 播面
播面 在 Flush 过程中,如果写入速度远快于刷写速度,HBase 是如何进行流量控制或阻塞写入的?
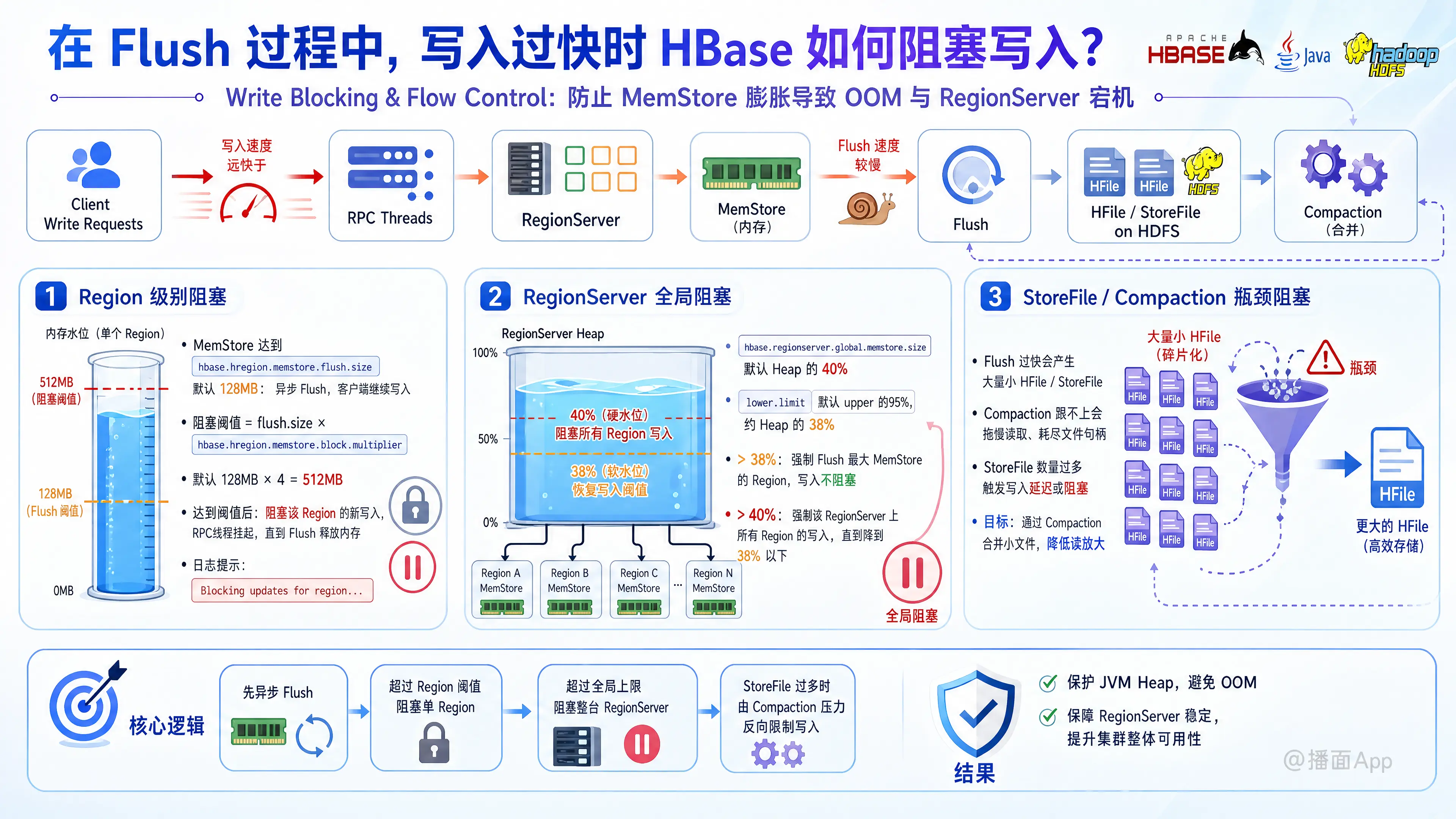
在 HBase 中,如果客户端的写入速度远大于 RegionServer 的刷写(Flush)或合并(Compaction)速度,系统如果没有干预机制,MemStore 会无限制地占用内存,最终导致 Java 虚拟机发生 OOM (Out Of Memory),进而导致 RegionServer 宕机。
为了防止这种情况,HBase 设计了一套多层次的流量控制和阻塞机制(Write Blocking & Flow Control)。当写入过快时,HBase 会在以下三个主要层级触发阻塞:
1. Region 级别的阻塞 (Region-Level Blocking)
这是最直接的控制机制,作用于单个 Region。
- 正常刷写触发:
当一个 Region 中的 MemStore 大小达到hbase.hregion.memstore.flush.size(默认 128MB)时,HBase 会在后台启动一个异步的 Flush 任务。此时,客户端依然可以继续写入。 - 触发阻塞(Write Blocking):
如果 Flush 速度太慢,而写入极快,MemStore 的大小会继续膨胀。当 MemStore 的大小达到以下阈值时:阻塞阈值 = hbase.hregion.memstore.flush.size * hbase.hregion.memstore.block.multiplier
(注:block.multiplier默认值为 4,即 128MB * 4 = 512MB) - 系统行为:
此时,RegionServer 会完全阻塞对该 Region 的所有新写入请求。处理写入的 RPC 线程会被挂起,直到 Flush 操作完成释放出内存。在日志中通常会看到Blocking updates for region...的警告。
2. RegionServer 级别的全局阻塞 (Global MemStore Blocking)
如果写入非常分散,单个 Region 都没有达到 512MB 的阻塞线,但整个 RegionServer 上成百上千个 Region 的 MemStore 总和在不断增加,依然有 OOM 的风险。HBase 为此设计了全局级别的内存水位线。
- 全局内存上限 (Upper Limit):
hbase.regionserver.global.memstore.size(旧版本为upperLimit),默认值是堆内存(Heap Size)的 40% (0.4)。 - 全局内存下限 (Lower Limit / Soft Limit):
hbase.regionserver.global.memstore.size.lower.limit,默认是全局上限的 95% (0.95),也就是堆内存的 38%。 - 系统行为:
- 越过下限 ( > 38%): RegionServer 会触发强制 Flush,它会找出当前内存占用最大的几个 Region 强行进行刷写(即使它们没达到 128MB)。此时,写入依然不会被阻塞,但 Flush 线程会满负荷工作。
- 越过上限 ( > 40%): 这是极度危险的红线。一旦触发,RegionServer 会阻塞对该节点上所有 Region 的所有写入请求,直到总 MemStore 内存降到下限(38%)以下。这会导致整个 RegionServer 级别的写停顿,对业务影响巨大。
3. StoreFile 级别的阻塞 (Compaction 瓶颈)
有时候 Flush 速度其实跟得上,但因为 Flush 得太快,底层 HDFS 上生成了大量细碎的 HFile (StoreFile)。如果合并(Compaction)的速度跟不上 Flush 的速度,过多的 HFile 会严重拖慢读取性能,并耗尽文件句柄。
- 配置参数:
hbase.hstore.blockingStoreFiles(默认值在较新版本中通常是 16)。 - 系统行为:
当某个 Store(对应一个列族)下的 HFile 数量达到这个设定值时,HBase 会阻塞对该 Region 的写入,强制等待 Compaction 完成。 - 等待超时参数:
hbase.hstore.blockingWaitTime(默认 90 秒)。
如果等待超过 90 秒,Compaction 还没把文件数量降下来,HBase 会解除阻塞,允许继续写入(但性能会很差),以防业务彻底死锁。日志中通常会看到Too many store files... blocking updates。
4. 客户端的表现与背压 (Backpressure)
当上述任何一种阻塞发生时,对客户端产生的影响如下:
- RPC 线程积压: RegionServer 的 Handler 线程(处理 RPC 请求的线程)会被挂起等待。如果写入请求源源不断,Handler 线程池很快被耗尽。
- 客户端超时与重试: 客户端迟迟得不到 RegionServer 的 ACK 响应,会触发
CallTimeoutException。客户端会自动进行指数退避(Exponential Backoff)并重试。 - RegionTooBusyException: 在较新的 HBase 版本中,为了防止 RPC 队列雪崩,当内存超过上限时,RegionServer 会直接拒绝请求,向客户端抛出
RegionTooBusyException或RpcThrottlingException。客户端捕获后应暂停写入。 - HBase 2.x 的反压机制 (Backpressure): HBase 引入了更优雅的流控机制(基于 Quota 的节流)。客户端可以感知到服务端的负载压力,并在客户端层面主动降低发送速率,而不是死等超时。
💡 总结与调优建议
当遇到“写入速度远快于刷写速度”导致的阻塞时,通常是集群配置与业务负载不匹配,建议从以下几个方面优化:
- 预分区(Pre-splitting): 确保写入流量均匀分布到多个 RegionServer 上,避免单个节点/单个 Region 成为热点(打满
block.multiplier)。 - 增大 Flush 线程数: 调大
hbase.regionserver.flusher.count(默认通常为 2),让服务端有更多的线程去执行刷写。 - 调整 StoreFile 阻塞阈值: 如果磁盘 IO 撑得住,可以适当调大
hbase.hstore.blockingStoreFiles(例如调到 30-50),用一点读性能换取更高的写吞吐。 - 硬件层面: 将 WAL 日志的写入目录放在独立的 SSD 上,提升 Flush 和 WAL 同步的速度。
- 批量写入与客户端限流: 在业务代码层面使用异步批量写入(BufferedMutator),并在业务侧做好降级和限流,避免瞬时流量压垮 HBase。