 播面
播面 讲讲 HBase HFile 的物理结构以及它是如何支持快速随机读取的。
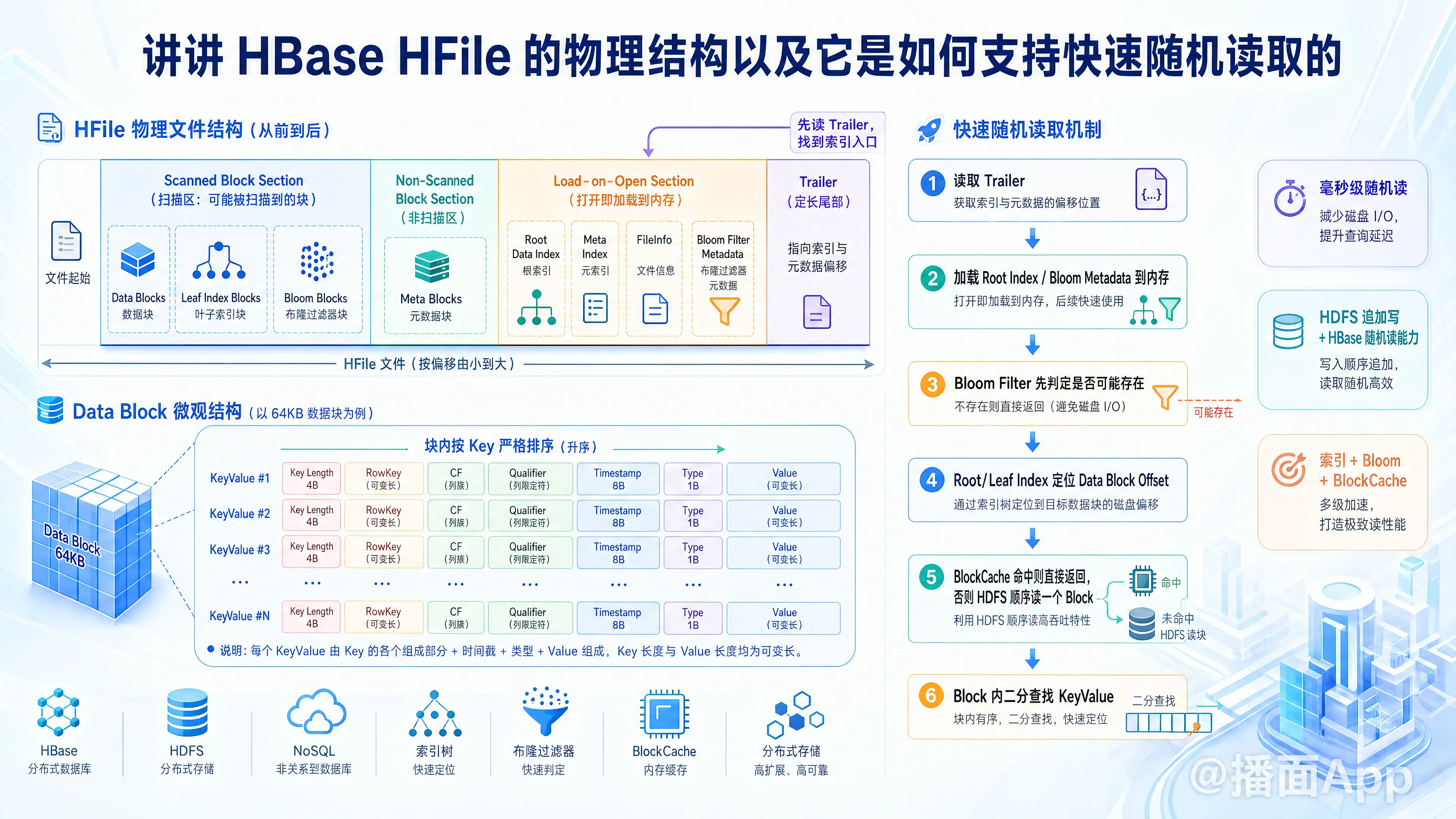
HBase 是一个构建在 HDFS(分布式且仅支持追加写入的文件系统)之上的 NoSQL 数据库。HDFS 本身不支持随机读写,而 HBase 能够实现毫秒级的随机读取,这在很大程度上要归功于其底层存储文件 HFile 的精妙设计。
目前 HBase 主要使用的是 HFile V2(及支持 Cell Tags 的 V3)格式。下面我将从 HFile 的 物理结构 以及 支持快速随机读取的机制 两个方面进行深度解析。
一、 HFile 的物理结构 (Macro & Micro Structure)
HFile 是一个按 Block(数据块)组织的二进制格式文件。默认情况下,一个 Data Block 的大小是 64KB。HFile 的整体结构从逻辑上可以分为四大区域(从前往后排布):
1. 宏观结构(四大区域)
- Scanned Block Section(扫描块区域)
- Data Blocks(数据块):实际存储 Key-Value 数据的地方。数据在块内是严格按 Key 排序的。
- Leaf Index Blocks(叶子索引块):Data Block 的叶子索引,存储每个 Data Block 的起始 Key。
- Bloom Blocks(布隆过滤器块):存储布隆过滤器的数据,用于快速判断某个 RowKey/Column 是否存在于该 HFile 中。
- Non-Scanned Block Section(非扫描块区域)
- Meta Blocks(元数据块):主要留作扩展使用,目前 HBase 较少直接使用该区域。
- Load-on-Open Section(打开即加载区域)
- 这部分数据在 HFile 被 RegionServer 打开时,就会直接加载到内存中。
- Root Data Index(数据块根索引):指向 Leaf Index Blocks 的索引(如果 HFile 很大,索引会变成多级结构;如果较小,根索引直接指向 Data Block)。
- Meta Index(元数据块索引):指向 Meta Blocks 的索引。
- FileInfo(文件信息):包含该文件的元数据,例如:平均 Key 长度、平均 Value 长度、最小 Timestamp、最大 Timestamp 等。
- Bloom Filter Metadata:布隆过滤器的元数据。
- Trailer(尾部)
- 定长的数据结构,位于文件最末尾。
- 存储了指向 Load-on-Open 区域各个部分起始偏移量的指针。
- HBase 读取 HFile 时,首先读取 Trailer,顺藤摸瓜找到索引等信息。
2. 微观结构(Key-Value 格式)
在 Data Block 内部,数据是按 Key-Value 紧密排列的。HBase 的 Key 结构非常复杂,这也是它能支持多维度查询的原因:
- Key Length (4 bytes)
- Value Length (4 bytes)
- Key 数据:
- RowKey Length (2 bytes) + RowKey (字节数组)
- Column Family Length (1 byte) + Column Family
- Column Qualifier (列限定符)
- Timestamp (8 bytes)
- KeyType (1 byte,例如 Put, Delete, DeleteColumn 等)
- Value 数据:实际的业务数据。
核心特点:Data Block 内的数据按
RowKey -> Column Family -> Column Qualifier -> Timestamp (降序) -> KeyType的字典序严格排列。
二、 HFile 如何支持快速随机读取?
既然 HDFS 只能顺序读,HBase 是如何做到快速随机读的?HFile 通过以下 5 大核心机制 化腐朽为神奇:
1. 多级索引结构(类似 B+ 树)
HFile 内部实现了自己的多级索引机制。
- 寻址过程:当进行 Get(RowKey) 查询时,RegionServer 首先在内存中的 Root Data Index 进行二分查找,找到对应的 Leaf Index Block(如果配置了多级索引);然后再在 Leaf Index 中二分查找,最终定位到具体的 Data Block 在 HDFS 中的偏移量。
- 效果:通过加载到内存的极小的索引数据,就可以在数 GB 的 HFile 中精确定位到 64KB 的目标数据块,极大地减少了磁盘 I/O。
2. 块内二分查找
定位到 Data Block 后,HBase 会将这 64KB 的 Block 从 HDFS 加载到内存。
由于 Block 内部的 Key-Value 是严格按字典序连续排列的,HBase 无需顺序遍历整个 Block,而是直接在内存中对该 Block 进行二分查找,瞬间定位到具体的 Key-Value。
3. 布隆过滤器 (Bloom Filter) 拦截无效 I/O
随机读最怕的是“大海捞针”却发现“针”不在海里(即查询不存在的数据),这会白白浪费磁盘 I/O 去读取数据块。
- 机制:HFile 在写入时生成布隆过滤器(支持 Row 级别或 Row+Col 级别)。布隆过滤器的元数据常驻内存。
- 效果:查询时,先通过 Bloom Filter 判断该 RowKey/Column 是否可能存在于这个 HFile 中。如果 Bloom Filter 说不存在,那么绝对不存在,直接跳过该文件;如果说可能存在,再去查索引。这在应对大规模、多 HFile 文件的读取时,过滤掉了大量无效的磁盘读取。
4. FileInfo 里的时间范围过滤 (Time Range 剪枝)
HBase 支持多版本(基于 Timestamp)。很多查询会带有时间范围(例如只查最近 1 小时的数据)。
- 机制:HFile 尾部的
FileInfo中保存了该文件内所有数据的[Min Timestamp, Max Timestamp]。 - 效果:如果查询条件携带了 TimeRange,HBase 会将查询范围与 FileInfo 中的时间范围做交集判断。如果没有交集,直接跳过该 HFile。
5. Block Cache (块缓存)
HBase 的 RegionServer 维护了读缓存(Block Cache,如 LRUBlockCache 或 BucketCache)。
- 机制:当 HBase 因为一次随机读将某个 64KB 的 Data Block 从 HDFS 读入内存后,该 Block 会被缓存在 Block Cache 中。
- 效果:HBase 的数据读取具有典型的空间局部性。如果是同一行数据的其他列,或者相邻行的随机读,下一次读取可以直接命中内存中的 Block,完全不需要访问 HDFS,实现了真正的内存级随机读速度。
总结:一次完整 HBase 随机读在 HFile 视角的流程
当你发起一次 Get(RowKey) 时:
- Trailer & Load-on-Open:系统早就解析了 HFile 尾部,把 Root Index、FileInfo、Bloom Meta 放到了内存。
- Time & Bloom 过滤:检查 FileInfo 的时间范围是否匹配;检查 Bloom Filter 判断该 RowKey 是否存在。若不满足,直接跳过该文件(0 磁盘 I/O)。
- 索引查找:在内存中的 Root Index -> (Intermediate Index) -> Leaf Index 中进行二分查找,找到目标数据所在的 Data Block 偏移量。
- 缓存命中:去 Block Cache 检查该 Data Block 是否已在内存中。如果命中,直接读取。
- 磁盘 I/O:如果不命中,通过 HDFS 客户端在指定偏移量处读取该 64KB 的 Data Block,并放入 Block Cache。
- 块内查找:在内存中的这个 64KB 块内,进行二分查找,精确提取出你要的 Key-Value 及其版本。
一句话概括:HFile 并非让 HDFS 拥有了随机读的能力,而是通过有序存储 + 多级索引 + 布隆过滤器 + 数据块缓存,将海量数据的全局随机读,降维转化成了极少量的、精确定位的 HDFS 局部顺序读和内存级别的二分查找,从而实现了毫秒级的随机读取。