 播面
播面 RocketMQ的NameServer 是如何感知 Broker 的存活状态的?
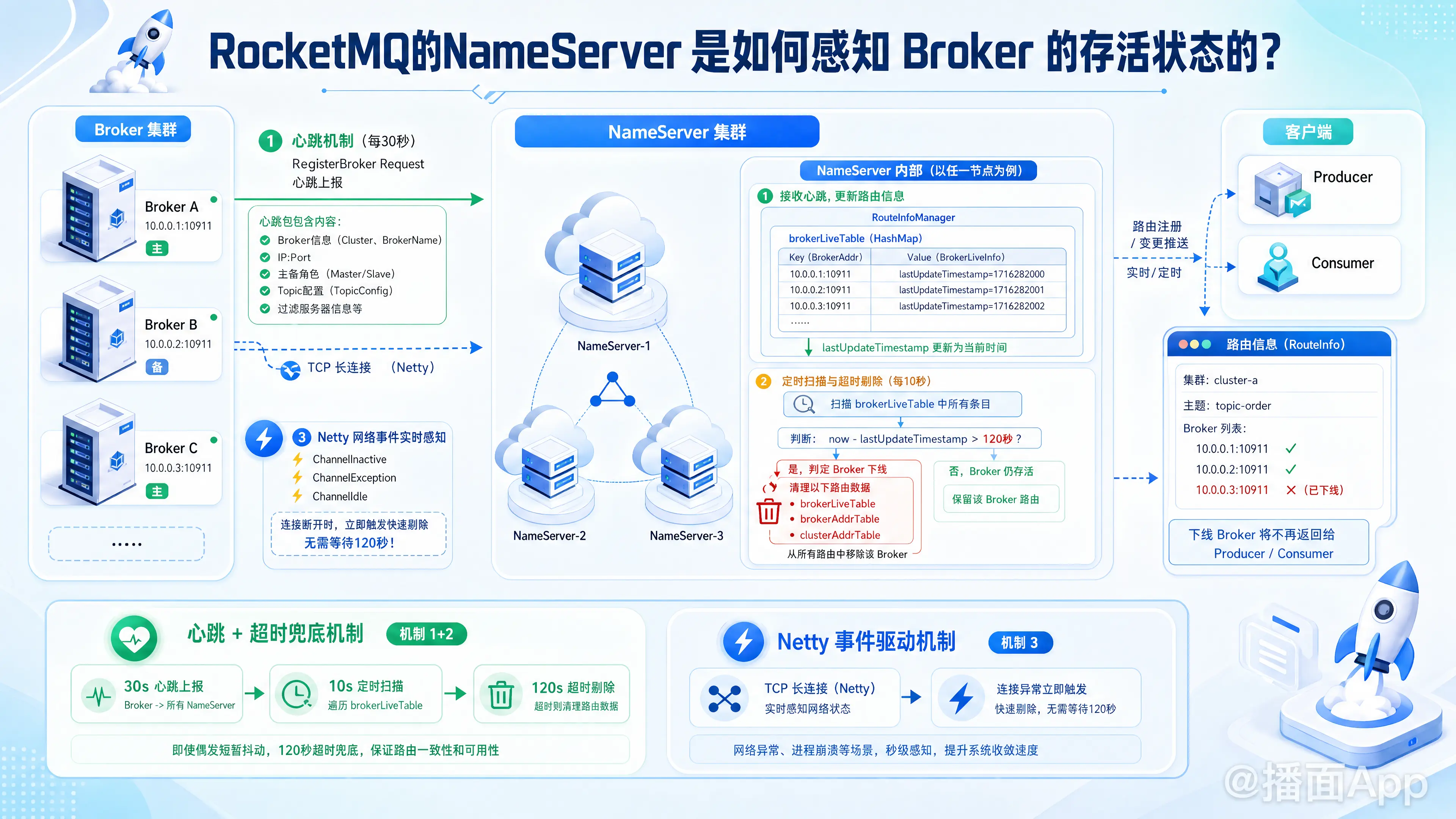
RocketMQ 的 NameServer 感知 Broker 存活状态主要依赖于 心跳机制(定时上报与超时剔除) 以及 底层网络事件驱动(Netty 长连接状态异常) 两个层面的配合。
具体来说,整个过程可以分为以下几个核心环节:
1. Broker 定时发送心跳(主动上报)
- 注册与心跳发送:Broker 在启动时,会向所有的 NameServer 节点发起注册请求。启动成功后,Broker 会开启一个定时任务,默认每隔 30 秒向集群中所有的 NameServer 发送心跳包(RegisterBroker Request)。
- 心跳内容:心跳包中不仅包含 Broker 的基础信息(如 Broker 名称、集群名称、IP 地址、主备角色等),还会携带该 Broker 上所有的 Topic 配置信息(如果 Topic 较多,会对数据进行压缩)。
2. NameServer 接收并维护状态(更新时间戳)
- 核心数据结构:NameServer 内部有一个非常核心的类叫
RouteInfoManager,里面维护了一个名为brokerLiveTable的哈希表(HashMap)。- Key:Broker 的地址(IP:Port)。
- Value:
BrokerLiveInfo对象,里面包含了一个至关重要的属性 ——lastUpdateTimestamp(最后一次收到心跳的时间戳)。
- 更新时间戳:每当 NameServer 收到 Broker 发来的心跳包时,就会更新
brokerLiveTable中对应 Broker 的lastUpdateTimestamp为当前系统时间。
3. NameServer 定时扫描与超时剔除(兜底机制)
- 定时扫描:NameServer 自身也会启动一个定时任务,默认每隔 10 秒执行一次扫描。
- 剔除逻辑:它会遍历
brokerLiveTable,检查每一个 Broker 的lastUpdateTimestamp。 - 判定死亡:如果 NameServer 发现当前时间减去
lastUpdateTimestamp的值 大于 120 秒(即连续两分钟没收到该 Broker 的心跳),NameServer 就会认为该 Broker 已经宕机(下线)。 - 清理路由:一旦判定 Broker 死亡,NameServer 会关闭与该 Broker 的连接,并将其从
brokerLiveTable、brokerAddrTable、clusterAddrTable等所有路由表中剔除。这样,后续的 Producer 和 Consumer 就无法再获取到该 Broker 的路由信息了。
4. 基于 Netty 的网络事件监听(实时感知)
除了上述的定时扫描机制,RocketMQ 还利用了底层通信框架 Netty 的长连接特性来实现更实时的感知:
- NameServer 和 Broker 之间是通过 Netty 建立的 TCP 长连接。
- NameServer 会监听 Netty Channel 的状态事件(如
ChannelInactive连接断开、ChannelException发生异常、ChannelIdle状态空闲等)。 - 快速剔除:如果 Broker 进程非正常退出(比如被
kill -9杀掉)或者网络突然中断导致 TCP 连接断开,NameServer 的 Netty 监听器会立刻捕获到连接断开事件,不需要等待 120 秒超时,而是会立刻触发路由清理逻辑,将该 Broker 从路由表中移除。
总结
NameServer 感知 Broker 存活主要靠两条腿走路:
- 正常/网络拥塞情况(心跳+超时):Broker 每 30s 发心跳,NameServer 每 10s 查一次,超过 120s 没收到心跳就踢掉。
- 异常断开情况(网络事件驱动):Broker 进程奔溃导致 TCP 连接断开,NameServer 底层 Netty 立刻触发
channelInactive事件,瞬间将 Broker 剔除,保证了路由信息的实时性。