 播面
播面 RocketMQ 是如何实现 Broker 高可用的?
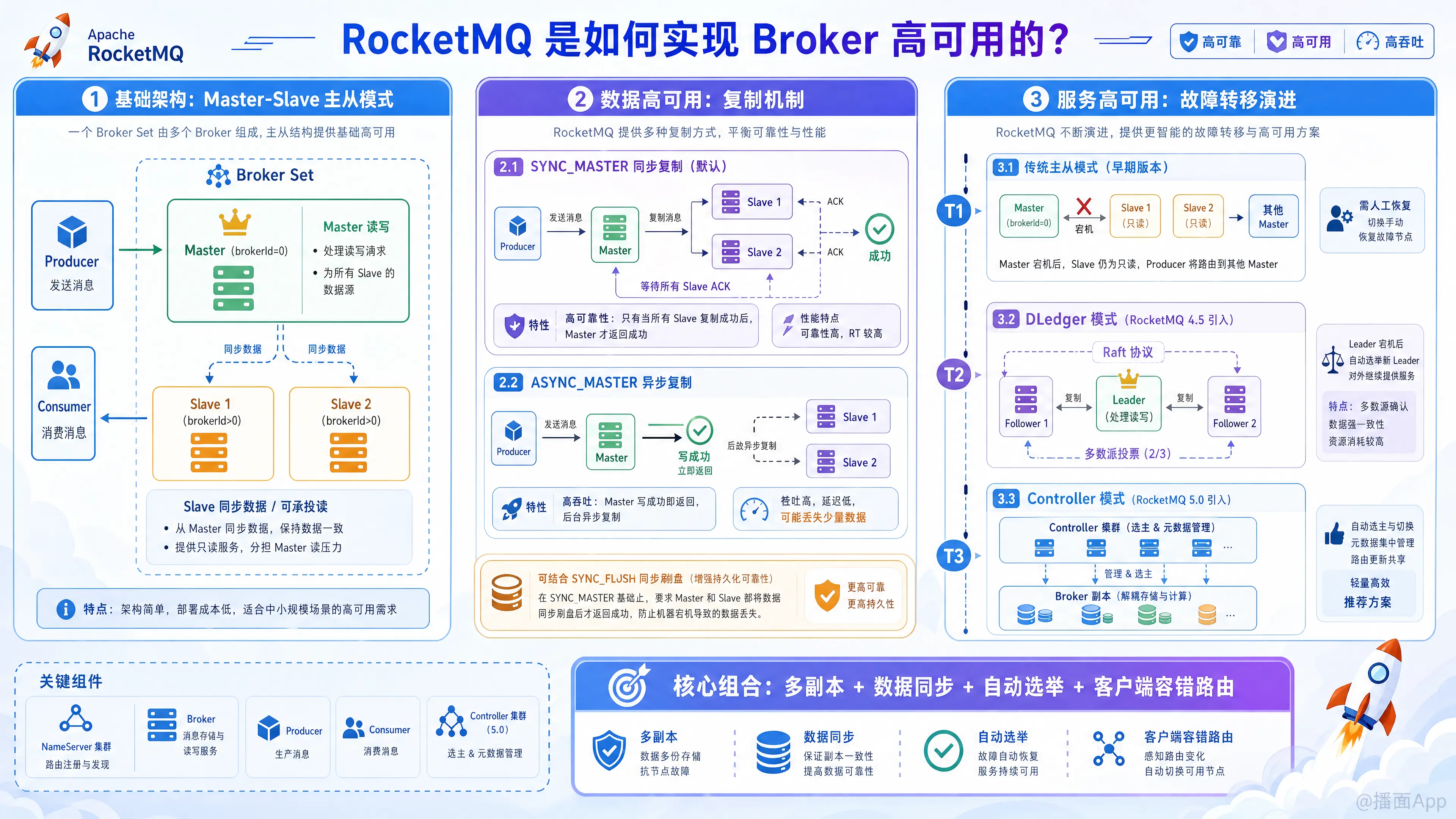
RocketMQ 实现 Broker 高可用(High Availability, HA)的核心思想是通过 多副本机制(主从架构)、数据同步、自动故障转移(选举) 以及 客户端的容错路由 相结合来实现的。
随着 RocketMQ 版本的演进,其高可用架构经历了几个重要的阶段。以下是 RocketMQ 实现 Broker 高可用的详细解析:
一、 基础架构:主从模式 (Master-Slave)
RocketMQ 的高可用基础是主从架构。一个 Broker 组(Broker Set)由相同的 brokerName 组成,通过 brokerId 区分角色:
- Master (brokerId = 0):负责处理客户端的读和写请求。
- Slave (brokerId > 0):主要负责从 Master 同步数据。当 Master 繁忙或宕机时,可以承担读请求,保证消费不中断。
二、 数据高可用:主从数据同步机制
要保证服务高可用,首先要保证数据不丢失。RocketMQ 提供了两种主从数据同步(复制)方式:
- 同步复制 (Sync Replication / SYNC_MASTER)
- 机制:Producer 发送消息到 Master,Master 收到消息后,必须等待 Slave 也把消息同步过去,才向 Producer 返回“发送成功”。
- 优点:数据安全性极高,Master 宕机也不会丢失数据。
- 缺点:性能相对较低,RT(响应时间)变长。
- 异步复制 (Async Replication / ASYNC_MASTER)
- 机制:Producer 发送消息到 Master,Master 写成功后直接返回“发送成功”,然后后台线程异步将数据复制到 Slave。
- 优点:吞吐量大,性能极高。
- 缺点:如果 Master 突然宕机且磁盘损坏,尚未同步到 Slave 的少量数据可能会丢失。
*(注:为了达到极致的可靠性,通常会将同步复制与**同步刷盘 (SYNC_FLUSH)*结合使用。)
三、 服务高可用:故障转移与自动选举 (核心演进)
当 Master Broker 宕机时,如何恢复“写”能力是高可用的关键。RocketMQ 的故障转移机制经历了三个主要阶段:
1. 传统主从模式(RocketMQ 4.5 以前)
- 机制:Master 宕机后,Slave 只能提供读服务,不能自动变成 Master。此时该 Broker 组无法处理“写”请求。
- 如何保证高可用:依靠集群部署(多 Master 多 Slave)。当某个 Master 宕机时,Producer 无法写入该节点,但客户端(Producer)的路由容错机制会自动将消息发送到其他正常的 Master 节点。
- 缺点:需要人工介入才能恢复宕机的 Master,无法实现单组 Broker 的自动主从切换。
2. DLedger 模式(RocketMQ 4.5 引入)
为了解决无法自动主从切换的问题,RocketMQ 4.5 引入了基于 Raft 协议的 DLedger 存储引擎。
- 机制:一个 Broker 组至少需要 3 个节点(1 个 Leader,2 个 Follower)。DLedger 接管了 CommitLog 的写入。
- 自动选举:当 Leader(即 Master)宕机后,剩下的节点会通过 Raft 协议在几秒钟内自动选举出新的 Leader,继续提供读写服务。
- 缺点:
- 资源消耗大(每组至少 3 个节点)。
- 性能有一定损耗(Raft 协议需要多数派确认)。
- 存储与共识算法强耦合。
3. Controller 模式(RocketMQ 5.0 引入,目前的最优解)
RocketMQ 5.0 借鉴了 Kafka KRaft 的思想,将“共识选举”与“数据存储”解耦,引入了 Controller 组件。
- 机制:Controller 是一个基于 Raft 的轻量级独立组件(可以内嵌在 NameServer 中,也可以独立部署)。它负责管理集群的元数据和 Broker 的状态。
- 自动主从切换:Broker 依然保持传统的一主一从(或一主多从)的轻量级架构(只需要 2 个节点)。当 Controller 探测到 Master 宕机后,会强制发起状态机切换,将拥有最新数据的 Slave 提升为 Master。
- 优点:
- 降低了成本(2 个节点即可实现自动 Failover,无需 DLedger 的 3 节点)。
- 提升了性能(数据同步退回到原生的主从同步,不需要走 Raft 的多数派复制)。
- 架构更清晰(控制面与数据面分离)。
四、 客户端配合:路由容错机制
Broker 的高可用离不开客户端和 NameServer 的配合:
- NameServer 的路由剔除:
- Broker 每 30 秒向所有 NameServer 发送心跳。
- 如果 NameServer 连续 120 秒没收到心跳,就会将该 Broker 从路由表中剔除。
- Producer 的发送重试与故障延迟机制(SendLatencyFaultEnable):
- 重试:Producer 发送消息失败时,默认会重试(通常重试 2 次),并会自动选择另外一个 Broker 进行发送,避开宕机的节点。
- 故障延迟:开启
sendLatencyFaultEnable = true后,如果 Producer 发现往某个 Broker 发送消息耗时过长或失败,会在接下来的一段时间内(如几分钟)自动隔离该 Broker,不再往该节点路由请求,从而避免雪崩。
- Consumer 的自动切换:
- 当 Master 宕机或 Master 负载过高时,Broker 会在拉取消息的响应中告诉 Consumer:“下次请从 Slave 拉取”。
- Consumer 会自动无缝切换到从 Slave 获取数据,保证消费链路不断。
总结
RocketMQ 实现 Broker 高可用的完整链路如下:
- 数据层面:通过
同步复制/异步复制保证主从之间的数据备份。 - 服务层面(控制面):
- 5.0 之前依赖多 Master 架构的客户端重试,或 DLedger (Raft) 的 3 节点自动选举。
- 5.0 之后依赖 Controller 组件 管理状态,实现 2 节点下轻量级的自动主从切换(Failover)。
- 客户端层面:Producer 的 重试+故障延迟隔离 保障写入高可用;Consumer 的 主挂读从 保障消费高可用。