 播面
播面 HBase 中的 ROW 和 ROWCOL 布隆过滤器有什么区别?
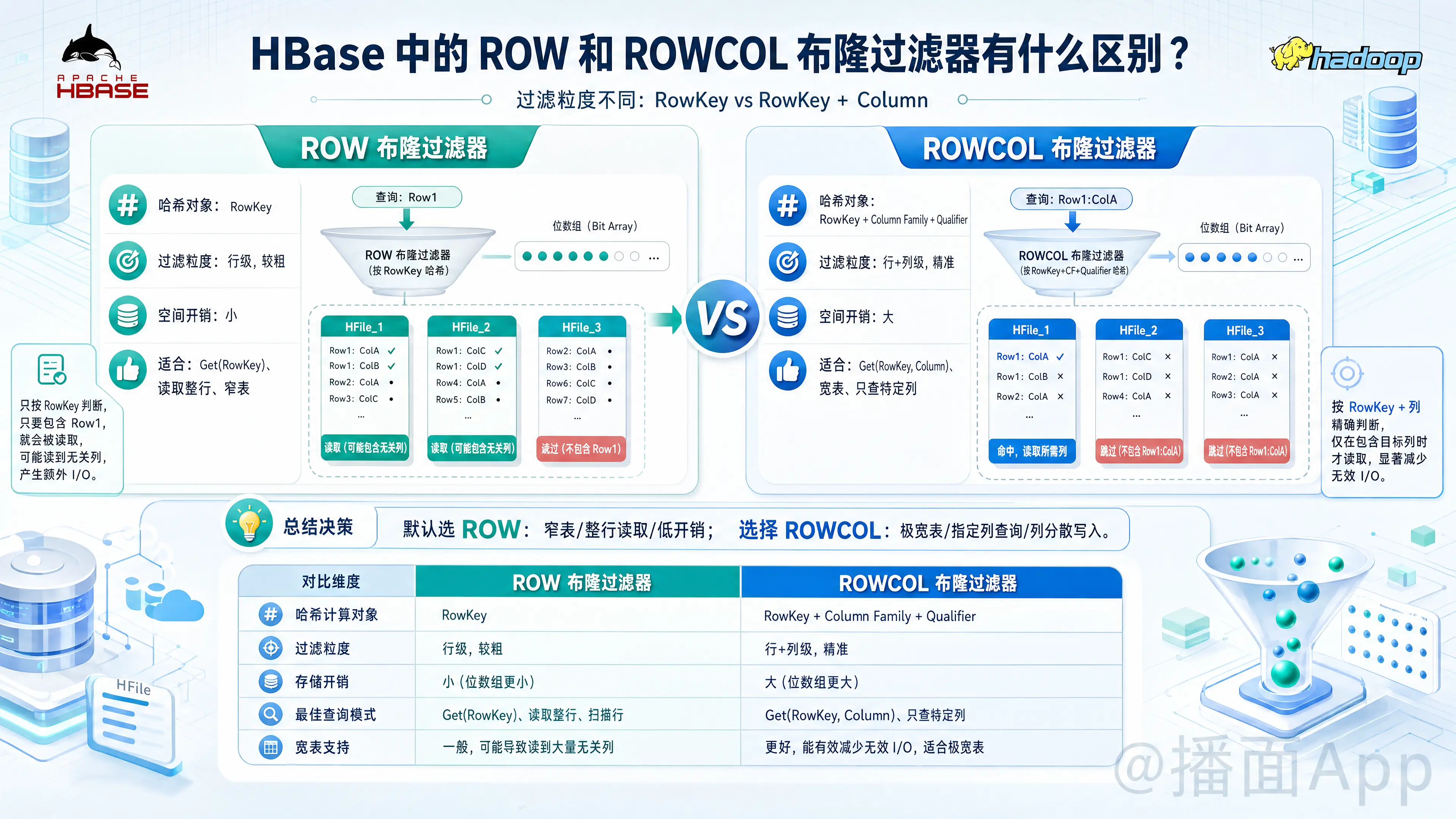
在 HBase 中,布隆过滤器(Bloom Filter)是一种以牺牲少量空间换取极高读取性能的数据结构。它的主要作用是在读取数据时,快速判断某个 HFile(底层的存储文件)中是否包含所请求的数据,从而避免不必要的磁盘 I/O。
HBase 提供了两种主要级别的布隆过滤器:ROW 和 ROWCOL。它们的核心区别在于过滤的粒度(计算哈希值的目标)不同。
以下是它们的详细区别和对比:
1. ROW 级别布隆过滤器
- 工作原理:它仅对 RowKey(行键) 进行哈希计算和存储。
- 作用:当你发起一个
Get请求查询某个 RowKey 时,HBase 会查询 HFile 的 ROW 布隆过滤器。如果过滤器回答“不存在”,HBase 就会直接跳过这个 HFile;如果回答“可能存在”,HBase 才会去读取这个 HFile 检查数据。 - 适用场景:
- 你的查询模式主要是按 RowKey 获取整行数据。
- 你的行(Row)相对较窄(包含的列不多)。
- 空间开销:较小。因为一个 HFile 中独立的 RowKey 数量相对较少。
2. ROWCOL 级别布隆过滤器
- 工作原理:它对 RowKey(行键)+ Column Family(列族)+ Column Qualifier(列限定符) 的组合进行哈希计算和存储。
- 作用:它不仅能判断 RowKey 是否存在,还能判断特定的某一行中的某一列是否存在于该 HFile 中。
- 适用场景:
- 你的行(Row)非常宽(包含成百上千甚至更多的列)。
- 你的查询模式通常是指定 RowKey 且指定获取其中的某几列(例如使用
Get.addColumn(family, qualifier))。 - 高频更新不同列的场景:例如,你今天写入了
Row1的ColA(生成了 HFile_1),明天写入了Row1的ColB(生成了 HFile_2)。如果你现在只查Row1的ColA:- 如果使用
ROW过滤器:HFile_1 和 HFile_2 都包含Row1,所以两个文件都会被读取。 - 如果使用
ROWCOL过滤器:HFile_2 的过滤器会告诉你它没有Row1+ColA,因此 HFile_2 会被完美跳过,节省了一半的 I/O。
- 如果使用
- 空间开销:较大。因为
RowKey + 列的组合数量远远大于单纯的 RowKey 数量,这会占用更多的内存(BlockCache)和磁盘空间。
总结对比表
| 特性 | ROW 布隆过滤器 |
ROWCOL 布隆过滤器 |
|---|---|---|
| 哈希计算对象 | RowKey | RowKey + Column Family + Column Qualifier |
| 过滤粒度 | 粗(行级别) | 细(行+列级别) |
| 存储空间/内存开销 | 小 | 大(甚至可能大出好几倍,取决于列的数量) |
| 最优查询模式 | Get(RowKey) 读取整行 |
Get(RowKey, Column) 读取特定行特定列 |
| 对宽表的支持 | 一般(可能导致无用的 HFile 读取) | 极好(精准过滤不包含目标列的文件) |
如何选择?
- 默认选择
ROW:如果你不知道选什么,或者你的表是常规的窄表,且经常读取整行,选择ROW是性价比最高的,它能用最小的内存开销过滤掉大量无效的 HFile 扫描。 - 选择
ROWCOL的条件:只有当你的表是极其宽的表(单行有很多列),并且你的业务逻辑绝大多数时候只请求特定的列,同时这些列的写入时间比较分散(分布在不同的 HFile 中),才应该开启ROWCOL。 - 不使用(
NONE):如果你的表主要是纯顺序扫描(Scan),或者数据量极小,或者内存极其紧张,可以选择不开启布隆过滤器,因为布隆过滤器对全表 Scan 几乎没有帮助。
建表语法示例:
plaintext
# 创建表,指定布隆过滤器类型为 ROW
create 'my_table', {NAME => 'cf', BLOOMFILTER => 'ROW'}
# 创建表,指定布隆过滤器类型为 ROWCOL
create 'my_table2', {NAME => 'cf', BLOOMFILTER => 'ROWCOL'}