 播面
播面 讲讲 HBase 读取数据的完整流程
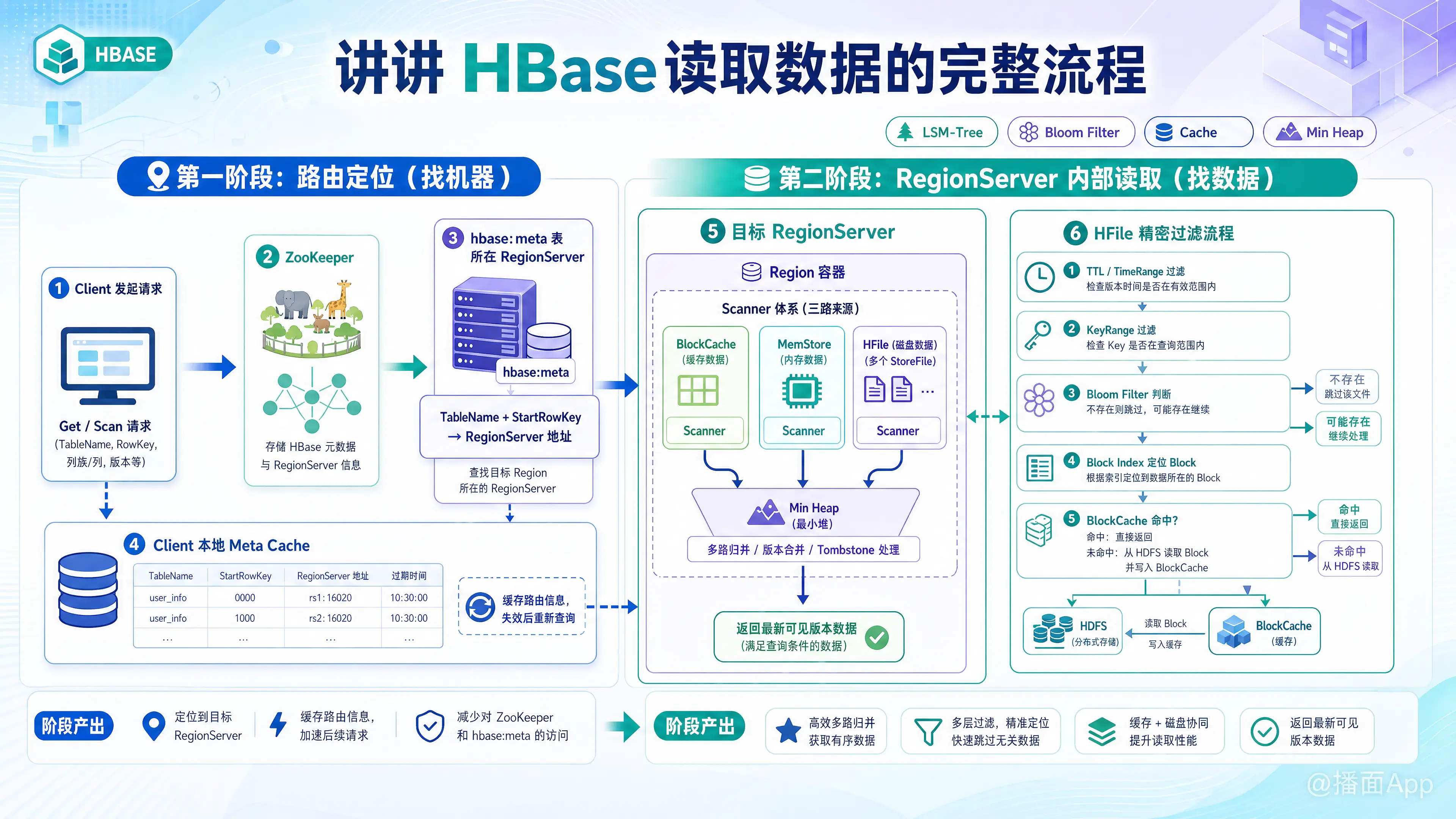
HBase 是基于 LSM-Tree(Log-Structured Merge-Tree)架构的分布式 NoSQL 数据库。与传统关系型数据库(如 MySQL 的 B+ 树)不同,HBase 的写入速度极快,但读取过程相对复杂,因为数据可能分散在内存(MemStore)和磁盘的多个文件(HFile)中。
HBase 的完整读取流程可以分为两个大阶段:路由定位阶段(找机器) 和 RegionServer 内部读取阶段(找数据)。
以下是完整的详细流程:
第一阶段:路由定位(Client 寻找数据的存放位置)
HBase 表的数据按 RowKey 范围被切分成多个 Region,分散在不同的 RegionServer 上。客户端首先需要知道目标数据在哪个 RegionServer 的哪个 Region 上。
- 访问 ZooKeeper:
客户端(Client)发起读请求(如Get或Scan),首先连接 ZooKeeper。ZK 中保存了hbase:meta表(元数据表)所在的 RegionServer 地址。 - 查询
hbase:meta表:
客户端根据 ZK 提供的地址,访问对应的 RegionServer,读取hbase:meta表。该表中记录了所有用户表的 Region 路由信息(即TableName + StartRowKey->RegionServer 地址)。 - 缓存路由信息:
客户端根据请求的 RowKey,在元数据中找到目标 Region 所在的 RegionServer 地址。为了提高性能,客户端会将这个路由信息缓存到本地(Meta Cache)。下次读取时直接走缓存,只有当缓存失效(比如发生 Region 负载均衡或机器宕机导致 Region 迁移)时,才会重新走 1、2 步。
第二阶段:RegionServer 内部读取流程(核心)
客户端定位到目标 RegionServer 后,发送读取请求。RegionServer 接收到请求后,流程如下:
1. 构建 Scanner 体系
由于 HBase 支持多版本(Version),且数据被修改或删除时只是追加记录(Tombstone 墓碑标记,而不是原地修改),因此目标数据可能存在于:
- BlockCache:读缓存(之前读过的数据块)。
- MemStore:写缓存(最近写入、还没刷写到磁盘的数据)。
- HFile:磁盘文件(已经刷写到 HDFS 上的历史数据,可能有多个文件)。
为了获取最新、最准确的数据,HBase 会为上述三个地方分别创建 Scanner(扫描器),然后将它们放入一个最小堆(Min Heap)中进行多路归并合并。
2. 具体的读取顺序与过滤机制
实际上,HBase 并不是傻傻地扫描所有文件,而是有一套极其精密的过滤和查找机制:
第一步:过滤不需要读取的 HFile
在读取磁盘上的 HFile 之前,HBase 会利用以下机制大量排除无关文件:
- TTL 与 TimeRange:如果客户端指定了时间范围,或者数据有过期时间(TTL),HFile 的元数据中保存了该文件的最大最小时间戳,如果不匹配则直接跳过该文件。
- KeyRange:HFile 元数据保存了该文件 RowKey 的起始和结束范围,如果要找的 RowKey 不在范围内,直接跳过。
- 布隆过滤器(Bloom Filter):这是极其重要的一环。HBase 会查询 HFile 对应的布隆过滤器,快速判断目标 RowKey(或 RowKey:ColumnFamily)是否一定不存在于该 HFile 中。如果布隆过滤器说“不在”,则绝对跳过;如果说“可能在”,才继续下一步。
第二步:定位 Block 并利用 BlockCache
通过了过滤的 HFile,HBase 需要从中把数据读出来:
- HFile 内部是由多个 Block(默认 64KB)组成的。HBase 会在内存中查找 HFile 的 Block Index(块索引),通过二分查找快速定位到目标 RowKey 所在的具体 Block。
- 知道是哪个 Block 后,HBase 首先去 BlockCache(读缓存)中查找 这个 Block 是否已经在内存中了。
- 如果在 BlockCache 中命中,则直接读取。
- 如果未命中(Cache Miss),则通过 HDFS 去磁盘读取该 Block,读取出来后,将这个 Block 放入 BlockCache 中,以便下次其他请求读取该块内的数据时能直接走内存。
第三步:MemStore 与合并(Merge)
数据不仅仅在 HFile 中,最新写入的数据还在 MemStore(写缓存)里:
- HBase 同时也会去 MemStore 中查找对应的 RowKey。
- 此时,HBase 拥有了来自 MemStore 的数据、以及来自各个 HFile(经过 BlockCache 加载)的数据。
- HBase 的
KeyValueHeap(多路归并读取器)会将这些数据根据 RowKey -> ColumnFamily -> ColumnQualifier -> Timestamp(时间戳递减) -> Type(类型) 进行排序和归并。
第四步:处理版本与删除标记
在归并的过程中:
- 如果遇到一条数据的类型是
Delete(删除标记),则会忽略在这条数据之前(时间戳更小)的所有版本数据。 - 如果找到了用户请求的版本数量(比如用户只请求最新版本
MaxVersions=1),获取到最新时间戳的数据后,就会停止扫描剩余的旧版本。
第三阶段:返回结果
RegionServer 将合并、过滤后的最终准确数据,通过网络返回给客户端,整个读流程结束。
总结:HBase 读取流程简图
[Client]
|
|--1. 查本地缓存 (未命中则去 ZK -> hbase:meta 获取目标 RegionServer 地址)
|
V
[RegionServer]
|
|--2. 定位到具体的 Region 和 Store (列族)
|
|--3. 构建多路 Scanner 准备合并读取:
|
|-- a) MemStore (最近写入的数据)
|
|-- b) 过滤 HFile (TimeRange -> RowKey Range -> BloomFilter)
|
|-- c) 定位 HFile 的 Block,检查 BlockCache 是否命中。
| 未命中则读磁盘 HDFS 加载 Block 到 BlockCache。
|
|--4. 多路归并排序 (MemStore数据 + BlockCache数据 + HFile加载的数据)
|
|--5. 版本过滤、处理删除标记 (Tombstone)
|
V
[Client] (收到最终结果)面试核心考点 / 常见误区:
- 误区:HBase 读数据是“先读内存 MemStore,找不到再读磁盘”。
- 正解:由于数据可能会被更新或删除,最新版本可能在 MemStore,旧版本可能在磁盘。为了保证数据一致性,HBase 必须同时构建 MemStore Scanner 和 StoreFile Scanner 进行归并合并,而不是简单的前后顺序。
- 读缓存是什么?
- HBase 的读缓存是 BlockCache,它缓存的是整个 Block(默认 64KB,包含相邻的多条记录),而不是单条 RowKey。这就是为什么 HBase 适合 Scan 连续读取的原因。
- 读取慢的瓶颈在哪里?
- 如果 BlockCache 未命中,且布隆过滤器也没能挡住,就需要去 HDFS 读多个 HFile。HFile 越多(没有及时 Compaction),需要归并的文件就越多,读性能就越差。这就是为什么 HBase 后台需要做 Compaction(合并文件)的原因。