 播面
播面 Netty 内存分配算法中用到的 Jemalloc 思想及其内部核心结构
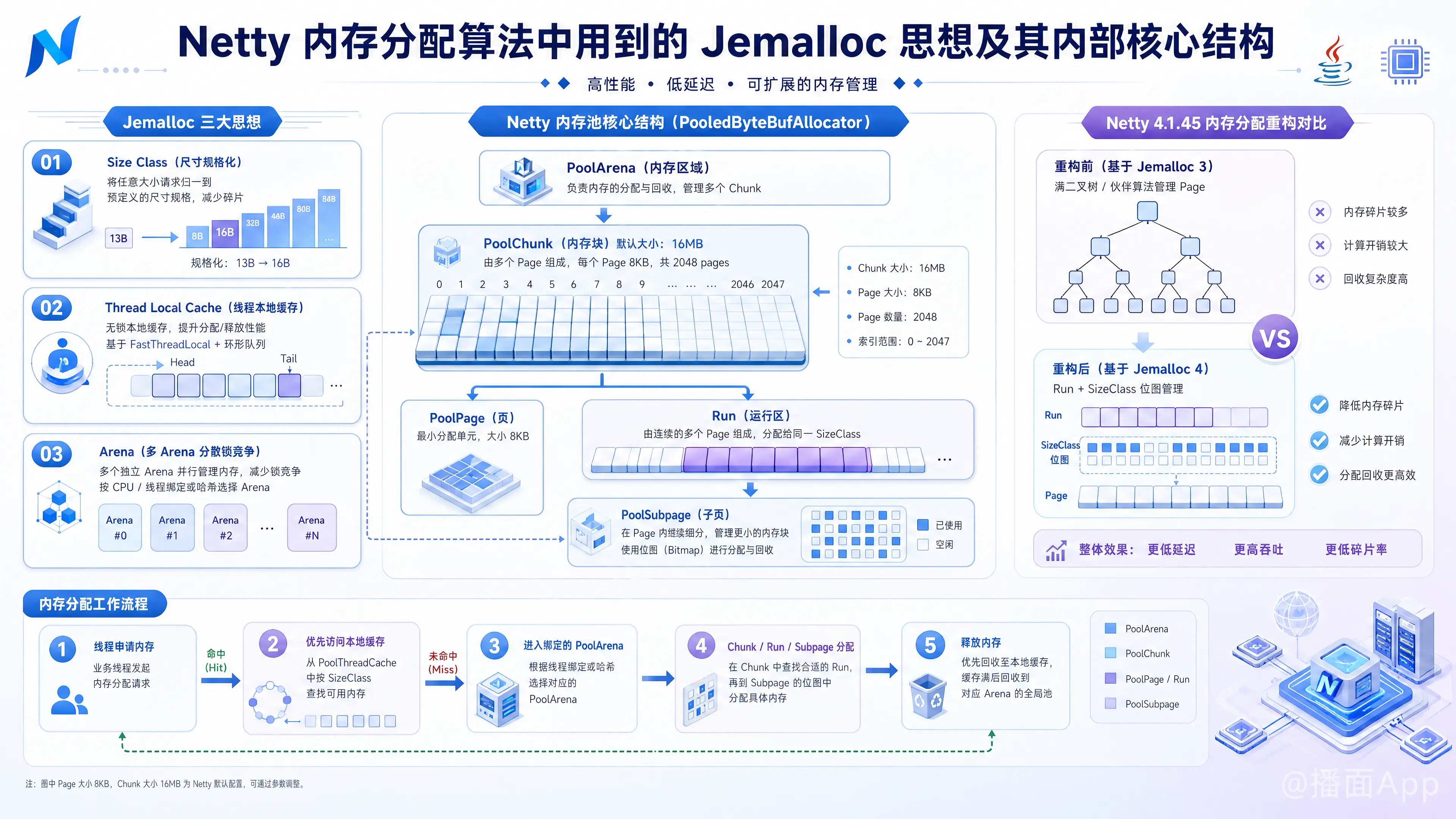
Netty 的内存管理是其实现高性能、低延迟的核心组件之一。为了解决 Java 原生 ByteBuffer 分配释放昂贵(尤其是 Direct Buffer)以及内存碎片化的问题,Netty 引入了基于 Jemalloc 算法思想的内存池(PooledByteBufAllocator)。
需要特别注意的是,Netty 的内存管理在 4.1.45 版本发生过一次重大重构:
- 重构前:参考 Jemalloc 3,使用满二叉树(伙伴算法)管理 Chunk 中的 Page。
- 重构后:参考 Jemalloc 4,移除了二叉树,改用 Run(连续的 Page 集合) 和基于 SizeClass 的位图管理,进一步降低了内存碎片和计算开销。
以下将围绕 Netty 借鉴的 Jemalloc 核心思想及其内部核心数据结构进行深度解析。
一、 借鉴的 Jemalloc 核心思想
Jemalloc 的设计初衷是为了在多线程环境下提供极其优异的内存分配性能,Netty 主要借鉴了其以下三个核心思想:
- Size Class(规格化内存)
将请求的内存大小向上取整到特定的固定规格(Size Class),而不是按需分配任意大小。例如请求 13 字节,会分配 16 字节。这大大简化了内存管理,并降低了外部碎片,尽管会产生一定的内部碎片。 - Thread Local Cache(线程本地缓存)
无锁化分配的核心。每个线程都有自己专属的内存缓存(TLAB思想)。当线程申请内存时,优先从本地缓存获取;释放时,优先放回本地缓存。这极大减少了多线程并发申请内存时产生的锁竞争。 - Arena(多内存阵列隔离)
对于无法在线程缓存中满足的分配,Jemalloc 采用多个 Arena(内存管理区)。每个 Arena 独立管理一部分内存,线程被均匀绑定到不同的 Arena 上,从而将全局的锁竞争分散到多个 Arena 内部。
二、 Netty 内存池的核心内部结构
Netty 的内存池由上到下呈现严格的层级结构:PoolArena -> PoolChunk -> PoolPage (Run) -> PoolSubpage。配合线程缓存 PoolThreadCache 共同工作。
1. PoolArena (内存阵列)
- 作用:Netty 内存管理的顶级结构。为了降低并发锁竞争,Netty 默认会创建多个 PoolArena(通常与 CPU 核心数 * 2 相关)。
- 工作机制:当一个新的线程第一次申请内存时,Netty 会以轮询(Round-Robin)或最少使用的方式为其绑定一个 PoolArena。此后,该线程的内存分配都在这个 Arena 中进行。
- 结构:包含用于不同利用率 Chunk 的链表(如
q000,q025,q050,q075,q100等),用于动态管理 Chunk 的生命周期。
2. PoolThreadCache (线程本地缓存)
- 作用:基于
FastThreadLocal实现。每个线程拥有一个,用于缓存刚释放的内存块,下次同等大小的分配直接从这里无锁获取。 - 结构:内部维护了多个
MemoryRegionCache数组(分为 Small、Normal 不同规格)。每个 Cache 是一个无锁环形队列,存放被释放的内存指针。 - 淘汰机制:为了防止内存泄漏,它有定期清理机制(基于分配频率阈值,如果某些缓存在一定分配周期内没被使用,会被释放回全局池)。
3. PoolChunk (内存块)
- 作用:Netty 向操作系统(或 JVM)申请内存的基本单位。默认大小为 16MB。
- Jemalloc 4 结构(新版 Netty):
- 一个 16MB 的 Chunk 被划分为 2048 个 Page(默认 Page 大小为 8KB)。
- Run:若干个连续的 Page 组成一个 Run。新版放弃了二叉树,而是通过基于
SizeClasses预先计算好的步长,利用 LongPriorityQueue 和各种位图(Bitmap)来记录哪些 Run 是空闲的。 - 这种设计更容易实现 Page 的合并(Coalescing),极大减少了内存碎片。
4. PoolSubpage (小内存页)
- 作用:当用户申请的内存小于 8KB(一个 Page)时,直接分配一个 Page 太浪费。Netty 会将一个 Page 划分为相等大小的微小块(如 16B, 32B, 64B...),这就是 Subpage。
- 工作机制:
- 假如申请 32B 内存,Netty 会在 Chunk 中分配一个 8KB 的 Page,将其标记为 Subpage,并切割成 256 个 32B 的小格子。
- 利用内部的
bitmap(用long数组表示)来记录这 256 个格子中哪些被占用了。 - Arena 中维护了
PoolSubpage的数组,按规格将这些 Subpage 串成双向链表,方便快速查找。
三、 内存规格分类 (Size Classes)
Netty 根据申请内存的大小,将其严格分类(新版取消了 Tiny,合并入 Small):
- Small(小内存):
< 8KB。在PoolSubpage中分配。 - Normal(普通内存):
8KB <= size <= 16MB。在PoolChunk中通过分配若干个连续的 Page (Run) 来满足。 - Huge(大内存):
> 16MB。超出 Chunk 大小,不经过内存池,直接向 OS/JVM 申请,并在释放时直接销毁。
四、 核心工作流程
1. 分配流程 (Allocation)
假设线程 T 请求分配 N 字节的内存:
- 规格化:将
N向上对齐到最近的 Size Class(例如,请求 13B 变为 16B)。 - 查线程缓存 (Fast Path):
- 从当前线程的
PoolThreadCache中查找对应规格的队列。 - 如果有空闲内存,直接弹出返回。(全程无锁)
- 从当前线程的
- Arena 分配 (Slow Path):
- 如果缓存没有,则向线程绑定的
PoolArena申请。(此处开始需要加锁同步) - 如果是 Small 内存:尝试从 Arena 的
PoolSubpage链表中找有空闲格子的 Subpage 分配;若没有,则去 Chunk 中申请一个 Page 变成 Subpage 再分配。 - 如果是 Normal 内存:在 Arena 现有的
PoolChunk的链表(如 q050, q025)中寻找,通过位图找到一段连续的 Page (Run) 分配。
- 如果缓存没有,则向线程绑定的
- 创建新 Chunk:
- 如果现有的所有 Chunk 都满了,Netty 会向系统申请一个新的 16MB Chunk,放入 Arena 中,然后再执行分配。
2. 释放流程 (Deallocation)
- 放入线程缓存:内存释放时,判断所属的规格,优先将其放入当前释放线程的
PoolThreadCache队列中。 - 缓存满或清理:如果线程缓存已满,或者触发了整理机制,内存将被真正还给
PoolChunk。 - 合并内存:在还给 Chunk 时,Netty 会检查相邻的 Run(Page集合)是否也是空闲的,如果是,则合并成更大的连续空间,防止产生外部碎片。
- Chunk 回收:如果一个 Chunk 内存完全释放(利用率为 0),且 Arena 的 Chunk 链表策略允许,该 Chunk 会被销毁,内存交还给操作系统。
五、 总结
Netty 的内存池是 Jemalloc 思想的 Java 完美复刻与深度优化。它的核心就在于:
- 用空间换时间:通过预先分配大块内存(Chunk),避免频繁系统调用。
- 层层隔离锁:利用 ThreadLocal 缓存拦截掉 80% 以上的分配请求,剩下的请求被分散到多个 Arena 中,将多线程竞争降到最低。
- 精细化管理:通过 SizeClass、Run 和 Subpage 的位图操作,在内存对齐、降低碎片与高效率查找之间取得了极佳的平衡。