 播面
播面 讲讲HBase 的物理存储结构(Region、Store、MemStore、StoreFile、HFile、WAL)
HBase 是一个基于 Hadoop HDFS 的分布式、面向列(准确地说是面向列族)的 NoSQL 数据库。为了实现海量数据的高并发读写,HBase 设计了一套非常精妙的物理存储结构。
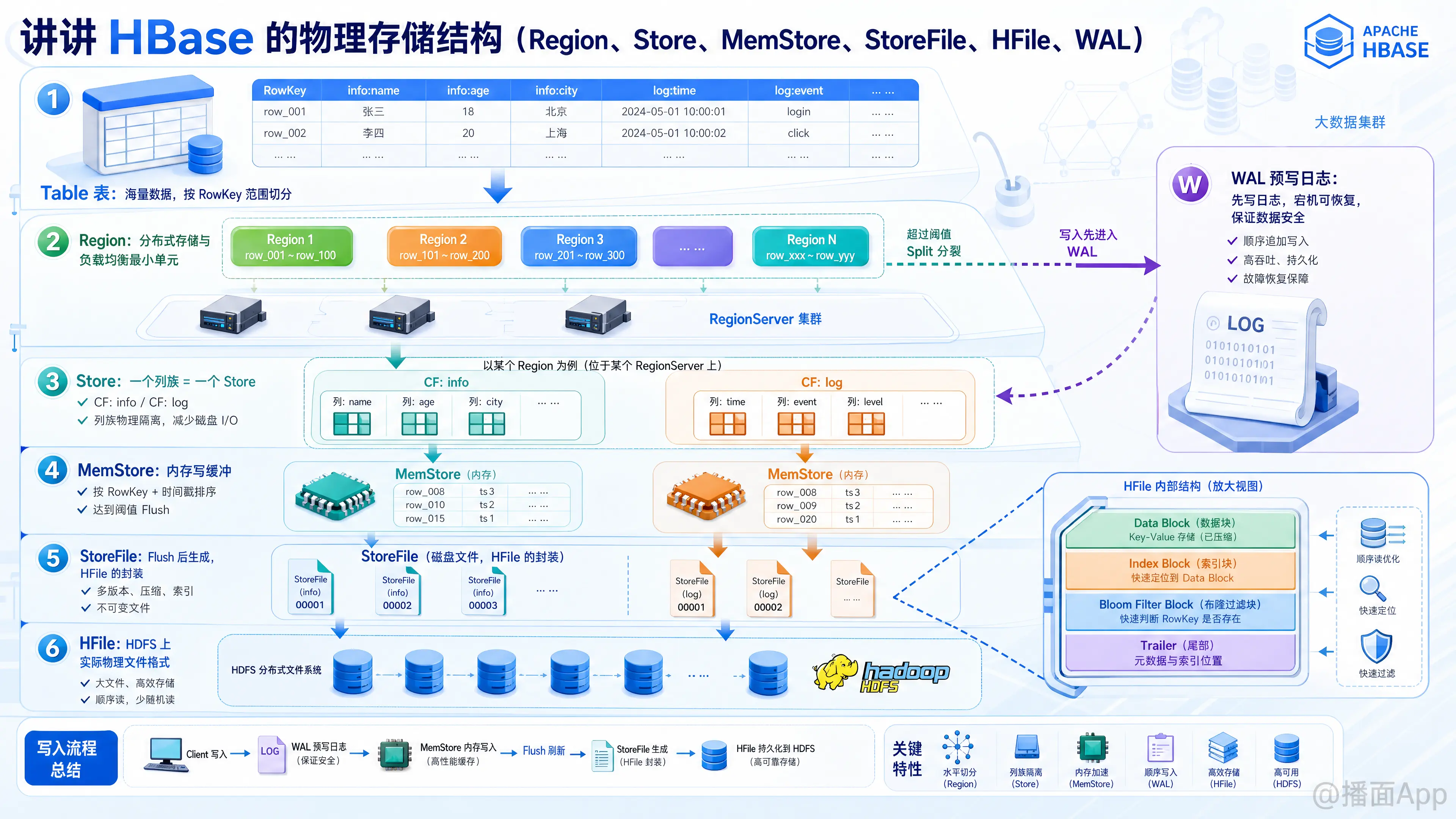
理解 HBase 的物理存储,最好的方法是自顶向下来看。它的整体层级关系如下:Table (表) -> Region (分区) -> Store (列族) -> MemStore (内存) + StoreFile (磁盘) -> HFile (HDFS文件)
另外还有一个独立的组件 WAL (预写日志) 用于保证数据安全。
下面为你详细拆解这些核心组件:
1. Region(数据分片 / 水平切分)
- 概念:Region 是 HBase 中分布式存储和负载均衡的最小单元。
- 原理:在 HBase 中,一张表(Table)在逻辑上可能非常大。为了分布式存储,HBase 会根据 RowKey(行键)的范围,将表水平切分成多个 Region。每个 Region 包含了一段连续的 RowKey(例如从
row_001到row_100)。 - 管理:Region 会被分配到集群中的不同 RegionServer 上提供服务。随着数据的写入,当一个 Region 的大小超过阈值时,它会发生分裂(Split),一分为二,从而分散存储压力。
2. Store(列族存储 / 垂直切分)
- 概念:Store 是 HBase 中按列族(Column Family)进行物理隔离的单元。
- 原理:在一个 Region 内部,数据并不是混在一起存储的,而是根据列族垂直划分的。一个列族对应一个 Store。
- 意义:这就是 HBase 被称为“列族数据库”的原因。如果你的查询只需要访问“基本信息”列族,HBase 就只会去读取对应的 Store,完全不会触碰“行为日志”列族的 Store,极大地减少了磁盘 I/O。
3. MemStore(内存缓存)
- 概念:MemStore 是每个 Store 内的内存写缓冲区。
- 原理:HBase 的写入操作不是直接写到磁盘的,而是先写入内存中的 MemStore。在 MemStore 中,数据会被自动按 RowKey、字典序以及时间戳进行排序。
- 作用:
- 极高的写入性能:写入内存即返回成功(配合 WAL)。
- 数据排序:HDFS 不支持随机修改,只能追加写。MemStore 在内存中将无序的写入整理成有序的数据,方便后续顺序刷写到磁盘。
- 刷写(Flush):当 MemStore 的大小达到阈值(如 128MB)时,HBase 会把 MemStore 中的数据生成一个新的 StoreFile 刷写到 HDFS 上。
4. StoreFile 与 HFile(磁盘存储)
- StoreFile:它是 HBase 内部的概念,是 MemStore 刷写到磁盘后的产物。一个 Store 中可以包含多个 StoreFile。它其实是对 HFile 的轻量级封装。
- HFile:它是 HBase 数据在 HDFS 上实际的物理文件格式。
- HFile 的内部结构(重点):
HFile 内部借鉴了 B+ 树的思想,由多个 Block(块)组成(默认 64KB):- Data Block(数据块):实际存储 Key-Value 数据的地方。
- Index Block(索引块):记录了 Data Block 的偏移量和 Key 范围,用于快速定位数据。
- Bloom Filter Block(布隆过滤器块):用于快速判断某个 RowKey 是否在当前这个 HFile 中,极大提升随机读的性能。
- Trailer(尾部):记录了 HFile 的元数据和索引的起始位置。
- 合并(Compaction):随着 MemStore 不断刷写,StoreFile/HFile 会越来越多,导致读取时需要跨多个文件,性能下降。HBase 会在后台执行 Compaction(分为 Minor 和 Major 两种),将多个小 HFile 合并成大 HFile,并清理掉过期和被删除的数据。
5. WAL (Write-Ahead Log / 预写日志)
- 概念:WAL 是一种灾备机制,存在于 HDFS 上。
- 解决的问题:因为 HBase 的数据是先写入内存(MemStore)的,如果此时 RegionServer 突然宕机(断电),内存中的数据就会丢失。
- 原理:在数据写入 MemStore 之前,HBase 会先把这次修改操作(Put/Delete)以顺序追加的方式写入到 WAL 文件中。只有 WAL 写入成功,才会更新 MemStore 并向客户端返回成功。
- 恢复:如果服务器宕机,HBase 在重启时会读取未被刷盘的 WAL 日志进行数据重放(Replay),从而恢复丢失的 MemStore 数据。
- 注意:通常一个 RegionServer 上的所有 Region 共享同一个 WAL 文件(为了保证顺序写,追求极致的 IO 性能)。
💡 总结:数据在 HBase 中的流转过程
为了让你更好地把它们串联起来,我们看看读写过程:
【写流程 (Write)】
- 客户端发送写请求。
- 数据首先追加写入 WAL(保证数据不丢)。
- 数据写入该列族对应的 MemStore(内存排序)。
- 客户端收到写入成功的响应(非常快)。
- 后台默默等待 MemStore 满了,将其 Flush 成为 HDFS 上的一个 HFile (StoreFile)。
【读流程 (Read)】
- 客户端发送读请求。
- HBase 首先查找 BlockCache(读缓存,存储经常访问的数据)。
- 如果没有,查找 MemStore(这里有最新写入、还没落盘的数据)。
- 如果还没有,则去查找磁盘上的 StoreFile (HFile)。
- 此时会利用 HFile 的 布隆过滤器 (Bloom Filter) 快速过滤掉不包含该 RowKey 的文件。
- 再利用 HFile 的 索引 快速定位到具体的 Data Block 进行读取。
- 将多个地方查到的数据按照时间戳进行合并,返回最新版本的数据给客户端。