如,在一个 service 方法中,先查询一个用户,后面又因为其他逻辑需要再次查询这个用户。