 播面
播面 RocketMQ 中,基于 Dledger 的集群是如何实现自动选主和元数据强一致性的?
在 RocketMQ 中,引入 DLedger 的核心目的就是为了解决传统 Master-Slave 架构下无法自动故障恢复(自动选主)以及主从切换时可能导致的数据丢失(强一致性)问题。
DLedger 是一个基于 Raft 共识算法 的分布式日志存储组件。RocketMQ 将其作为底层 CommitLog 的替代品。
基于 DLedger 的 RocketMQ 集群实现自动选主和元数据(及消息数据)强一致性的核心机制,完全建立在 Raft 算法之上。具体实现原理如下:
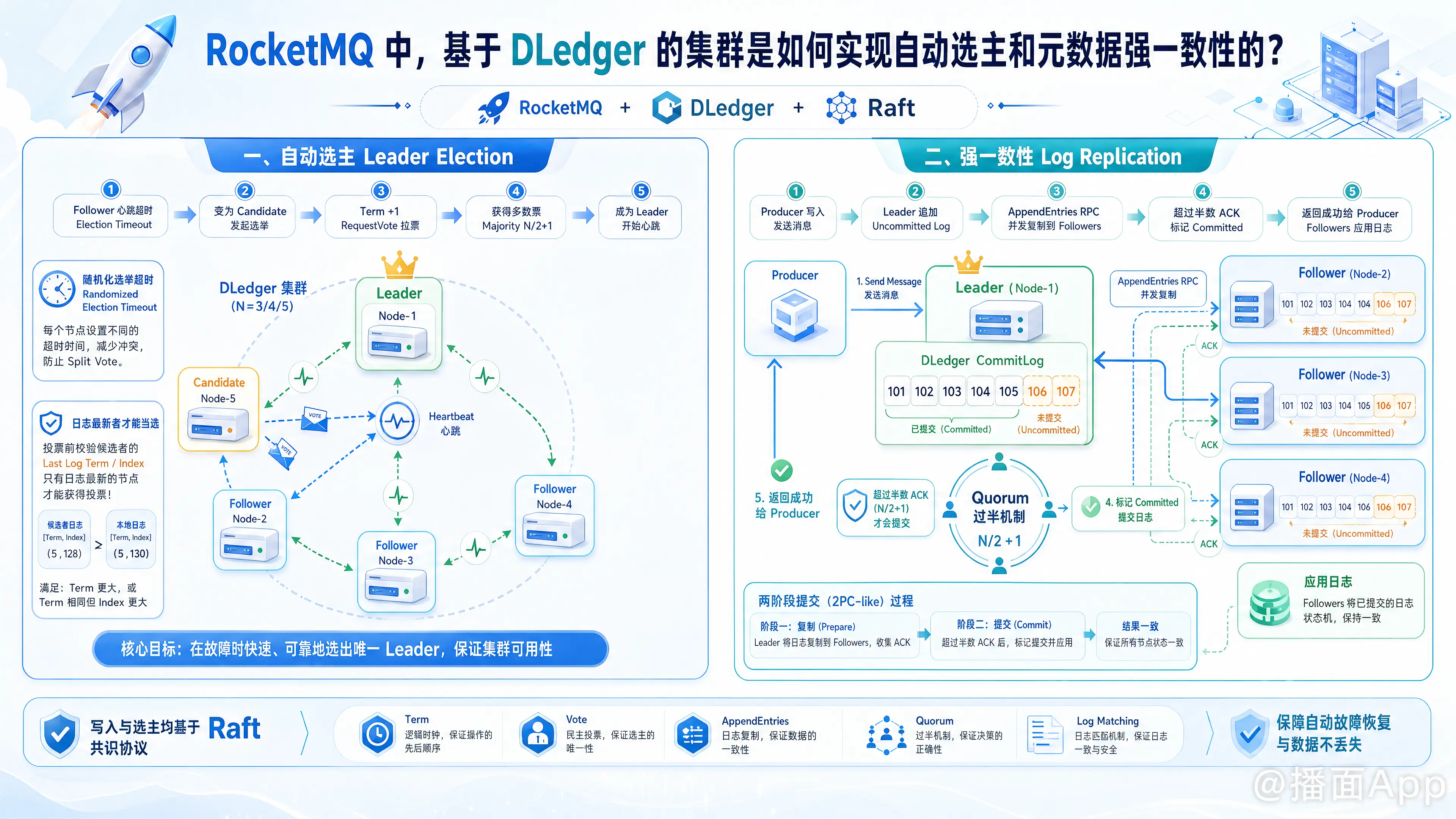
一、 如何实现自动选主(Leader Election)
在 DLedger 集群中,节点有三种角色:Leader(领导者)、Follower(跟随者)、Candidate(候选者)。选主过程是完全自动的。
1. 触发选主的条件
- 集群初始化启动:刚启动时,所有节点都是 Follower。
- Leader 宕机或网络隔离:Follower 在一个预设的超时时间(Election Timeout)内没有收到来自 Leader 的心跳(Heartbeat)。
2. 自动选主流程
- 超时转变为候选者:当某个 Follower 的心跳计时器超时后,它会将自己的状态切换为 Candidate。
- 增加任期(Term)并拉票:Candidate 会将当前的“任期号”(Term,一个单调递增的整数,代表一届领导者的生命周期)加 1,先给自己投一票,然后向集群内的其他节点发送
RequestVote(请求投票)RPC。 - 其他节点投票逻辑:
- 每个节点在一个任期内只能投一票(先到先得)。
- 核心安全校验(Log Matching Check):其他节点在决定是否投票给该 Candidate 时,会检查 Candidate 的日志是否比自己的“更新”(Up-to-date)。具体比较依据是:最后一条日志的 Term 越大越新;如果 Term 相同,则日志索引(Index)越大越新。只有 Candidate 的日志至少和自己一样新,才会给它投票。(这保证了拥有最全数据的节点才能成为 Leader)。
- 成为 Leader(Majority 机制):如果该 Candidate 获得了集群中 超过半数(N/2 + 1) 节点的选票(Quorum),它就会正式成为新的 Leader。
- 广播心跳巩固地位:成为 Leader 后,它会立刻向所有节点发送心跳消息(空的
AppendEntriesRPC),以阻止其他节点发起新的选举。
3. 避免选票瓜分(Split Vote)
如果多个 Follower 同时超时并成为 Candidate,可能会导致选票平局,没人能拿到过半选票。DLedger/Raft 通过随机化选举超时时间(Randomized Election Timeout)来解决,确保总会有某个节点先超时并发起选举。
二、 如何实现数据的强一致性(Log Replication)
在 RocketMQ-DLedger 中,无论是元数据还是消息数据,写入过程都必须遵循 Raft 的日志复制(Log Replication)机制。这是一种类似“两阶段提交(2PC)”的过程,依赖过半机制(Quorum)来保证强一致性。
1. 日志复制流程(AppendEntries)
当 Producer 发送一条消息(或者集群发生元数据变更)到 Leader 时,流程如下:
- 追加本地日志(Uncommitted):Leader 先将消息作为一条 Log Entry 追加到自己的 DLedger CommitLog 中,此时该日志状态为“未提交”(Uncommitted)。
- 广播日志(AppendEntries RPC):Leader 并发地向所有 Follower 发送
AppendEntries请求,携带这条新日志。 - Follower 追加并回复:Follower 收到日志后,执行一致性检查(检查前一条日志的 Index 和 Term 是否匹配)。如果匹配,则追加到本地日志,并向 Leader 返回 ACK。
- Leader 提交日志(Committed):当 Leader 收到 过半数节点(包括自己) 的成功 ACK 后,认为该日志已达成共识,将其状态标记为“已提交”(Committed),并应用(Apply)到状态机(例如向外返回写入成功给 Producer)。
- 通知 Follower 提交:在随后的心跳或下一次
AppendEntries请求中,Leader 会带上最新的CommittedIndex。Follower 收到后,也会将本地的日志标记为已提交,并对外可见。
2. 强一致性的保证机制
- 过半确认(Quorum Write):一条消息必须写入大多数节点才算成功。即使 Leader 马上宕机,新选举出的 Leader(根据前面提到的选主规则)必定包含这条已提交的消息日志,绝对不会丢失。
- Leader 强制覆盖机制(Log Matching):如果某个 Follower 因为网络原因错过了几条消息,或者之前属于旧 Leader 的未提交日志与新 Leader 发生冲突。Raft 算法规定:一切以 Leader 的日志为准。Leader 会找到该 Follower 与自己日志分叉的那个点(NextIndex),然后强制覆盖 Follower 冲突的日志,确保集群数据完全一致。
三、 总结:DLedger 对 RocketMQ 的改造
传统的 RocketMQ(主从同步或异步刷盘)在极端情况下会面临可用性和一致性的权衡:
- 异步复制:主挂了,从没有最新数据,直接提拔从节点会丢数据。
- 同步双写:主挂了需要人工介入切换。
引入 DLedger 后:
- 接管底层存储:DLedger 完全接管了原来的
CommitLog,RocketMQ 的 Broker 依然存在,但其角色(Master/Slave)是由底层的 DLedger 状态决定的。DLedger 是 Leader,Broker 就是 Master。 - 牺牲部分性能换取高可用与强一致:因为每次写入都需要经过网络将日志同步到过半节点(如 3 节点集群需要至少写 2 节点),其写入延迟会比原生的异步刷盘高,吞吐量有一定下降。
- 容灾能力提升:在 3 节点的 DLedger 集群中,允许任意 1 个节点宕机,集群依然能够自动选主并对外提供强一致的读写服务(RPO = 0,RTO < 几秒到十几秒)。